

Generalization of learning by synchronous waves: from perceptual organization to invariant organization
- PMID: 22654985
- PMCID: PMC3100473
- DOI: 10.1007/s11571-010-9142-9
Generalization of learning by synchronous waves: from perceptual organization to invariant organization
Abstract
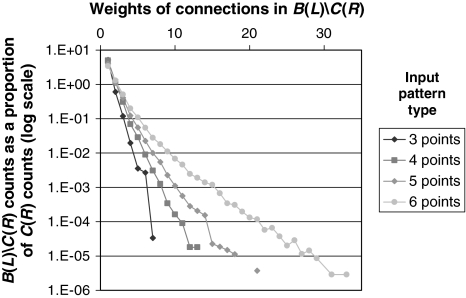
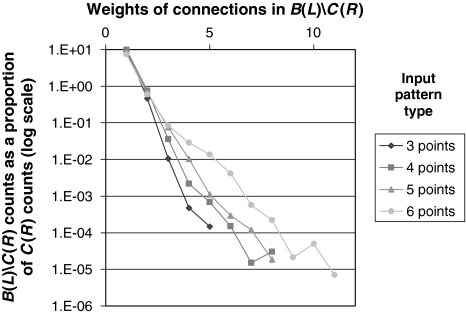
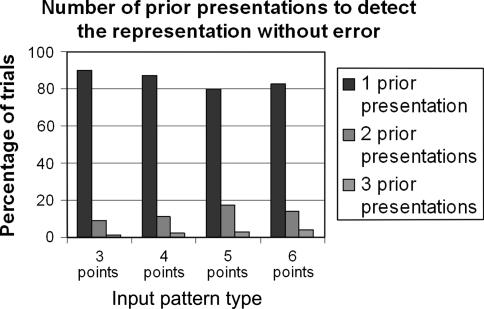
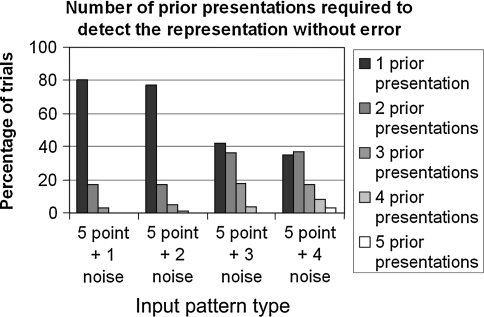
From a few presentations of an object, perceptual systems are able to extract invariant properties such that novel presentations are immediately recognized. This may be enabled by inferring the set of all representations equivalent under certain transformations. We implemented this principle in a neurodynamic model that stores activity patterns representing transformed versions of the same object in a distributed fashion within maps, such that translation across the map corresponds to the relevant transformation. When a pattern on the map is activated, this causes activity to spread out as a wave across the map, activating all the transformed versions represented. Computational studies illustrate the efficacy of the proposed mechanism. The model rapidly learns and successfully recognizes rotated and scaled versions of a visual representation from a few prior presentations. For topographical maps such as primary visual cortex, the mechanism simultaneously represents identity and variation of visual percepts whose features change through time.
Keywords: Cortical dynamics; Learning; Topographic maps; Visual cortex.
Figures





References
-
- Abbott LF, Nelson SB (2000) Synaptic plasticity: taming the beast. Nat Neurosci 3 Suppl:1178–1183 - PubMed
-
- Agu M. Field theory of pattern identification. Physics Review A. 1988;37(11):4415–4418. - PubMed
-
- Alexander DM, Bourke PD, Sheridan P, Konstandatos O, Wright JJ. Intrinsic connections in tree shrew V1 imply a global to local mapping. Vis Res. 2004;44(9):857–876. - PubMed
LinkOut - more resources
Full Text Sources
