

A family-based probabilistic method for capturing de novo mutations from high-throughput short-read sequencing data
- PMID: 22499693
- PMCID: PMC3728889
- DOI: 10.2202/1544-6115.1713
A family-based probabilistic method for capturing de novo mutations from high-throughput short-read sequencing data
Abstract
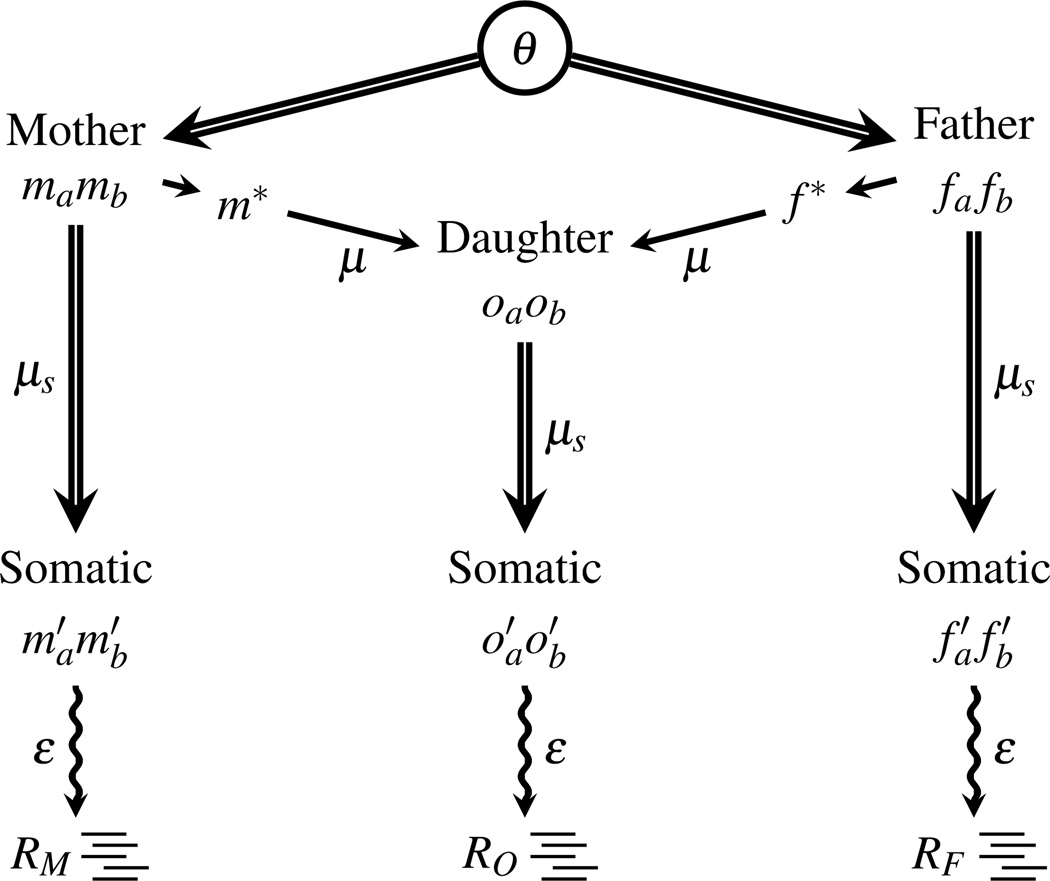
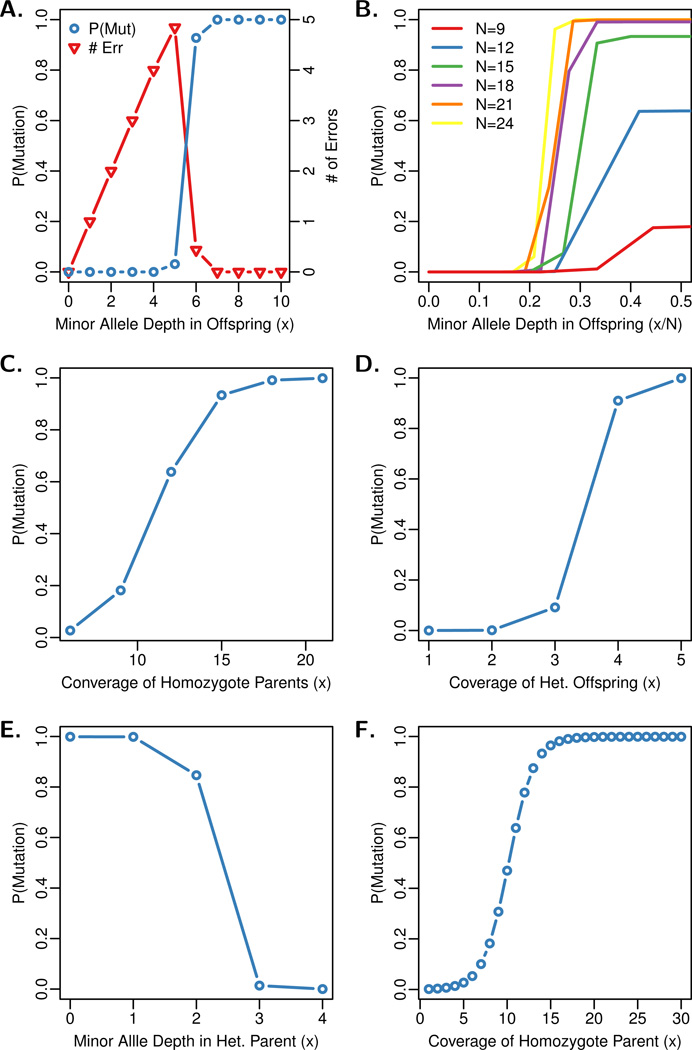
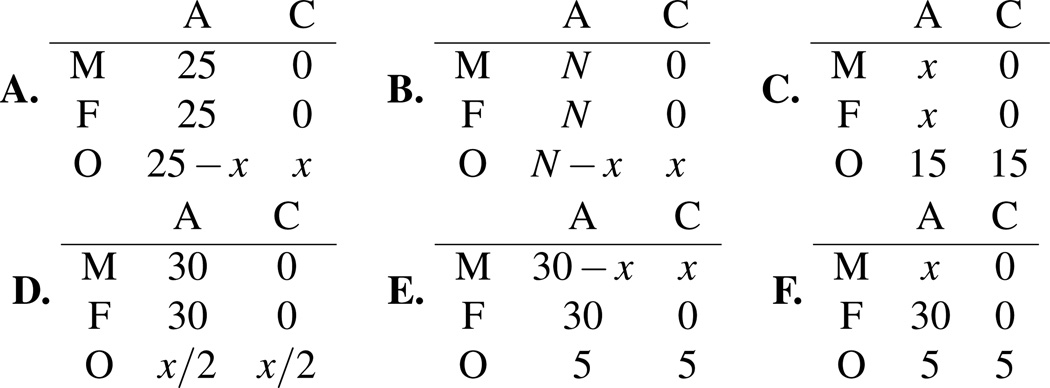
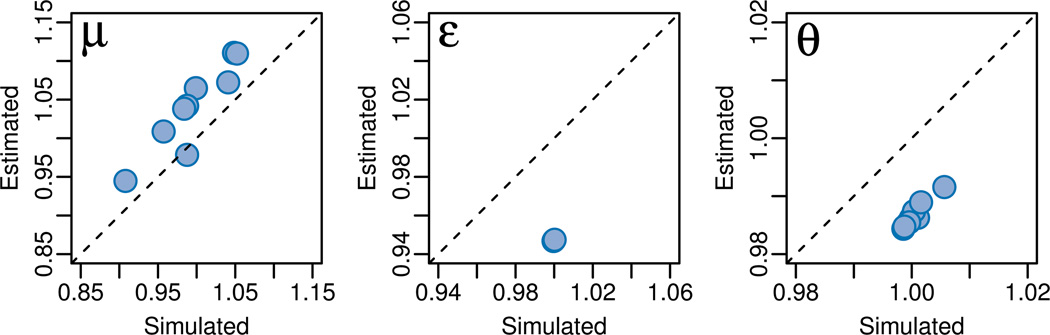
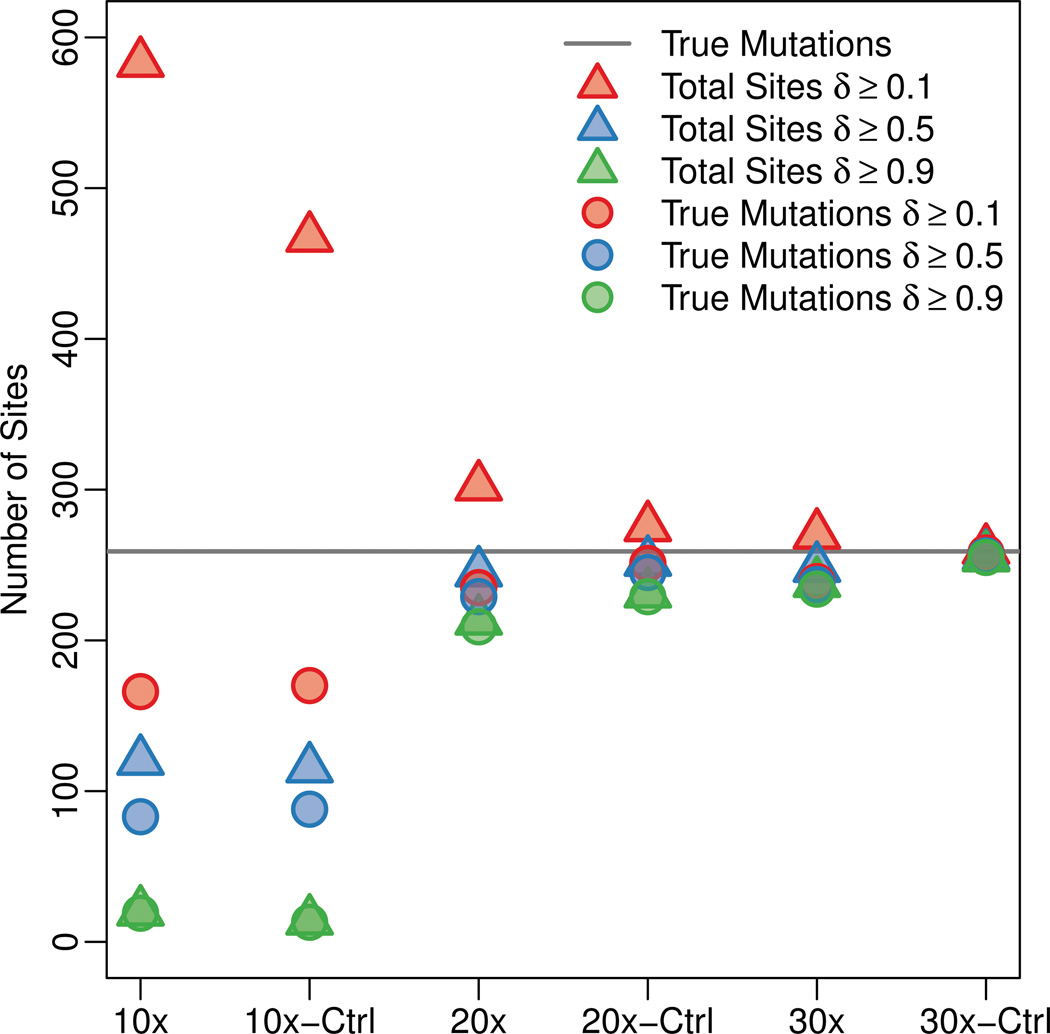
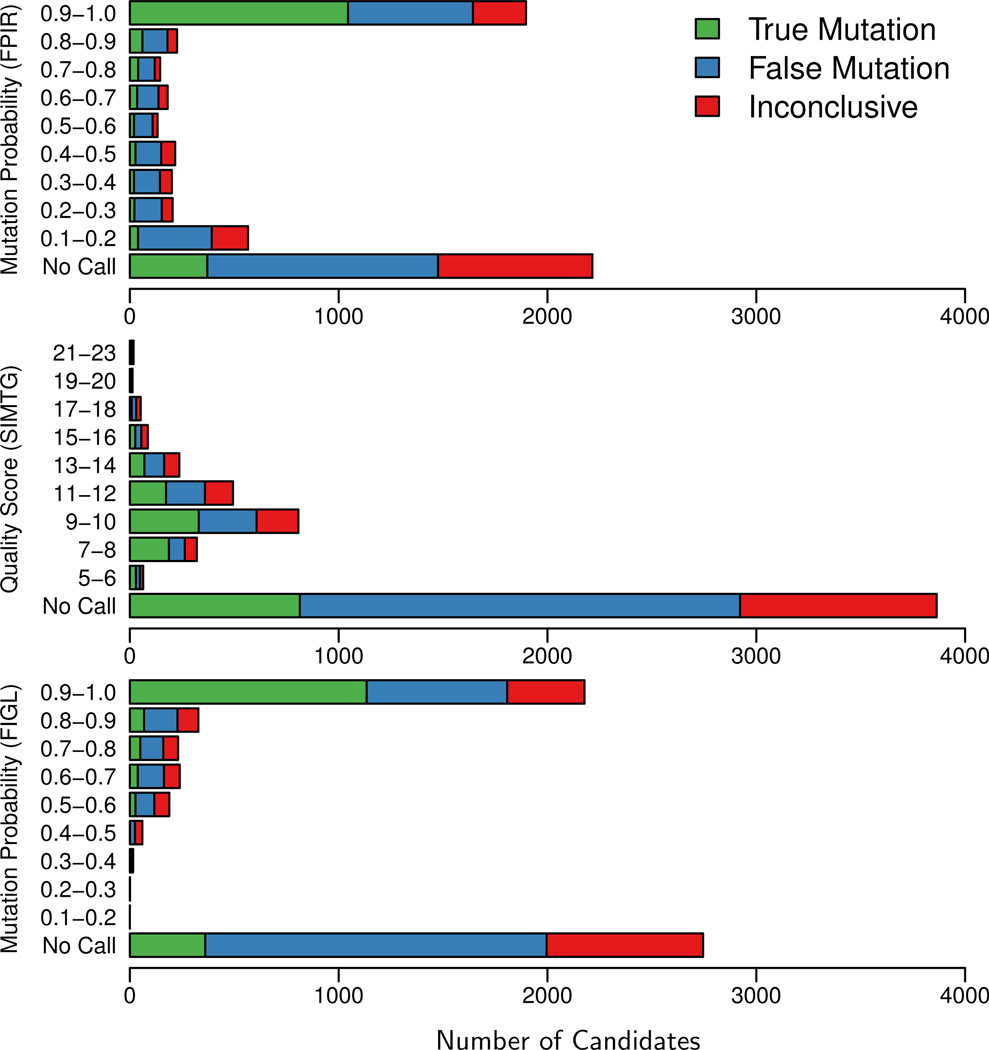
