

Cortical representation of animate and inanimate objects in complex natural scenes
- PMID: 22472178
- PMCID: PMC3407302
- DOI: 10.1016/j.jphysparis.2012.02.001
Cortical representation of animate and inanimate objects in complex natural scenes
Abstract
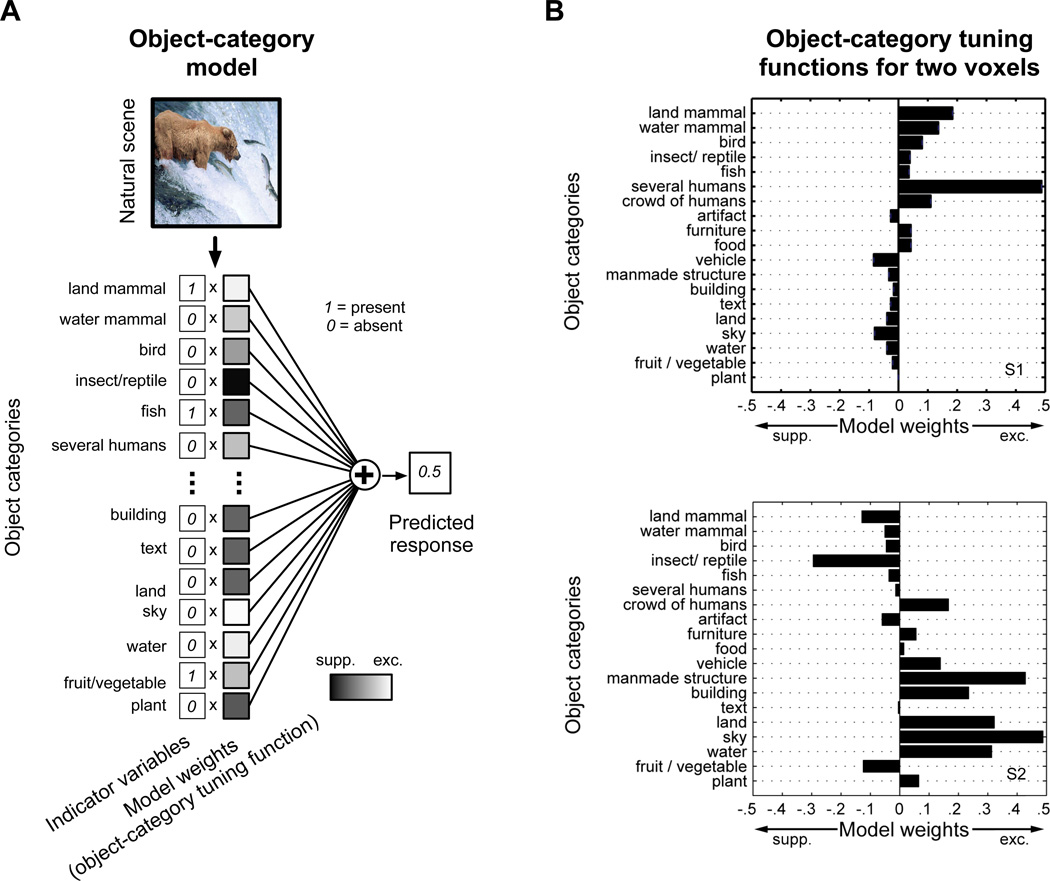
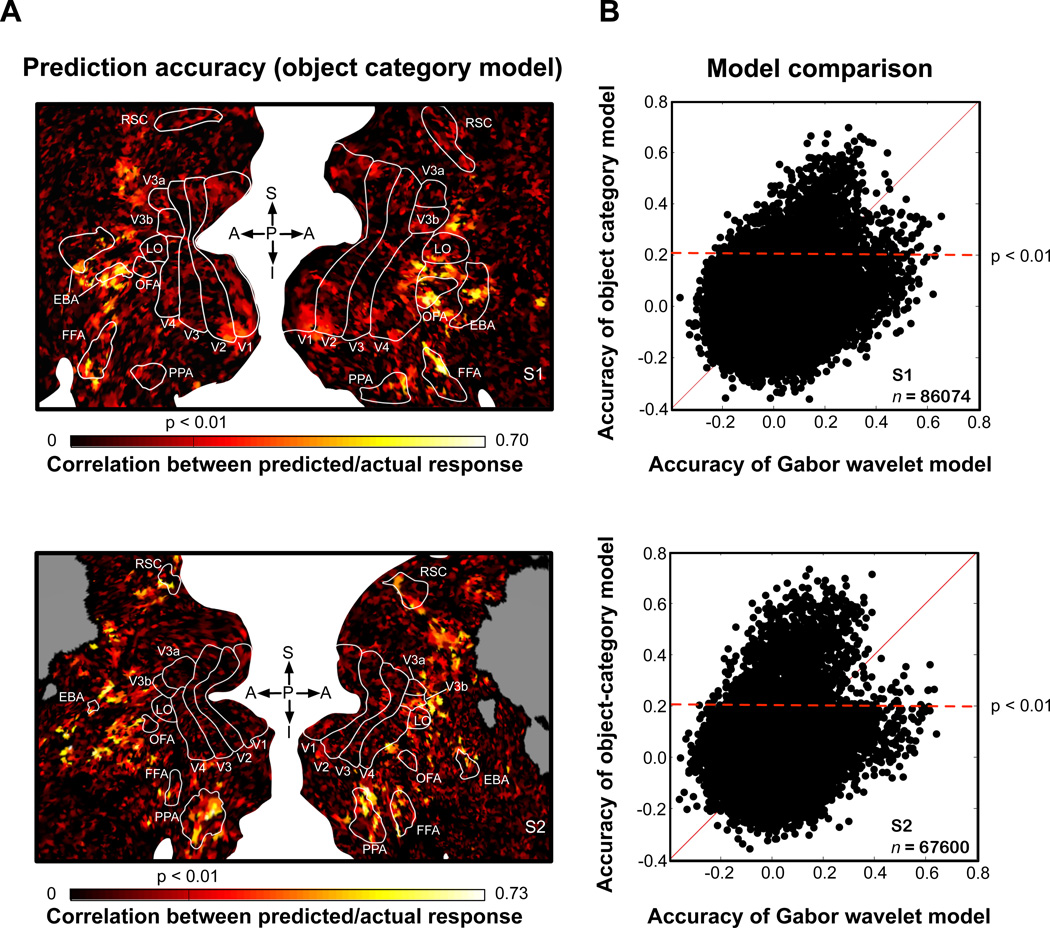
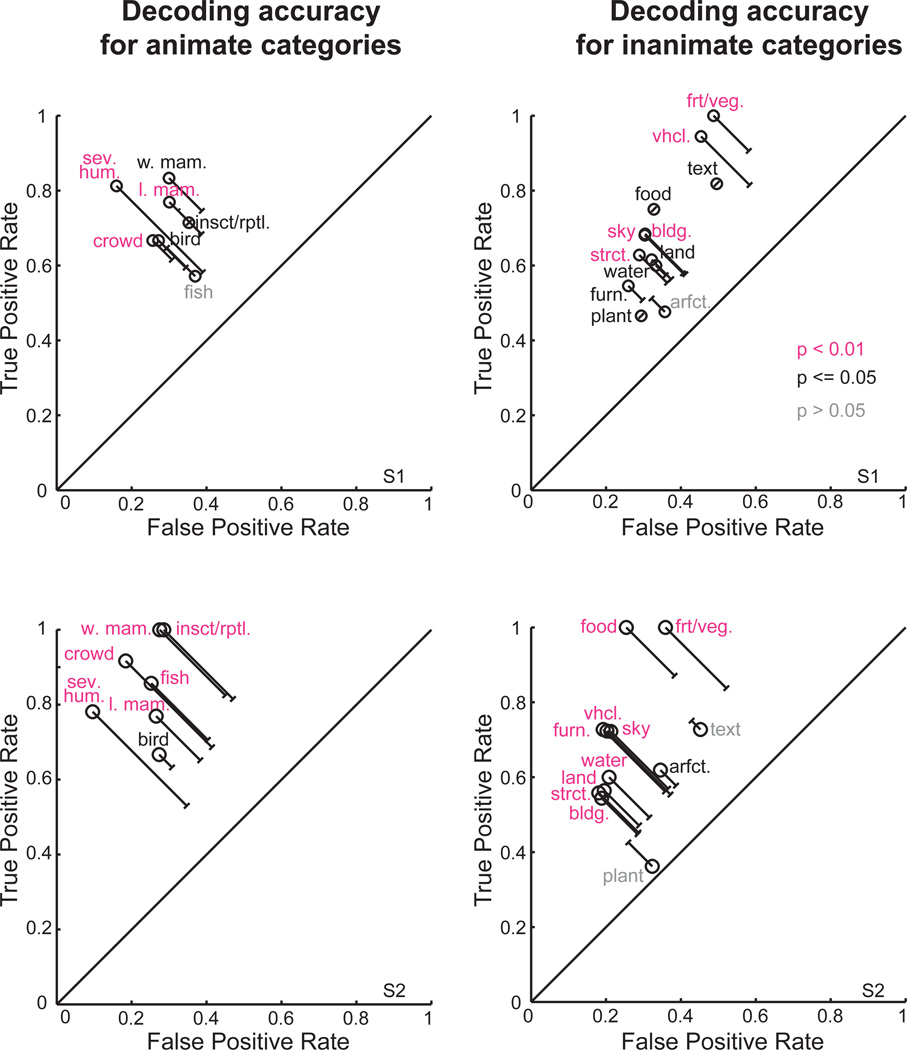
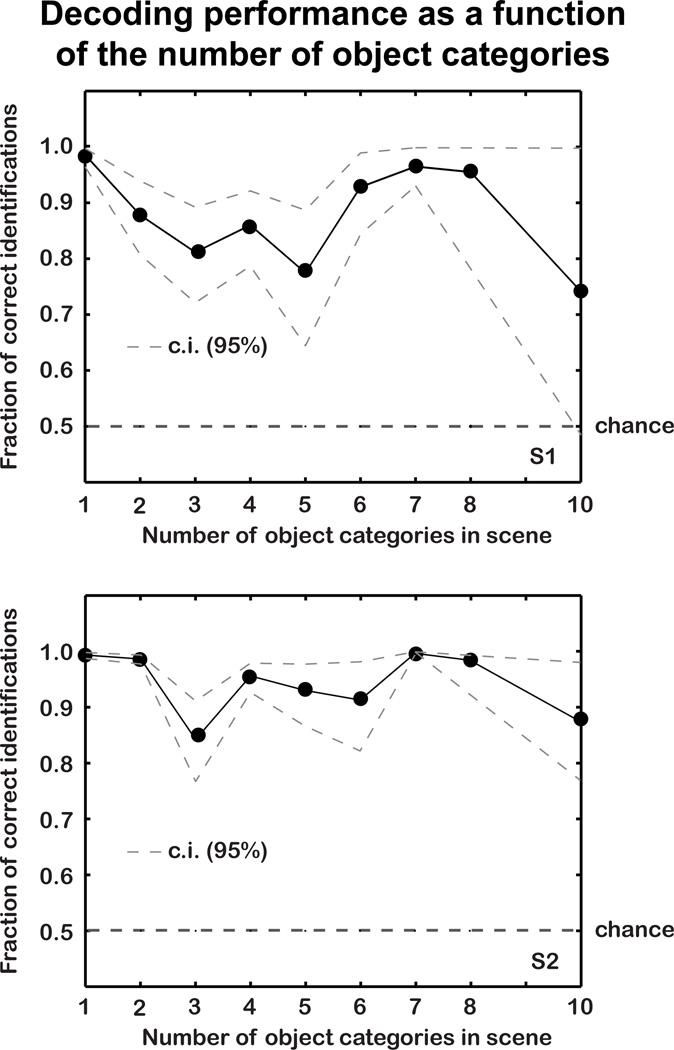
The representations of animate and inanimate objects appear to be anatomically and functionally dissociated in the primate brain. How much of the variation in object-category tuning across cortical locations can be explained in terms of the animate/inanimate distinction? How is the distinction between animate and inanimate reflected in the arrangement of object representations along the cortical surface? To investigate these issues we recorded BOLD activity in visual cortex while subjects viewed streams of natural scenes. We then constructed an explicit model of object-category tuning for each voxel along the cortical surface. We verified that these models accurately predict responses to novel scenes for voxels located in anterior visual areas, and that they can be used to accurately decode multiple objects simultaneously from novel scenes. Finally, we used principal components analysis to characterize the variation in object-category tuning across voxels. Remarkably, we found that the first principal component reflects the distinction between animate and inanimate objects. This dimension accounts for between 50 and 60% of the total variation in object-category tuning across voxels in anterior visual areas. The importance of the animate-inanimate distinction is further reflected in the arrangement of voxels on the cortical surface: voxels that prefer animate objects tend to be located anterior to retinotopic visual areas and are flanked by voxels that prefer inanimate objects. Our explicit model of object-category tuning thus explains the anatomical and functional dissociation of animate and inanimate objects.
Copyright © 2012 Elsevier Ltd. All rights reserved.
Conflict of interest statement
Conflict of Interest:
The authors declare no conflict of interest related to this work.
