

Direct reciprocity in structured populations
- PMID: 22665767
- PMCID: PMC3382515
- DOI: 10.1073/pnas.1206694109
Direct reciprocity in structured populations
Abstract
Reciprocity and repeated games have been at the center of attention when studying the evolution of human cooperation. Direct reciprocity is considered to be a powerful mechanism for the evolution of cooperation, and it is generally assumed that it can lead to high levels of cooperation. Here we explore an open-ended, infinite strategy space, where every strategy that can be encoded by a finite state automaton is a possible mutant. Surprisingly, we find that direct reciprocity alone does not lead to high levels of cooperation. Instead we observe perpetual oscillations between cooperation and defection, with defection being substantially more frequent than cooperation. The reason for this is that "indirect invasions" remove equilibrium strategies: every strategy has neutral mutants, which in turn can be invaded by other strategies. However, reciprocity is not the only way to promote cooperation. Another mechanism for the evolution of cooperation, which has received as much attention, is assortment because of population structure. Here we develop a theory that allows us to study the synergistic interaction between direct reciprocity and assortment. This framework is particularly well suited for understanding human interactions, which are typically repeated and occur in relatively fluid but not unstructured populations. We show that if repeated games are combined with only a small amount of assortment, then natural selection favors the behavior typically observed among humans: high levels of cooperation implemented using conditional strategies.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
