

Emergence of neural encoding of auditory objects while listening to competing speakers
- PMID: 22753470
- PMCID: PMC3406818
- DOI: 10.1073/pnas.1205381109
Emergence of neural encoding of auditory objects while listening to competing speakers
Abstract
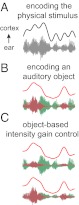
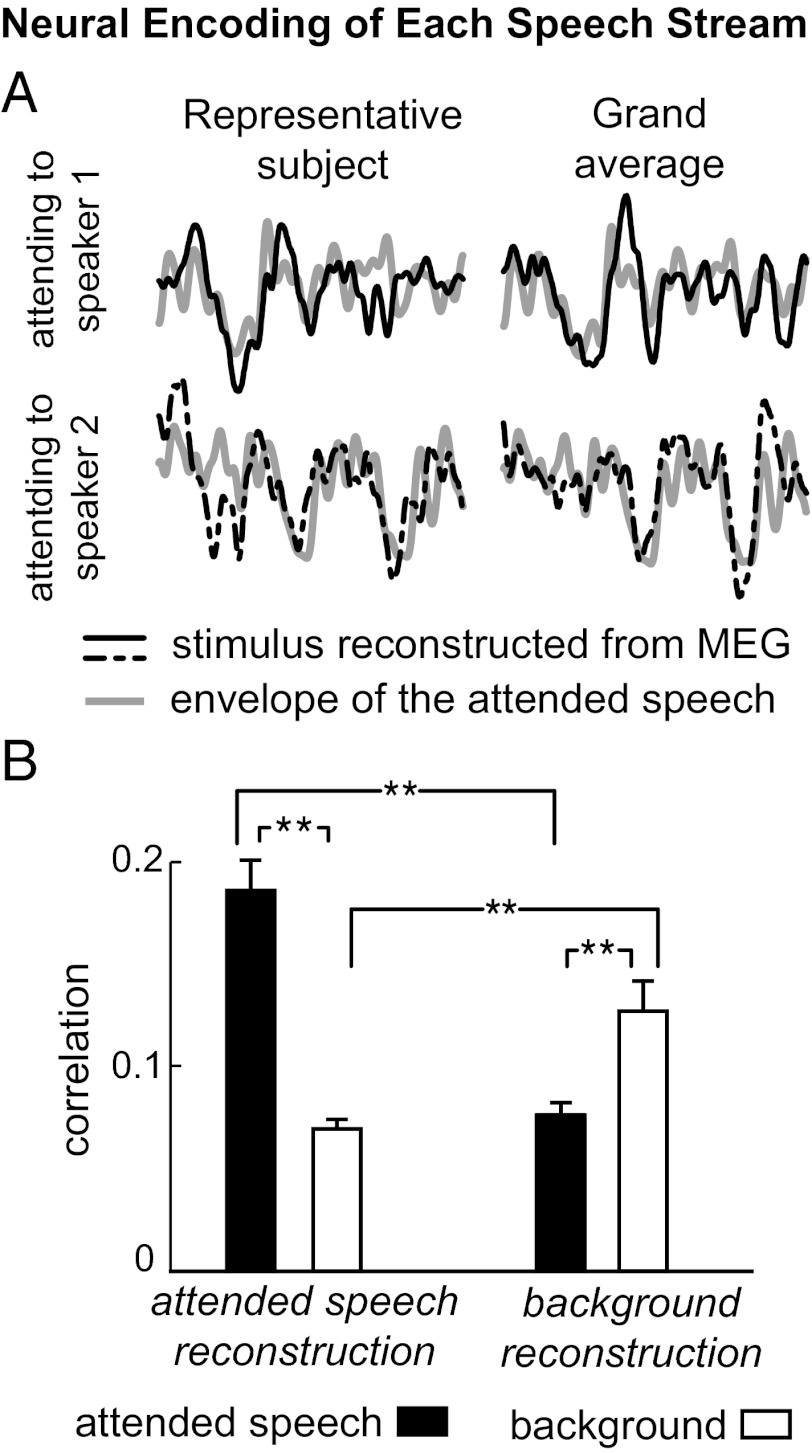
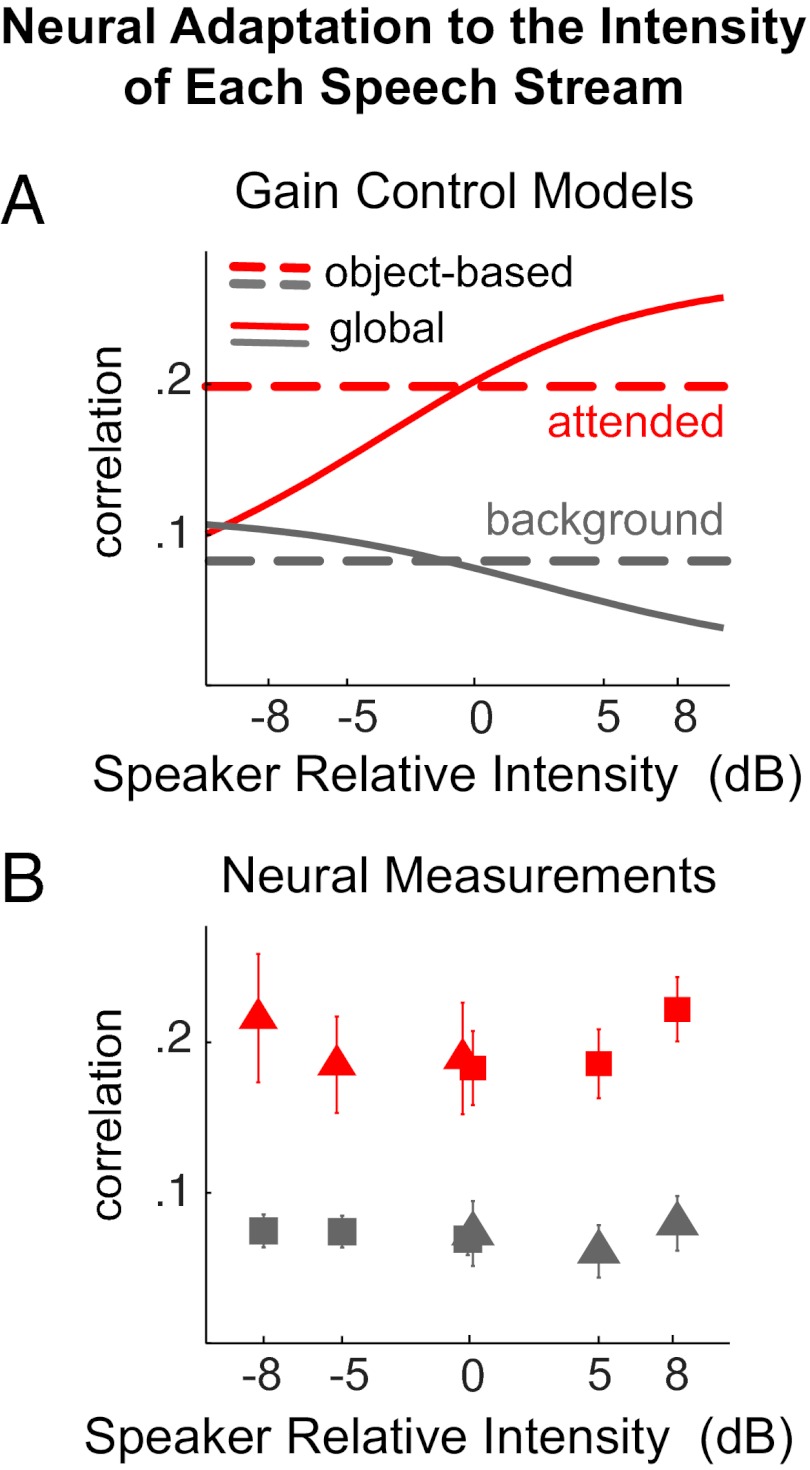
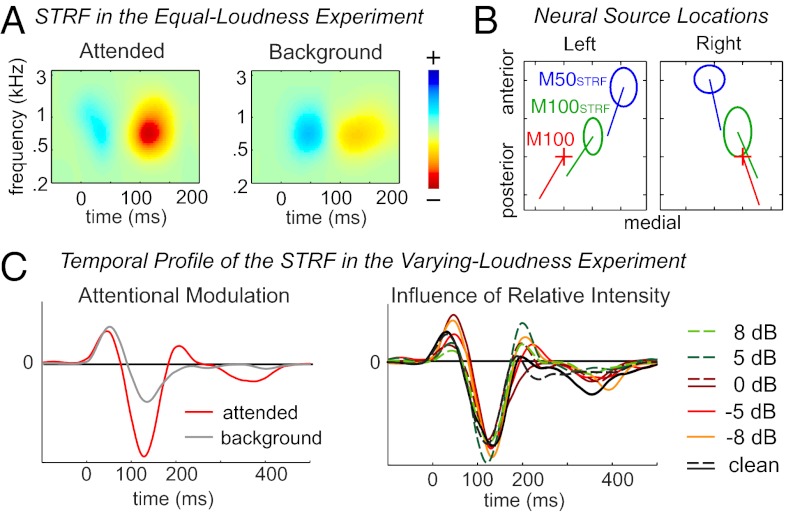
A visual scene is perceived in terms of visual objects. Similar ideas have been proposed for the analogous case of auditory scene analysis, although their hypothesized neural underpinnings have not yet been established. Here, we address this question by recording from subjects selectively listening to one of two competing speakers, either of different or the same sex, using magnetoencephalography. Individual neural representations are seen for the speech of the two speakers, with each being selectively phase locked to the rhythm of the corresponding speech stream and from which can be exclusively reconstructed the temporal envelope of that speech stream. The neural representation of the attended speech dominates responses (with latency near 100 ms) in posterior auditory cortex. Furthermore, when the intensity of the attended and background speakers is separately varied over an 8-dB range, the neural representation of the attended speech adapts only to the intensity of that speaker but not to the intensity of the background speaker, suggesting an object-level intensity gain control. In summary, these results indicate that concurrent auditory objects, even if spectrotemporally overlapping and not resolvable at the auditory periphery, are neurally encoded individually in auditory cortex and emerge as fundamental representational units for top-down attentional modulation and bottom-up neural adaptation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Bregman AS. Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, MA: MIT Press; 1990.
-
- Griffiths TD, Warren JD. What is an auditory object? Nat Rev Neurosci. 2004;5:887–892. - PubMed
-
- Fishman YI, Steinschneider M. Formation of auditory streams. In: Rees A, Palmer A, editors. The Oxford Handbook of Auditory Science: The Auditory Brain. Vol 2. New York: Oxford Univ Press; 2010. pp. 215–245.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous
