

Strategies for de-identification and anonymization of electronic health record data for use in multicenter research studies
- PMID: 22692265
- PMCID: PMC6502465
- DOI: 10.1097/MLR.0b013e3182585355
Strategies for de-identification and anonymization of electronic health record data for use in multicenter research studies
Abstract
Background: De-identification and anonymization are strategies that are used to remove patient identifiers in electronic health record data. The use of these strategies in multicenter research studies is paramount in importance, given the need to share electronic health record data across multiple environments and institutions while safeguarding patient privacy.
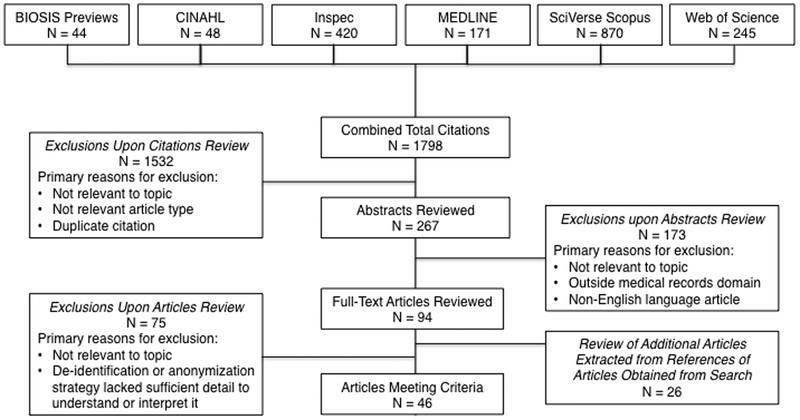
Methods: Systematic literature search using keywords of de-identify, deidentify, de-identification, deidentification, anonymize, anonymization, data scrubbing, and text scrubbing. Search was conducted up to June 30, 2011 and involved 6 different common literature databases. A total of 1798 prospective citations were identified, and 94 full-text articles met the criteria for review and the corresponding articles were obtained. Search results were supplemented by review of 26 additional full-text articles; a total of 120 full-text articles were reviewed.
Results: A final sample of 45 articles met inclusion criteria for review and discussion. Articles were grouped into text, images, and biological sample categories. For text-based strategies, the approaches were segregated into heuristic, lexical, and pattern-based systems versus statistical learning-based systems. For images, approaches that de-identified photographic facial images and magnetic resonance image data were described. For biological samples, approaches that managed the identifiers linked with these samples were discussed, particularly with respect to meeting the anonymization requirements needed for Institutional Review Board exemption under the Common Rule.
Conclusions: Current de-identification strategies have their limitations, and statistical learning-based systems have distinct advantages over other approaches for the de-identification of free text. True anonymization is challenging, and further work is needed in the areas of de-identification of datasets and protection of genetic information.
Comment in
-
Commentary: Protecting human subjects and their data in multi-site research.Med Care. 2012 Jul;50 Suppl:S74-6. doi: 10.1097/MLR.0b013e318257ddd8. Med Care. 2012. PMID: 22692263
References
-
- Sweeney L Computational disclosure control: A primer on data privacy protection. Massachusetts Institute of Technology; 2001
-
- Velupillai S, Dalianis H, Hassel M, et al. Developing a standard for de-identifying electronic patient records written in Swedish: precision, recall and F-measure in a manual and computerized annotation trial. Int J Med Inform 2009;78:e19–26 - PubMed
-
- Grouin C, Rosier A, Dameron O, et al. Testing tactics to localize de-identification. Stud Health Technol Inform 2009;150:735–739 - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