Figures



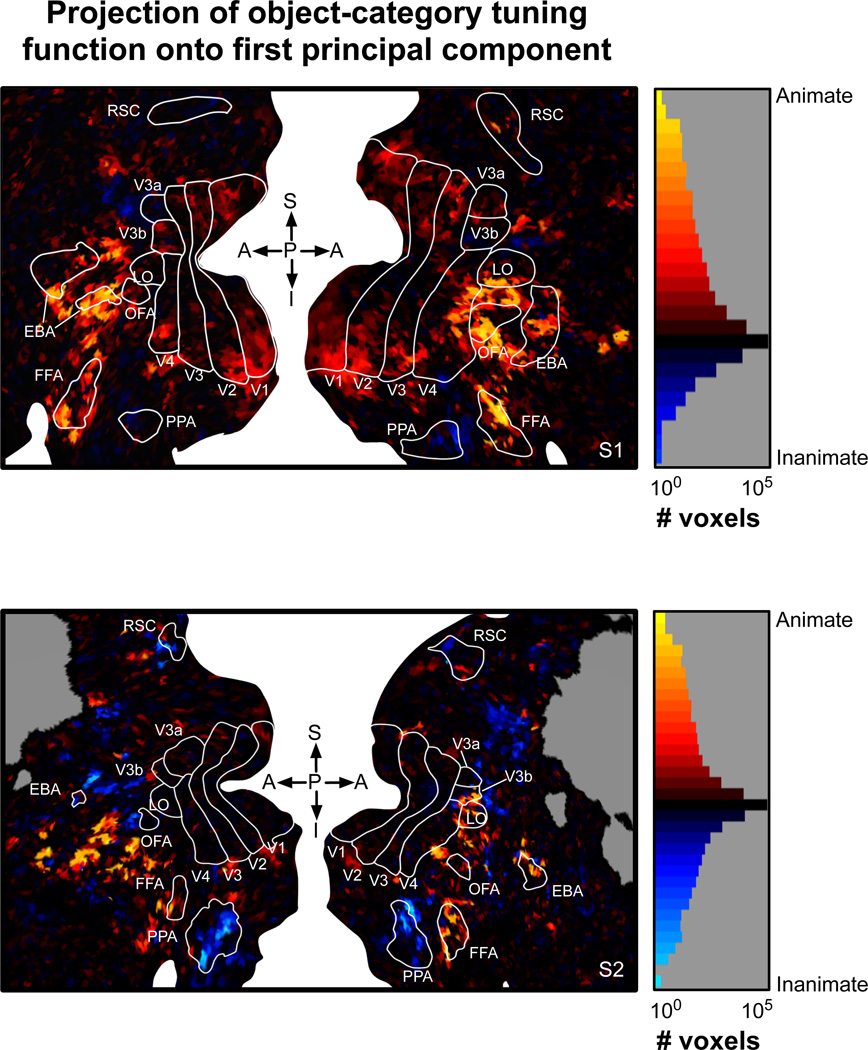
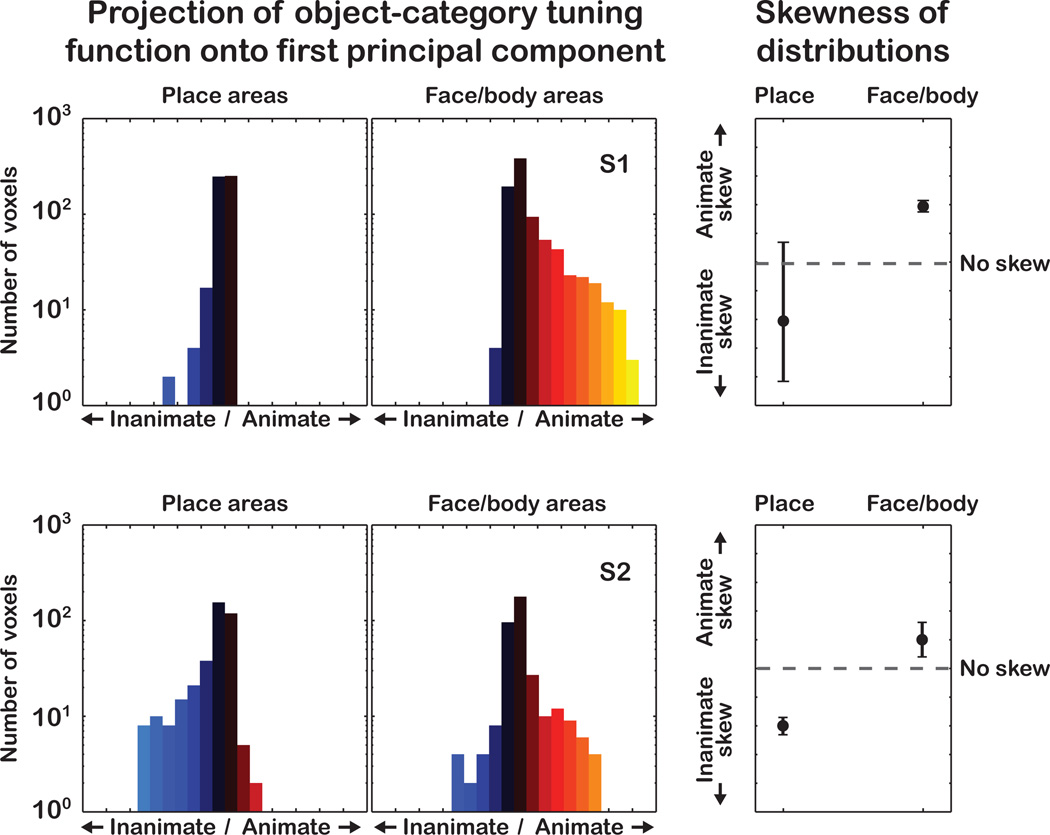
Similar articles
-
Disentangling Representations of Object Shape and Object Category in Human Visual Cortex: The Animate-Inanimate Distinction.J Cogn Neurosci. 2016 May;28(5):680-92. doi: 10.1162/jocn_a_00924. Epub 2016 Jan 14. J Cogn Neurosci. 2016. PMID: 26765944
-
Animate and inanimate objects in human visual cortex: Evidence for task-independent category effects.Neuropsychologia. 2009 Dec;47(14):3111-7. doi: 10.1016/j.neuropsychologia.2009.07.008. Epub 2009 Jul 23. Neuropsychologia. 2009. PMID: 19631673
-
The Ventral Visual Pathway Represents Animal Appearance over Animacy, Unlike Human Behavior and Deep Neural Networks.J Neurosci. 2019 Aug 14;39(33):6513-6525. doi: 10.1523/JNEUROSCI.1714-18.2019. Epub 2019 Jun 13. J Neurosci. 2019. PMID: 31196934 Free PMC article.
-
Color statistics of objects, and color tuning of object cortex in macaque monkey.J Vis. 2018 Oct 1;18(11):1. doi: 10.1167/18.11.1. J Vis. 2018. PMID: 30285103 Free PMC article.
-
Invariant visual object recognition: a model, with lighting invariance.J Physiol Paris. 2006 Jul-Sep;100(1-3):43-62. doi: 10.1016/j.jphysparis.2006.09.004. Epub 2006 Oct 30. J Physiol Paris. 2006. PMID: 17071062 Review.
Cited by
-
Population coding of affect across stimuli, modalities and individuals.Nat Neurosci. 2014 Aug;17(8):1114-22. doi: 10.1038/nn.3749. Epub 2014 Jun 22. Nat Neurosci. 2014. PMID: 24952643 Free PMC article.
-
Deep Residual Network Predicts Cortical Representation and Organization of Visual Features for Rapid Categorization.Sci Rep. 2018 Feb 28;8(1):3752. doi: 10.1038/s41598-018-22160-9. Sci Rep. 2018. PMID: 29491405 Free PMC article.