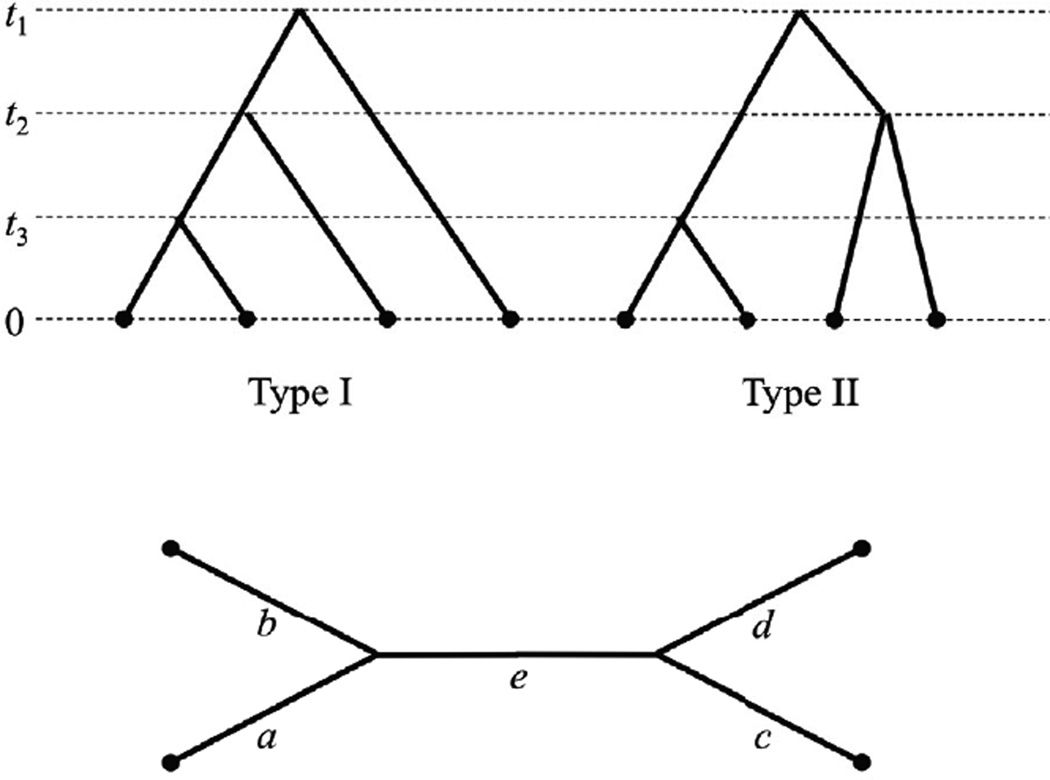
Recent advances in high-throughput DNA sequencing technologies and associated statistical analyses have enabled in-depth analysis of whole-genome sequences. As this technology is applied to a growing number of individual human genomes, entire families are now being sequenced. Information contained within the pedigree of a sequenced family can be leveraged when inferring the donors' genotypes. The presence of a de novo mutation within the pedigree is indicated by a violation of Mendelian inheritance laws. Here, we present a method for probabilistically inferring genotypes across a pedigree using high-throughput sequencing data and producing the posterior probability of de novo mutation at each genomic site examined. This framework can be used to disentangle the effects of germline and somatic mutational processes and to simultaneously estimate the effect of sequencing error and the initial genetic variation in the population from which the founders of the pedigree arise. This approach is examined in detail through simulations and areas for method improvement are noted. By applying this method to data from members of a well-defined nuclear family with accurate pedigree information, the stage is set to make the most direct estimates of the human mutation rate to date.
Figures


References
-
- Dempster A, et al. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B (Methodological) 1977;39:1–38.
-
- Felsenstein J. Evolutionary trees from DNA sequences: a maximum likelihood approach. Journal of Molecular Evolution. 1981;17:368–376. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials