

A sparse structure learning algorithm for Gaussian Bayesian Network identification from high-dimensional data
- PMID: 22665720
- PMCID: PMC3924722
- DOI: 10.1109/TPAMI.2012.129
A sparse structure learning algorithm for Gaussian Bayesian Network identification from high-dimensional data
Abstract
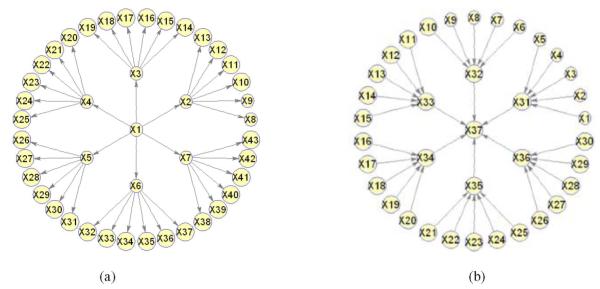
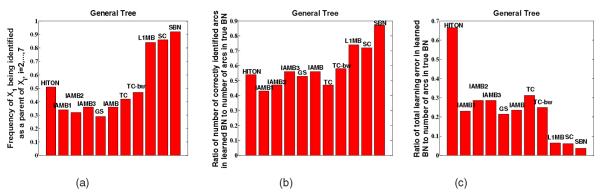
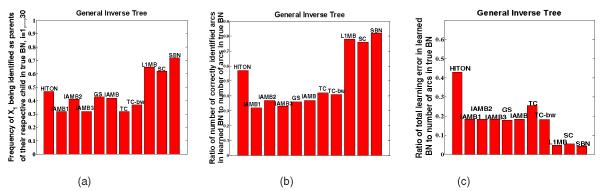
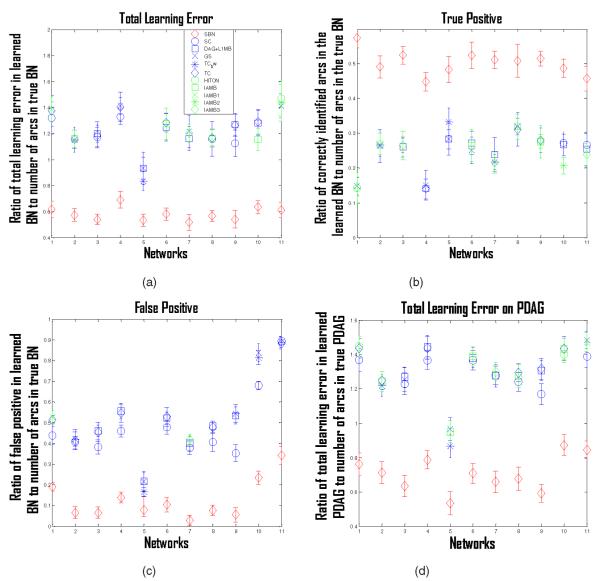
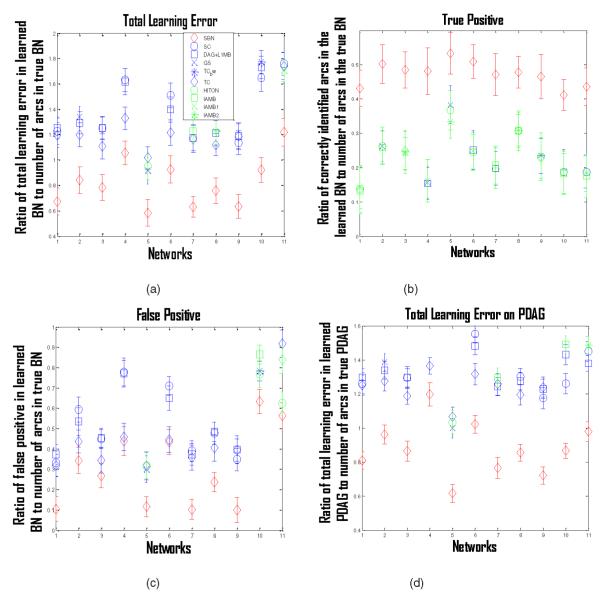
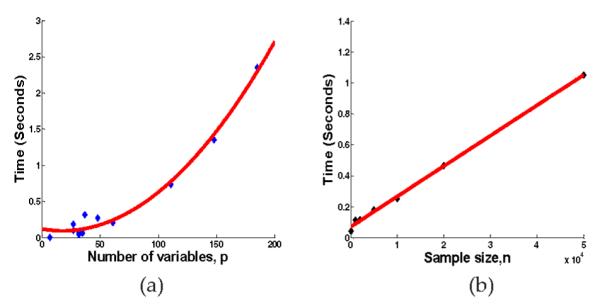
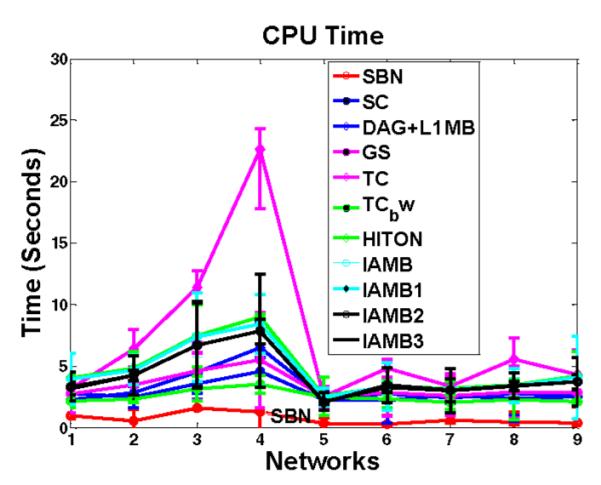
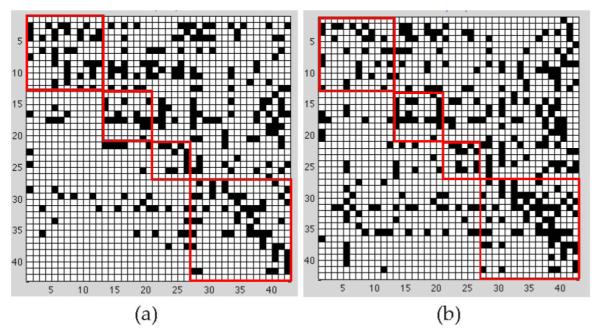
Structure learning of Bayesian Networks (BNs) is an important topic in machine learning. Driven by modern applications in genetics and brain sciences, accurate and efficient learning of large-scale BN structures from high-dimensional data becomes a challenging problem. To tackle this challenge, we propose a Sparse Bayesian Network (SBN) structure learning algorithm that employs a novel formulation involving one L1-norm penalty term to impose sparsity and another penalty term to ensure that the learned BN is a Directed Acyclic Graph--a required property of BNs. Through both theoretical analysis and extensive experiments