

Reasoning, learning, and creativity: frontal lobe function and human decision-making
- PMID: 22479152
- PMCID: PMC3313946
- DOI: 10.1371/journal.pbio.1001293
Reasoning, learning, and creativity: frontal lobe function and human decision-making
Abstract
The frontal lobes subserve decision-making and executive control--that is, the selection and coordination of goal-directed behaviors. Current models of frontal executive function, however, do not explain human decision-making in everyday environments featuring uncertain, changing, and especially open-ended situations. Here, we propose a computational model of human executive function that clarifies this issue. Using behavioral experiments, we show that unlike others, the proposed model predicts human decisions and their variations across individuals in naturalistic situations. The model reveals that for driving action, the human frontal function monitors up to three/four concurrent behavioral strategies and infers online their ability to predict action outcomes: whenever one appears more reliable than unreliable, this strategy is chosen to guide the selection and learning of actions that maximize rewards. Otherwise, a new behavioral strategy is tentatively formed, partly from those stored in long-term memory, then probed, and if competitive confirmed to subsequently drive action. Thus, the human executive function has a monitoring capacity limited to three or four behavioral strategies. This limitation is compensated by the binary structure of executive control that in ambiguous and unknown situations promotes the exploration and creation of new behavioral strategies. The results support a model of human frontal function that integrates reasoning, learning, and creative abilities in the service of decision-making and adaptive behavior.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
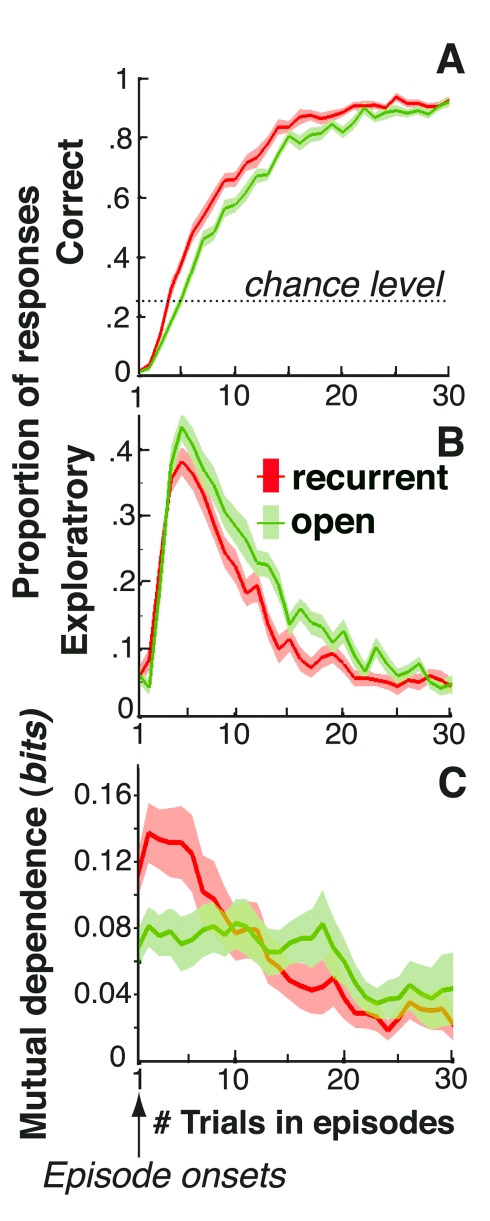
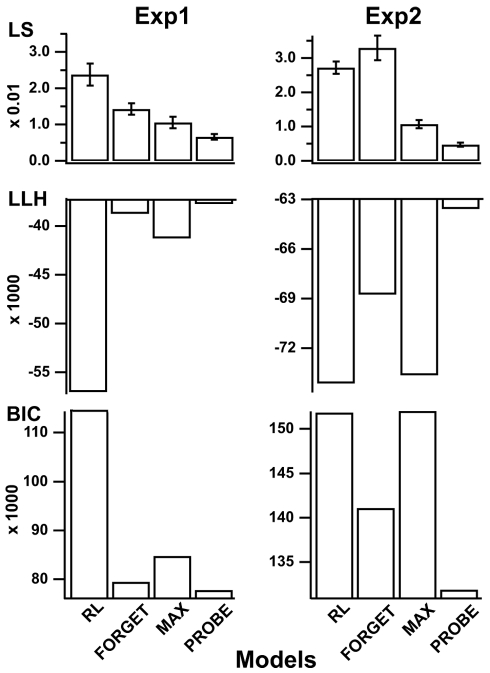

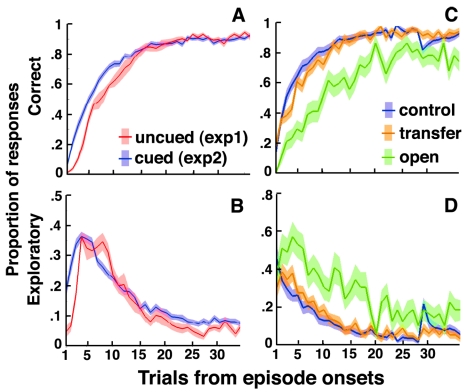

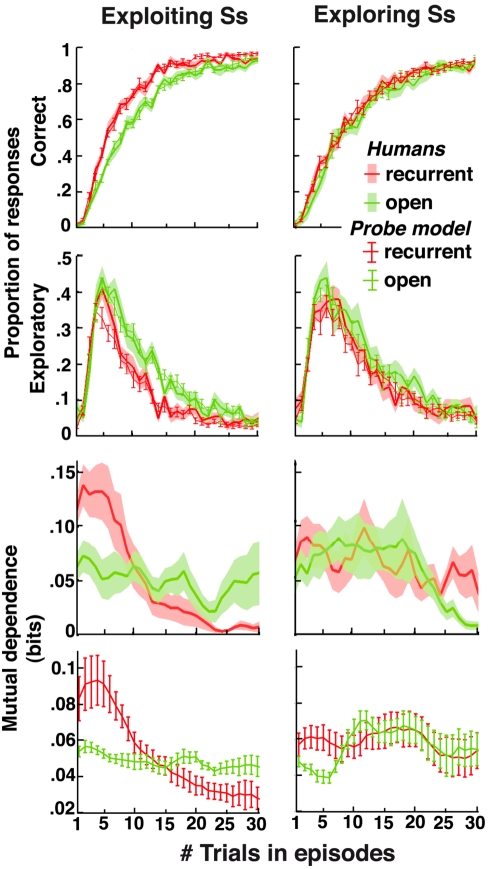

References
-
- Simon H. Models of bounded rationality: empirically grounded economic reason. Cambridge: The MIT Press; 1997.
-
- Kahneman D, Tversky A. Choices, values and frames. Cambridge University Press; 2000.
-
- Glimcher P. W, Camerer C. F, Fehr E, Poldrack R. A. Neuroeconomics: decision-making and the brain. London: Academic Press, Elsevier; 2009.
-
- Harlow H. F. The formation of learning sets. Psychological Review. 1949;56:51–65. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