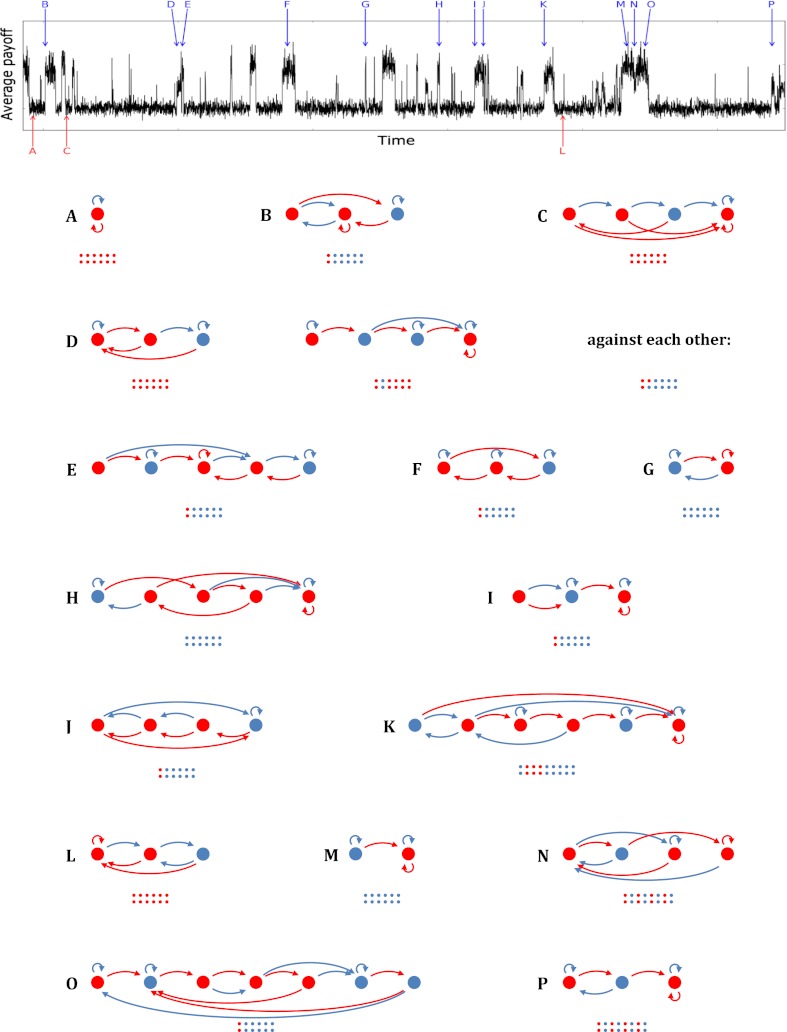
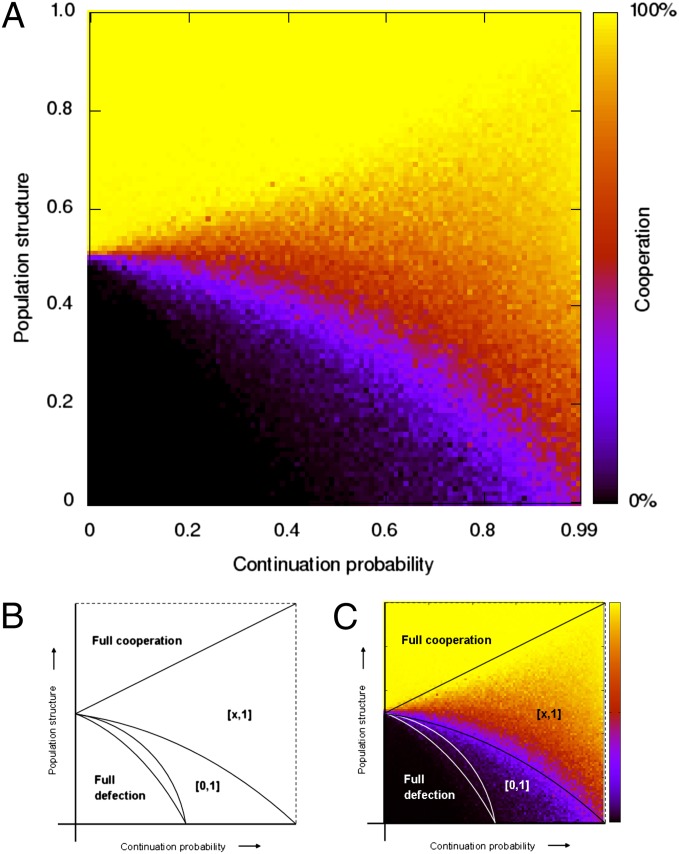
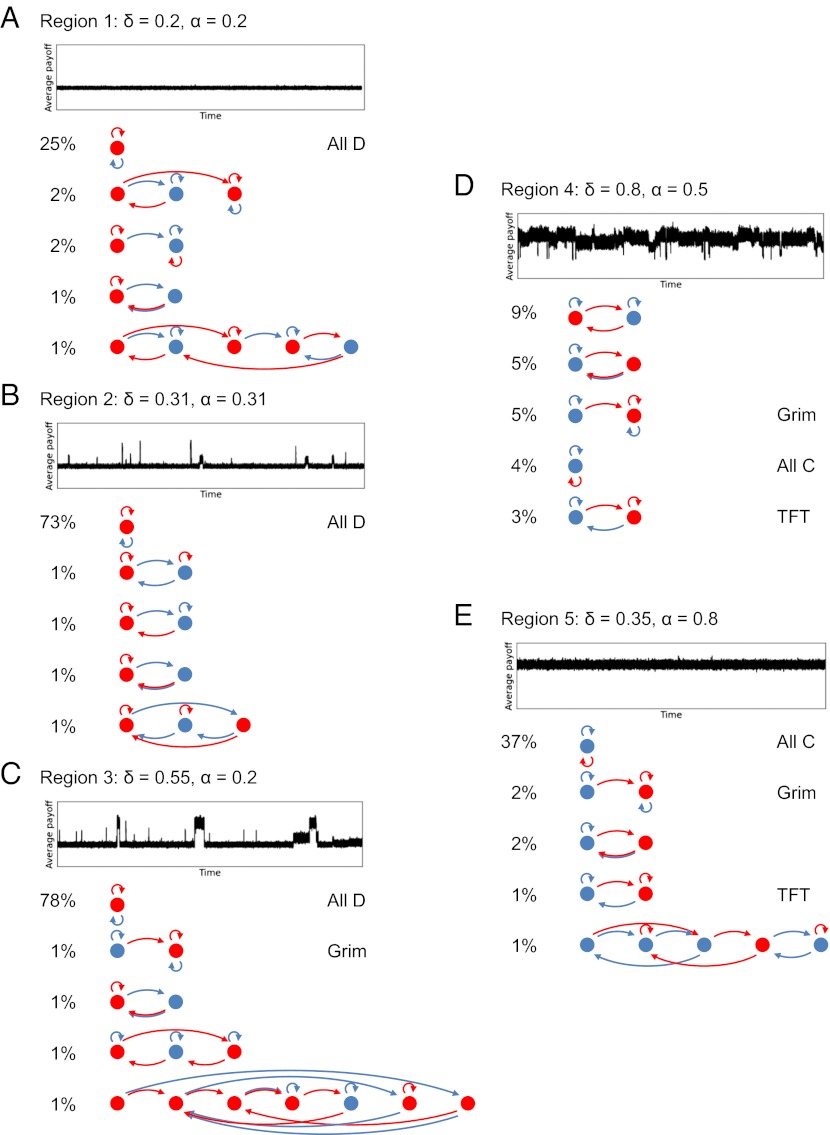
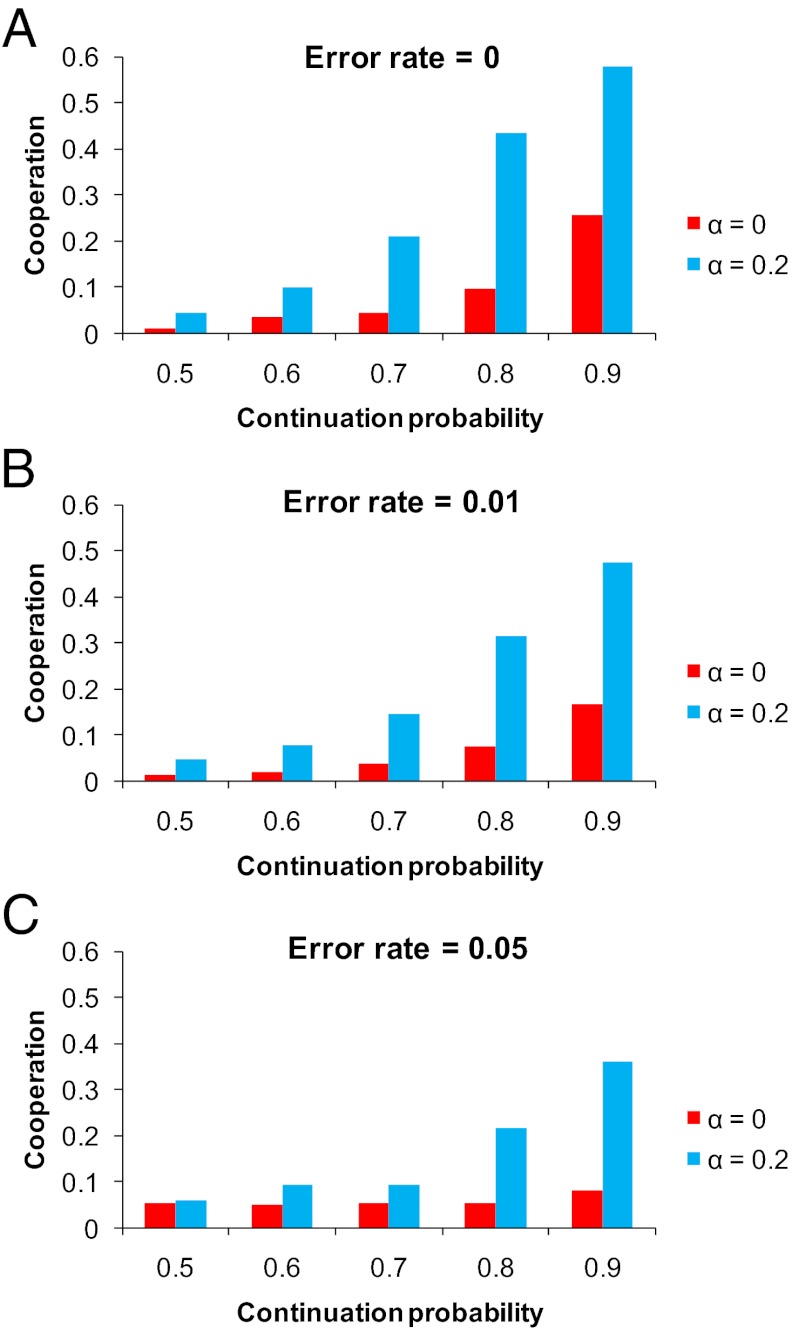
References
-
- Friedman J. A noncooperative equilibrium for supergames. Rev Econ Stud. 1971;38:1–12.
-
- Fudenberg D, Maskin E. The folk theorem in repeated games with discounting or with incomplete information. Econometrica. 1986;54:533–554.
-
- Abreu D. On the theory of infinitely repeated games with discounting. Econometrica. 1988;56:383–396.
-
- Axelrod R, Hamilton WD. The evolution of cooperation. Science. 1981;211:1390–1396. - PubMed
-
- Selten R, Hammerstein P. Gaps in Harley’s argument on evolutionarily stable learning rules and in the logic of “tit for tat.”. Behav Brain Sci. 1984;7:115–116.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