on 11 moderate and large benchmark networks with various sample sizes, we show that SBN leads to improved learning accuracy, scalability, and efficiency as compared with 10 existing popular BN learning algorithms. We apply SBN to a real-world application of brain connectivity modeling for Alzheimer's disease (AD) and reveal findings that could lead to advancements in AD research.
Figures


References
-
- Friedman N, Linial M, Nachman I, Péer D. Using Bayesian Networks to Analyze Expression Data. J. Computational Biology. 2000;vol. 7:601–620. - PubMed
-
- Marcot BG, Holthausen RS, Raphael MG, Rowland M, Wisdom M. Using Bayesian Belief Networks to Evaluate Fish and Wildlife Population Viability under Land Management Alternatives from an Environmental Impact Statement. Forest Ecology and Management. 2001;vol. 153(nos. 1-3):29–42.
-
- Borsuk ME, Stow CA, Reckhow KH. A Bayesian Network of Eutrophication Models for Synthesis, Prediction, and Uncertainty Analysis. Ecological Modelling. 2004;vol. 173:219–239.
-
- Dai H, Korb KB, Wallace CS, Wu X. A Study of Casual Discovery with Weak Links and Small Samples. Proc. 15th Int’l Joint Conf. Artificial Intelligence.1997. pp. 1304–1309.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
