

Auditory brainstem response to complex sounds predicts self-reported speech-in-noise performance
- PMID: 22761320
- PMCID: PMC3648418
- DOI: 10.1044/1092-4388(2012/12-0043)
Auditory brainstem response to complex sounds predicts self-reported speech-in-noise performance
Abstract
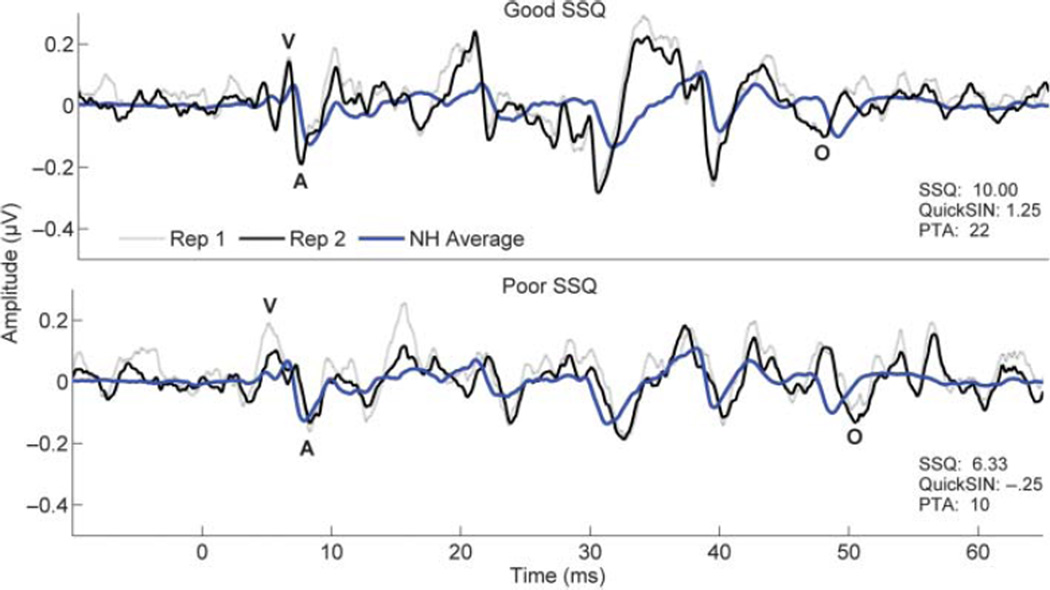
Purpose: To compare the ability of the auditory brainstem response to complex sounds (cABR) to predict subjective ratings of speech understanding in noise on the Speech, Spatial, and Qualities of Hearing Scale (SSQ; Gatehouse & Noble, 2004) relative to the predictive ability of the Quick Speech-in-Noise test (QuickSIN; Killion, Niquette, Gudmundsen, Revit, & Banerjee, 2004) and pure-tone hearing thresholds.