-
Scene complexity modulates degree of feedback activity during object detection in natural scenes.PLoS Comput Biol. 2018 Dec 31;14(12):e1006690. doi: 10.1371/journal.pcbi.1006690. eCollection 2018 Dec. PLoS Comput Biol. 2018. PMID: 30596644 Free PMC article.
-
Temporal dynamics of animacy categorization in the brain of patients with mild cognitive impairment.PLoS One. 2022 Feb 23;17(2):e0264058. doi: 10.1371/journal.pone.0264058. eCollection 2022. PLoS One. 2022. PMID: 35196356 Free PMC article.
-
The feature-weighted receptive field: an interpretable encoding model for complex feature spaces.Neuroimage. 2018 Oct 15;180(Pt A):188-202. doi: 10.1016/j.neuroimage.2017.06.035. Epub 2017 Jun 20. Neuroimage. 2018. PMID: 28645845 Free PMC article.
References
-
- Caramazza A, Shelton JR. Domain-specific knowledge systems in the brain: The animate-inanimate distinction. J. of Cogn. Neurosci. 1998;10:1–34. - PubMed
-
- David SV, Gallant JL. Predicting neuronal responses during natural vision. Network. 2005;16:239–260. - PubMed
-
- Downing PE, Chan AW-Y, Peelen MV, Dodds CM, Kanwisher N. Domain specificity in visual cortex. Cereb. Cortex. 2006;16:1453–1461. - PubMed
-
- Downing PE, Jiang Y, Shuman M, Kanwisher N. A cortical area selective for visual processing of the human body. Science. 2001;293:2470–2473. - PubMed
-
- Epstein R, Kanwisher N. A cortical representation of the local visual environment. Nature. 1998;392:598–601. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
