

Evolution of a complex disease resistance gene cluster in diploid Phaseolus and tetraploid Glycine
- PMID: 22457424
- PMCID: PMC3375969
- DOI: 10.1104/pp.112.195040
Evolution of a complex disease resistance gene cluster in diploid Phaseolus and tetraploid Glycine
Abstract
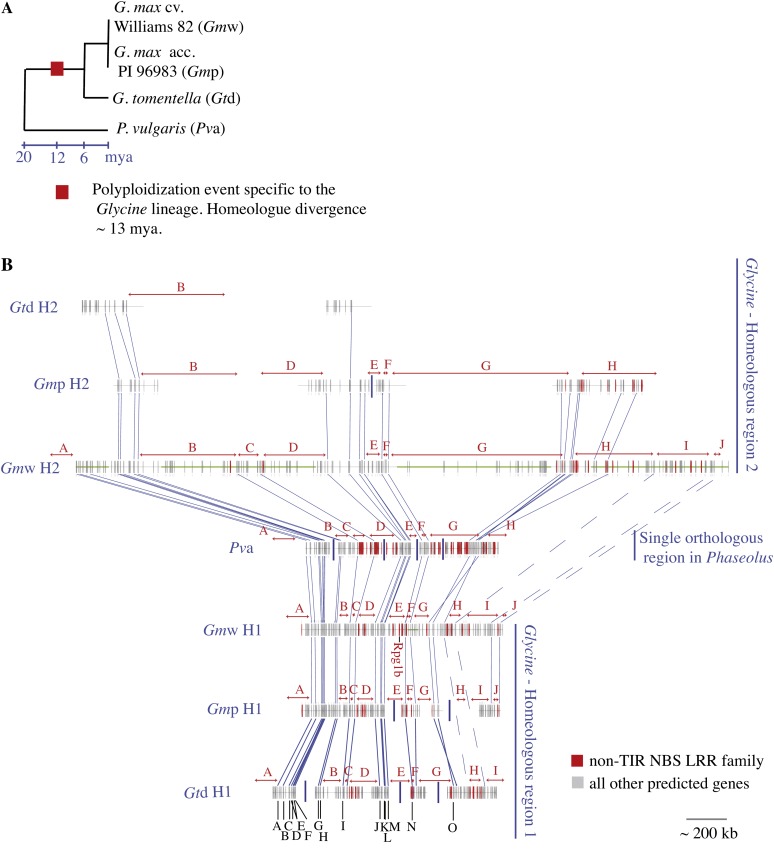
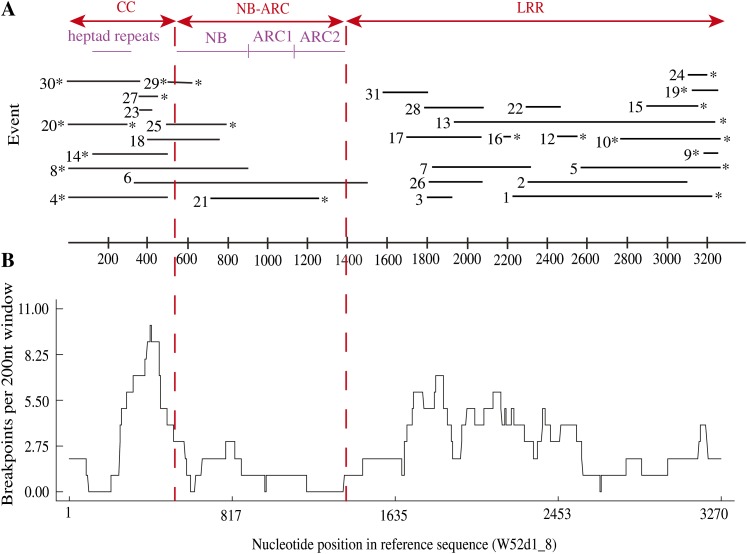
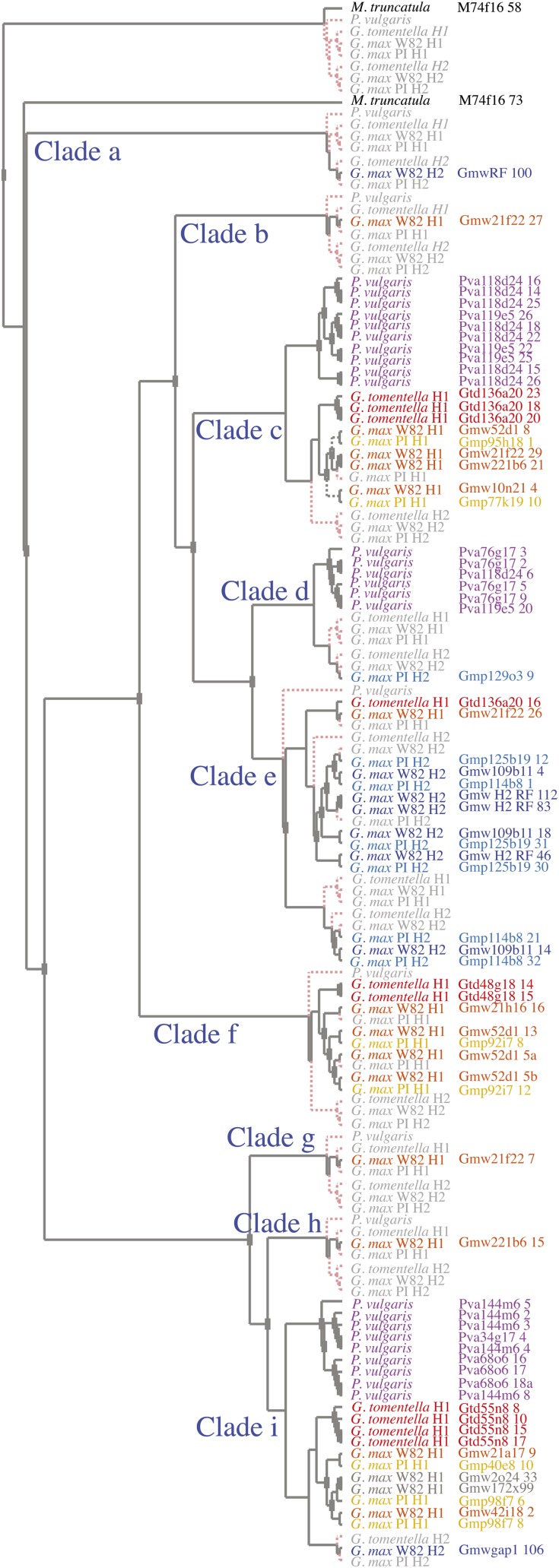
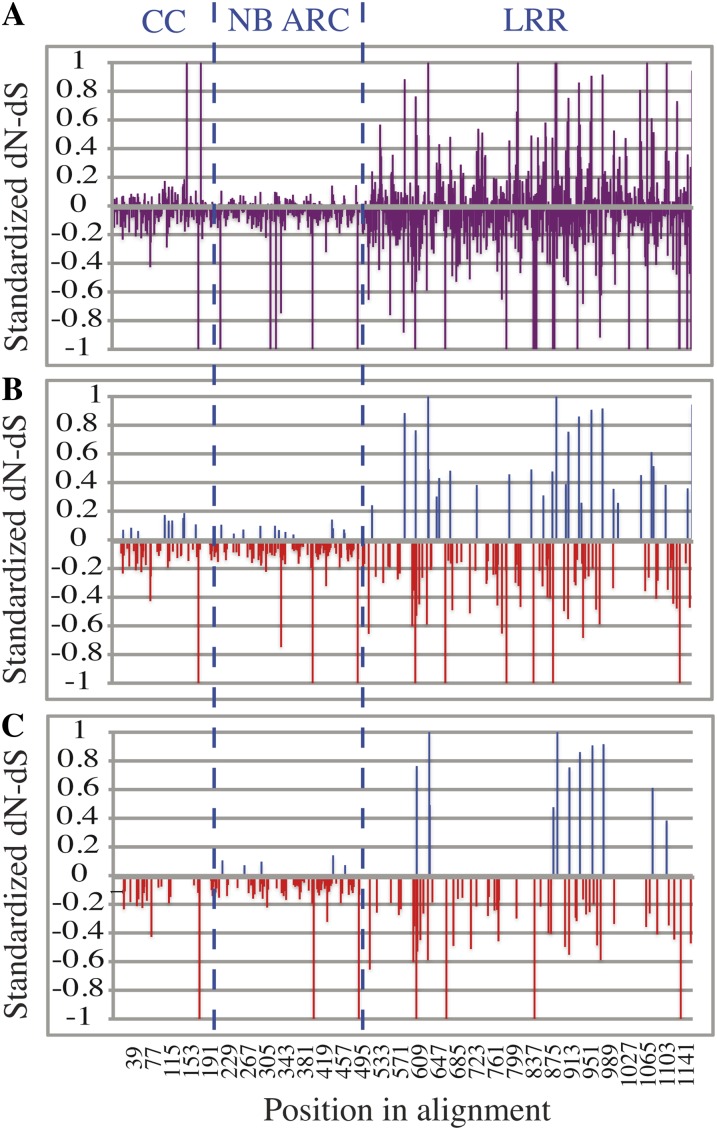
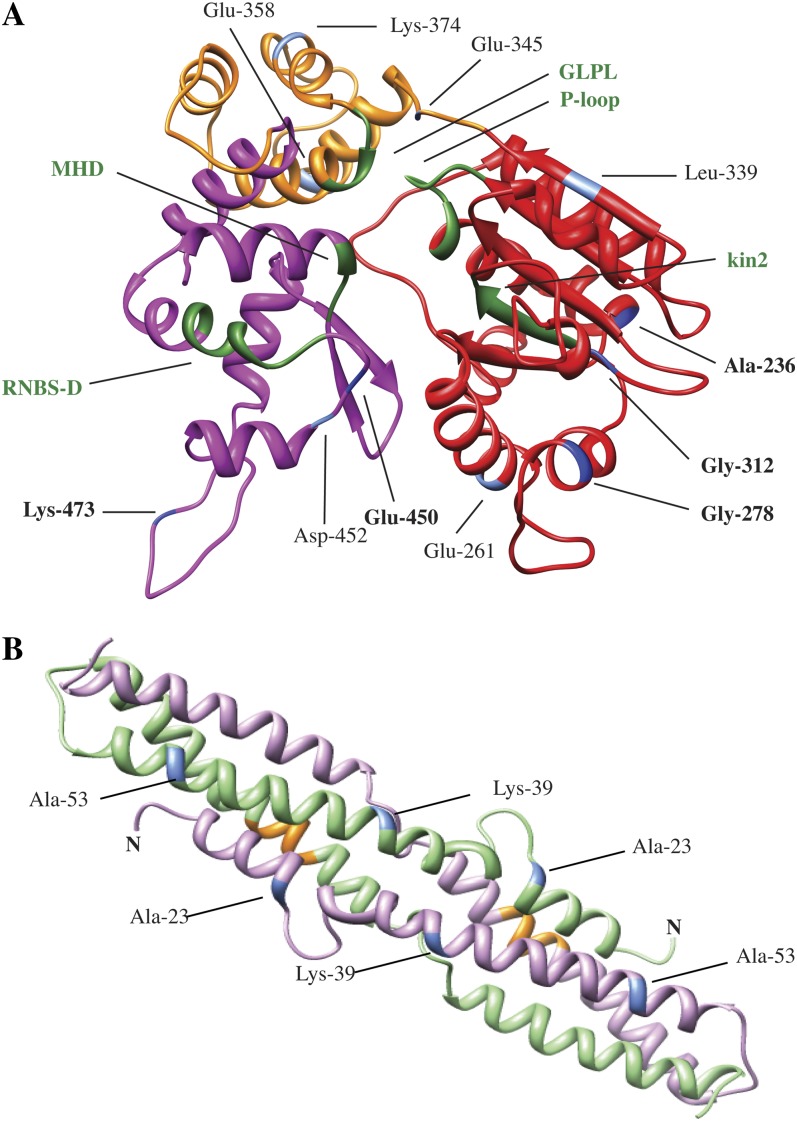
We used a comparative genomics approach to investigate the evolution of a complex nucleotide-binding (NB)-leucine-rich repeat (LRR) gene cluster found in soybean (Glycine max) and common bean (Phaseolus vulgaris) that is associated with several disease resistance (R) genes of known function, including Rpg1b (for Resistance to Pseudomonas glycinea1b), an R gene effective against specific races of bacterial blight. Analysis of domains revealed that