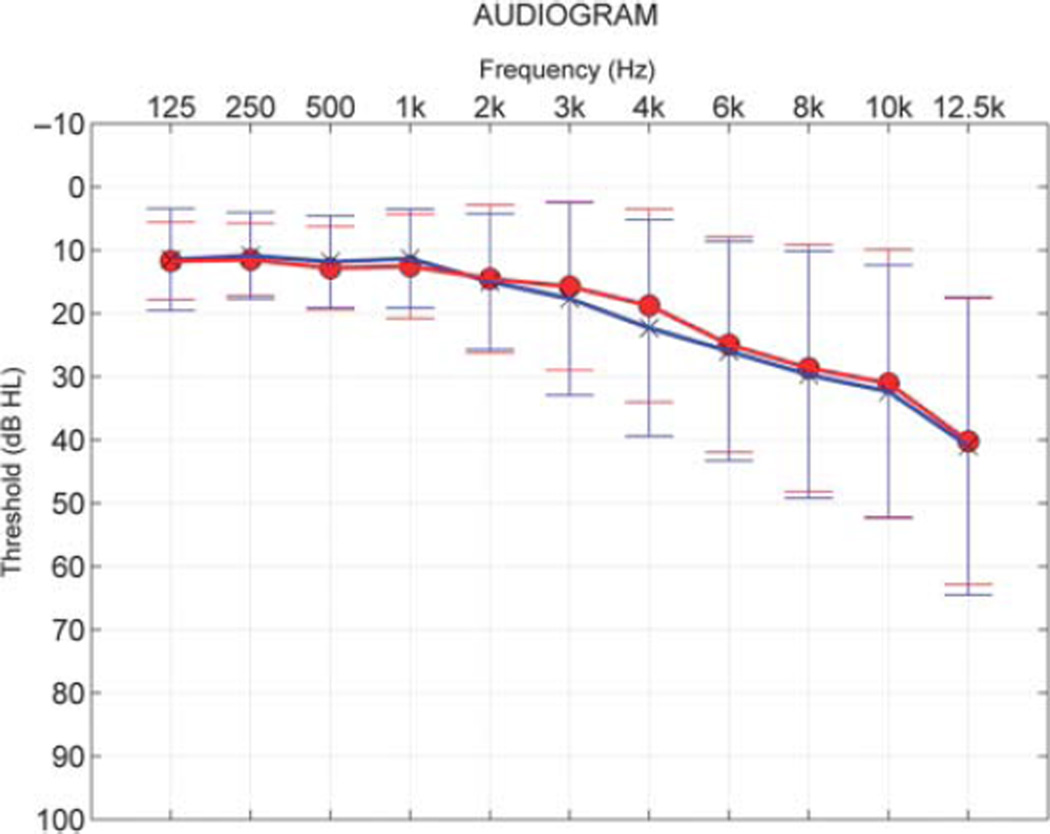
Method: Participants included 111 middle- to older-age adults (range = 45-78) with audiometric configurations ranging from normal hearing levels to moderate sensorineural hearing loss. In addition to using audiometric testing, the authors also used such evaluation measures as the QuickSIN, the SSQ, and the cABR.
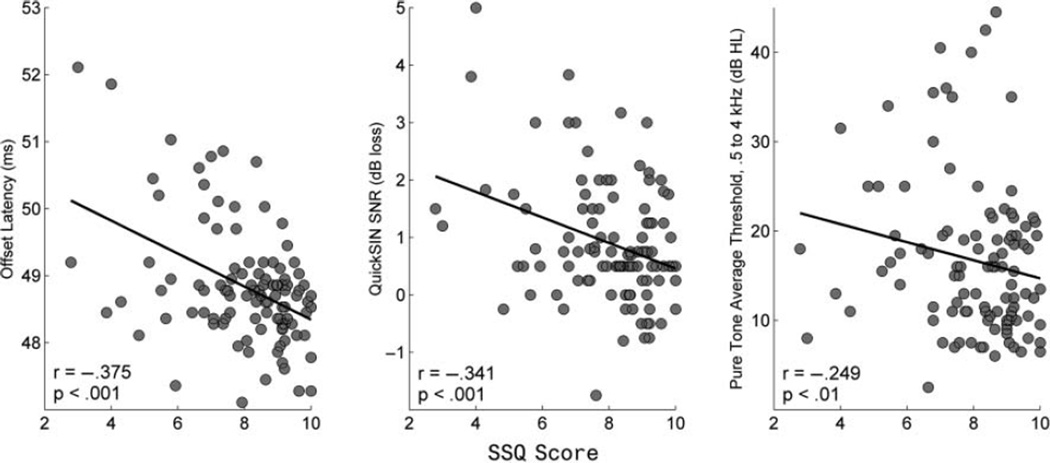
Results: Multiple linear regression analysis indicated that the inclusion of brainstem variables in a model with QuickSIN, hearing thresholds, and age accounted for 30% of the variance in the Speech subtest of the SSQ, compared with significantly less variance (19%) when brainstem variables were not included.
