

Reconstruction of genome-scale active metabolic networks for 69 human cell types and 16 cancer types using INIT
- PMID: 22615553
- PMCID: PMC3355067
- DOI: 10.1371/journal.pcbi.1002518
Reconstruction of genome-scale active metabolic networks for 69 human cell types and 16 cancer types using INIT
Abstract
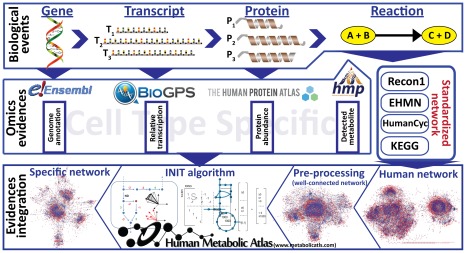
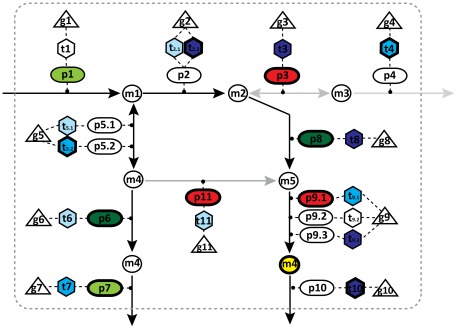
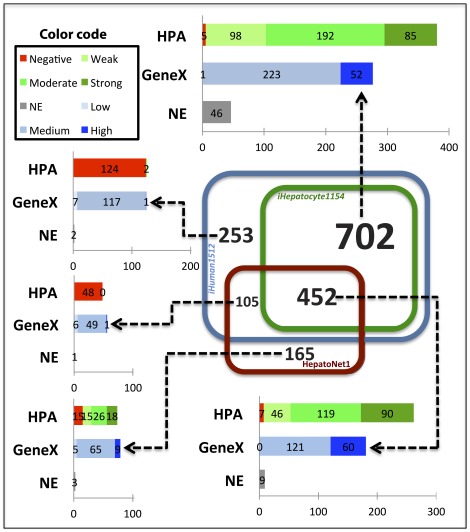
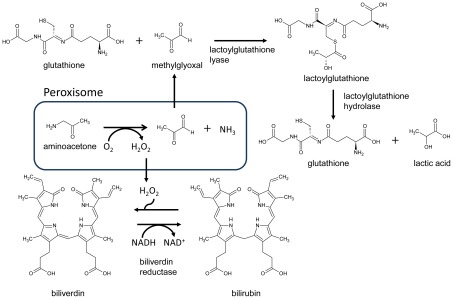
Development of high throughput analytical methods has given physicians the potential access to extensive and patient-specific data sets, such as gene sequences, gene expression profiles or metabolite footprints. This opens for a new approach in health care, which is both personalized and based on system-level analysis. Genome-scale metabolic networks provide a mechanistic description of the relationships between different genes, which is valuable for the analysis and interpretation of large experimental data-sets. Here we describe the generation of genome-scale active metabolic networks for 69 different cell types and 16 cancer types using the INIT (Integrative Network Inference for Tissues) algorithm. The INIT algorithm uses cell type specific information about protein abundances contained in the Human Proteome Atlas as the main source of evidence. The generated models constitute the first step towards establishing a Human Metabolic Atlas, which will be a comprehensive description (accessible online) of the metabolism of different human cell types, and will allow for tissue-level and organism-level simulations in order to achieve a better understanding of complex diseases. A comparative analysis between the active metabolic networks of cancer types and healthy cell types allowed for identification of cancer-specific metabolic features that constitute generic potential drug targets for cancer treatment.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Caveney E, Caveney BJ, Somaratne R, Turner JR, Gourgiotis L. Pharmaceutical interventions for obesity: a public health perspective. Diabetes Obes Metab. 2011;13:490–497. - PubMed
-
- Rokholm B, Baker JL, Sorensen TI. The levelling off of the obesity epidemic since the year 1999–a review of evidence and perspectives. Obes Rev. 2010;11:835–846. - PubMed
-
- Nielsen J. Systems biology of lipid metabolism: from yeast to human. FEBS Lett. 2009;583:3905–3913. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