the amino-terminal coiled-coil (CC) domain, central nucleotide-binding domain (NB-ARC [for APAF1, Resistance genes, and CED4]), and carboxyl-terminal LRR domain have undergone distinct evolutionary paths. Sequence exchanges within the NB-ARC domain were rare. In contrast, interparalogue exchanges involving the CC and LRR domains were common, consistent with both of these regions coevolving with pathogens. Residues under positive selection were overrepresented within the predicted solvent-exposed face of the LRR domain, although several also were detected within the CC and NB-ARC domains. Superimposition of these latter residues onto predicted tertiary structures revealed that the majority are located on the surface, suggestive of a role in interactions with other domains or proteins. Following polyploidy in the Glycine lineage, NB-LRR genes have been preferentially lost from one of the duplicated chromosomes (homeologues found in soybean), and there has been partitioning of NB-LRR clades between the two homeologues. The single orthologous region in common bean contains approximately the same number of paralogues as found in the two soybean homeologues combined. We conclude that while polyploidization in Glycine has not driven a stable increase in family size for NB-LRR genes, it has generated two recombinationally isolated clusters, one of which appears to be in the process of decay.
Figures


References
-
- Adams KL, Wendel JF. (2005) Polyploidy and genome evolution in plants. Curr Opin Plant Biol 8: 135–141 - PubMed
-
- Albrecht M, Takken FL. (2006) Update on the domain architectures of NLRs and R proteins. Biochem Biophys Res Commun 339: 459–462 - PubMed
-
- Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ. (1990) Basic local alignment search tool. J Mol Biol 215: 403–410 - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