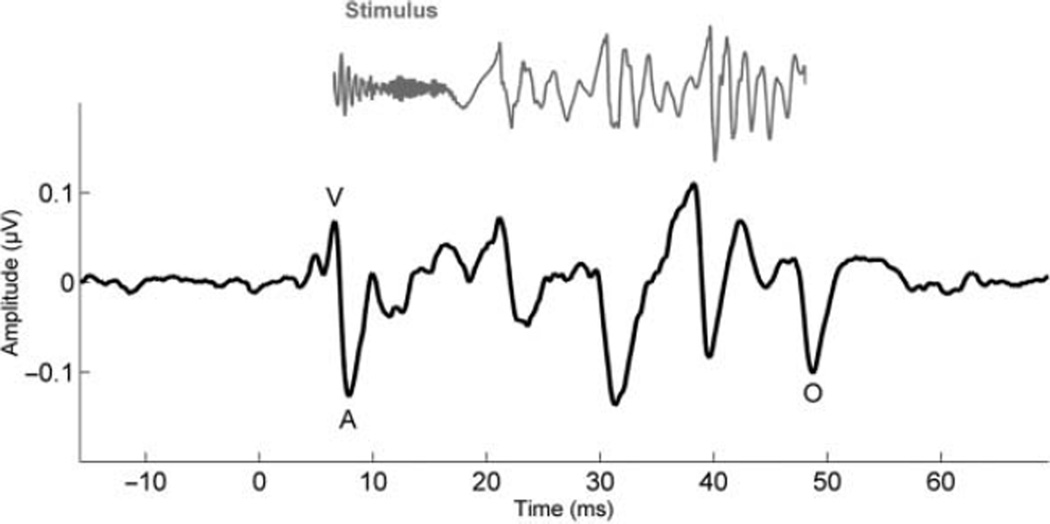
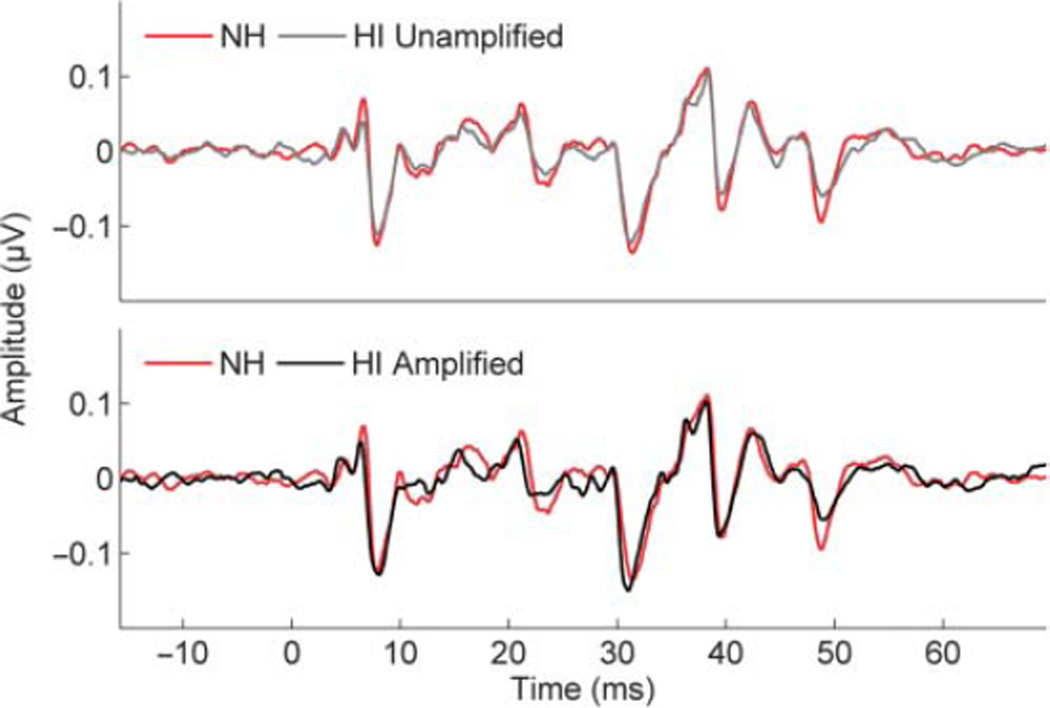
Conclusion: The authors' results demonstrate the cABR's efficacy for predicting self-reported speech-in-noise perception difficulties. The fact that the cABR predicts more variance in self-reported speech-in-noise (SIN) perception than either the QuickSIN or hearing thresholds indicates that the cABR provides additional insight into an individual's ability to hear in background noise. In addition, the findings underscore the link between the cABR and hearing in noise.
Figures
References
-
- Agus TR, Akeroyd MA, Noble W, Bhullar N. An analysis of the masking of speech by competing speech using self-report data. The Journal of the Acoustical Society of America. 2009;125:23–26. - PubMed
-
- Aiken SJ, Picton TW. Envelope and spectral frequency-following responses to vowel sounds. Hearing Research. 2008;245:35–47. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
