

Habits, action sequences and reinforcement learning
- PMID: 22487034
- PMCID: PMC3325518
- DOI: 10.1111/j.1460-9568.2012.08050.x
Habits, action sequences and reinforcement learning
Abstract
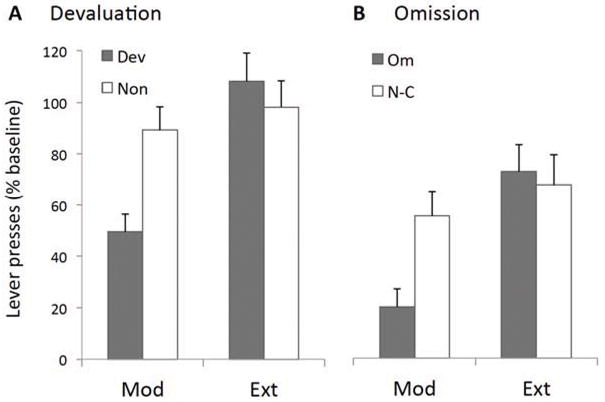
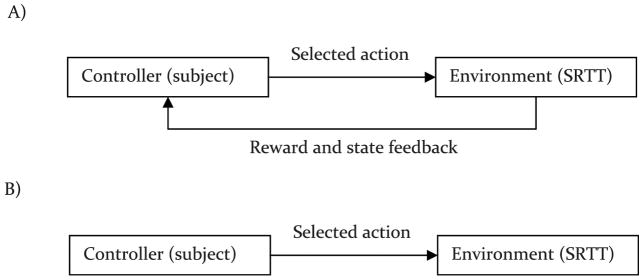
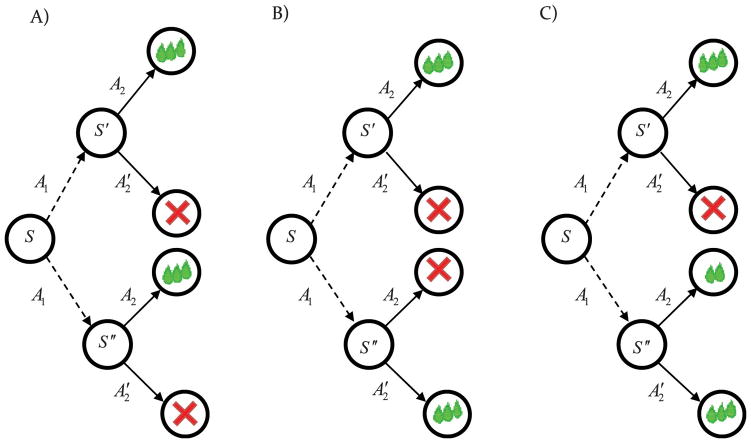
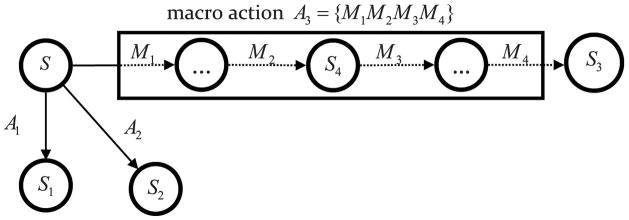
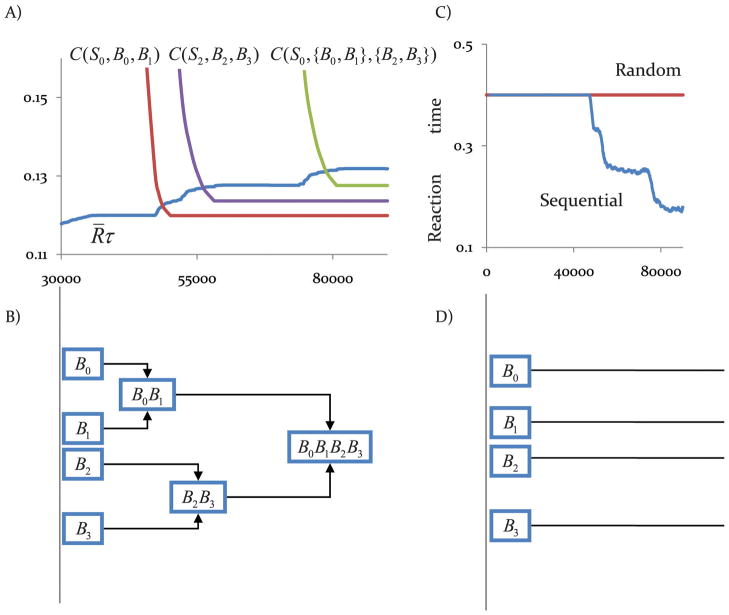
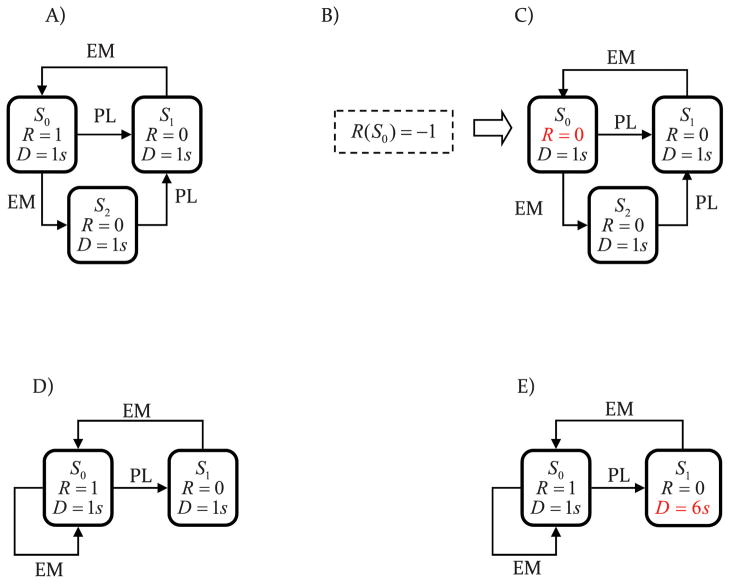
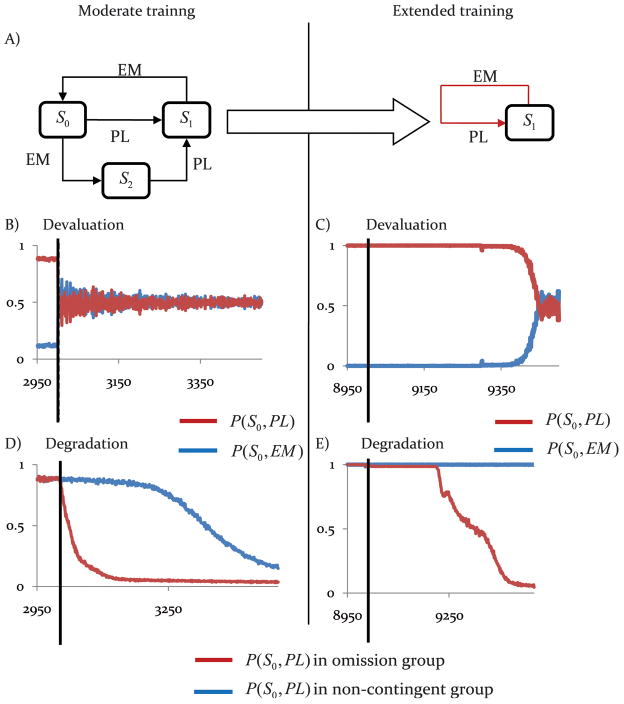
It is now widely accepted that instrumental actions can be either goal-directed or habitual; whereas the former are rapidly acquired and regulated by their outcome, the latter are reflexive, elicited by antecedent stimuli rather than their consequences. Model-based reinforcement learning (RL) provides an elegant description of goal-directed action. Through exposure to states, actions and rewards, the agent rapidly constructs a model of the world and can choose an appropriate action based on quite abstract changes in environmental and evaluative demands. This model is powerful but has a problem explaining the development of habitual actions. To account for habits, theorists have argued that another action controller is required, called model-free RL, that does not form a model of the world but rather caches action values within states allowing a state to select an action based on its reward history rather than its consequences. Nevertheless, there are persistent problems with important predictions from the model; most notably the failure of model-free RL correctly to predict the insensitivity of habitual actions to changes in the action-reward contingency. Here, we suggest that introducing model-free RL in instrumental conditioning is unnecessary, and demonstrate that reconceptualizing habits as action sequences allows model-based RL to be applied to both goal-directed and habitual actions in a manner consistent with what real animals do. This approach has significant implications for the way habits are currently investigated and generates new experimental predictions.
© 2012 The Authors. European Journal of Neuroscience © 2012 Federation of European Neuroscience Societies and Blackwell Publishing Ltd.
Figures
References
-
- Adams CD. Variations in the sensitivity of instrumental responding to reinforcer devaluation. The Quarterly Journal of Experimental Psychology Section B. 1982;34B:77–98.
-
- Alexander GE, Crutcher MD. Functional architecture of basal ganglia circuits: neural substrates of parallel processing. Trends in neurosciences. 1990;13(7):266–71. - PubMed
-
- Astrom KJ, Murray RM. Feedback Systems: An Introduction for Scientists and Engineers. Princeton, NJ: Princeton University Press; 2008.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
