

jmzReader: A Java parser library to process and visualize multiple text and XML-based mass spectrometry data formats
- PMID: 22539430
- PMCID: PMC3472022
- DOI: 10.1002/pmic.201100578
jmzReader: A Java parser library to process and visualize multiple text and XML-based mass spectrometry data formats
Abstract
We here present the jmzReader library: a collection of Java application programming interfaces (APIs) to parse the most commonly used peak list and XML-based mass spectrometry (MS) data formats: DTA, MS2, MGF, PKL, mzXML, mzData, and mzML (based on the already existing API jmzML). The library is optimized to be used in conjunction with mzIdentML, the recently released standard data format for reporting protein and peptide identifications, developed by the HUPO proteomics standards initiative (PSI). mzIdentML files do not contain spectra data but contain references to different kinds of external MS data files. As a key functionality, all parsers implement a common interface that supports the various methods used by mzIdentML to reference external spectra. Thus, when developing software for mzIdentML, programmers no longer have to support multiple MS data file formats but only this one interface. The library (which includes a viewer) is open source and, together with detailed documentation, can be downloaded from http://code.google.com/p/jmzreader/.
© 2012 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim.
Figures
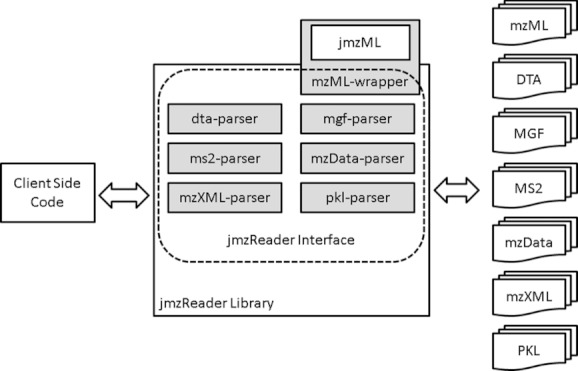
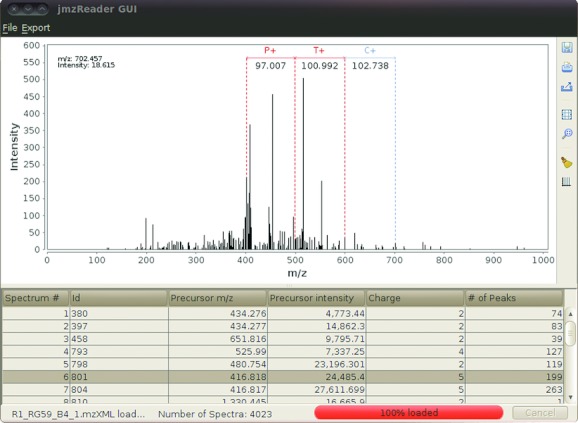
References
-
- Carr S, Aebersold R, Baldwin M, Burlingame A, et al. The need for guidelines in publication of peptide and protein identification data: working Group on Publication Guidelines for Peptide and Protein Identification Data. Mol. Cell Proteomics. 2004;3:531–533. - PubMed
-
- Eisenacher M. mzIdentML: an open community-built standard format for the results of proteomics spectrum identification algorithms. Methods Mol. Biol. 2011;696:161–177. - PubMed
-
- Perkins DN, Pappin DJC, Creasy DM, Cottrell JS. Probability-based protein identification by searching sequence databases using mass spectrometry data. Electrophoresis. 1999;20:3551–3567. - PubMed
-
- MacCoss MJ, Wu CC, Yates JR. Probability-based validation of protein identifications using a modified SEQUEST algorithm. Anal. Chem. 2002;74:5593–5599. - PubMed
-
- Geer LY, Markey SP, Kowalak JA, Wagner L, et al. Open mass spectrometry search algorithm. J. Proteome Res. 2004;3:958–964. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
