

Q-LEARNING WITH CENSORED DATA
- PMID: 22754029
- PMCID: PMC3385950
- DOI: 10.1214/12-AOS968
Q-LEARNING WITH CENSORED DATA
Abstract
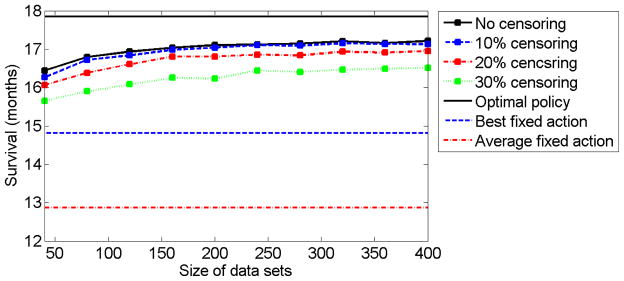
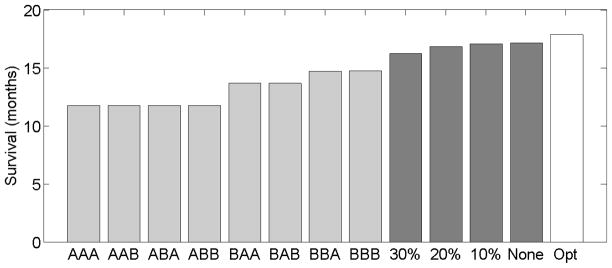
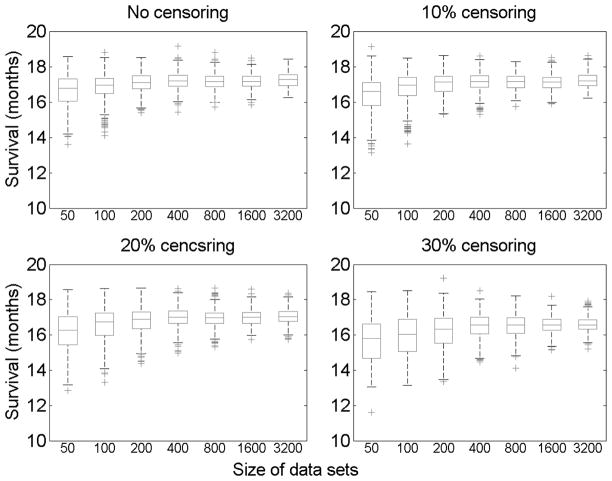
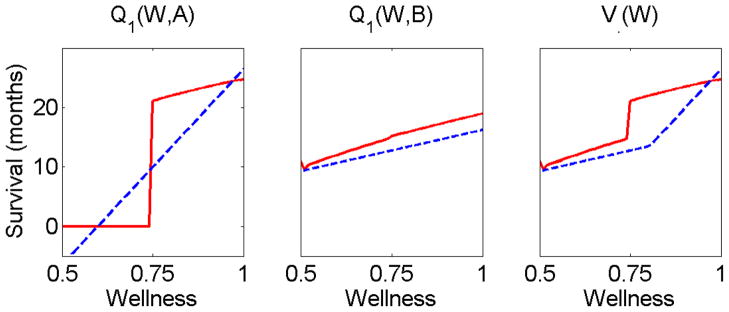
We develop methodology for a multistage-decision problem with flexible number of stages in which the rewards are survival times that are subject to censoring. We present a novel Q-learning algorithm that is adjusted for censored data and allows a flexible number of stages. We provide finite sample bounds on the generalization error of the policy learned by the algorithm, and show that when the optimal Q-function belongs to the approximation space, the expected survival time for policies obtained by the algorithm converges to that of the optimal policy. We simulate a multistage clinical trial with flexible number of stages and apply the proposed censored-Q-learning algorithm to find individualized treatment regimens. The methodology presented in this paper has implications in the design of personalized medicine trials in cancer and in other life-threatening diseases.
Figures
References
-
- Anthony M, Bartlett PL. Neural Network Learning: Theoretical Foundations. Cambridge University Press; 1999.
-
- Bellman R. Dynamic Programming. Princeton University Press; 1957.
-
- Biganzoli E, Boracchi P, Mariani L, Marubini E. Feed forward neural networks for the analysis of censored survival data: A partial logistic regression approach. Statist Med. 1998;17:1169–1186. - PubMed
-
- Bitouzé D, Laurent B, Massart P. A Dvoretzky-Kiefer-Wolfowitz type inequality for the Kaplan-Meier estimator. Ann Inst H Poincaré Probab Statist. 1999;35:735–763.
-
- Chen P, Tsiatis AA. Causal inference on the difference of the restricted mean lifetime between two groups. Biometrics. 2001;57:1030–1038. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources