

Cyclic peptides arising by evolutionary parallelism via asparaginyl-endopeptidase-mediated biosynthesis
- PMID: 22822203
- PMCID: PMC3426113
- DOI: 10.1105/tpc.112.099085
Cyclic peptides arising by evolutionary parallelism via asparaginyl-endopeptidase-mediated biosynthesis
Abstract
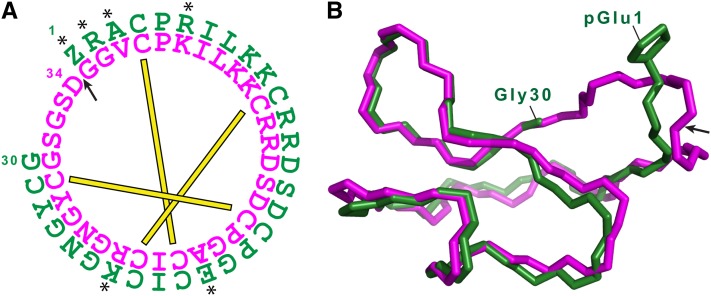
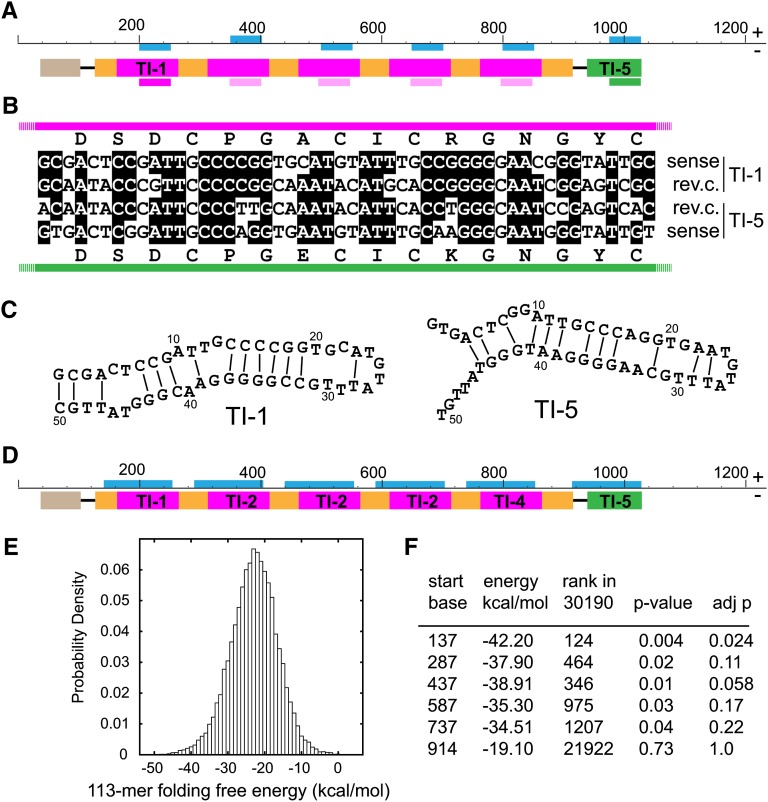
The cyclic miniprotein Momordica cochinchinensis Trypsin Inhibitor II (MCoTI-II) (34 amino acids) is a potent trypsin inhibitor (TI) and a favored scaffold for drug design. We have cloned the corresponding genes and determined that each precursor protein contains a tandem series of cyclic TIs terminating with the more commonly known, and potentially ancestral, acyclic TI. Expression of the precursor protein in Arabidopsis thaliana showed that production of the cyclic TIs, but not the terminal acyclic TI, depends on asparaginyl endopeptidase (AEP) for maturation. The nature of their repetitive sequences and the almost identical structures of emerging TIs suggest these cyclic peptides evolved by internal gene amplification associated with recruitment of AEP for processing between domain repeats. This is the third example of similar AEP-mediated processing of a class of cyclic peptides from unrelated precursor proteins in phylogenetically distant plant families. This suggests that production of cyclic peptides in angiosperms has evolved in parallel using AEP as a constraining evolutionary channel. We believe this is evolutionary evidence that, in addition to its known roles in proteolysis, AEP is especially suited to performing protein cyclization.
Figures




References
-
- Akaike H. (1974). A new look at the statistical model identification. IEEE Trans. Automat. Contr. 19: 716–723
-
- Avrutina O., Schmoldt H.-U., Gabrijelcic-Geiger D., Le Nguyen D., Sommerhoff C.P., Diederichsen U., Kolmar H. (2005). Trypsin inhibition by macrocyclic and open-chain variants of the squash inhibitor MCoTI-II. Biol. Chem. 386: 1301–1306 - PubMed
-
- Bailey T.L., Elkan C. (1994). Fitting a mixture model by expectation maximization to discover motifs in biopolymers. In Proceedings of the Second International Conference on Intelligent Systems for Molecular Biology, R. Altman, D. Brutlag, P. Karp, R. Lathrop, and D. Searls, eds (Menlo Park, CA: AAAI Press), pp. 28–36 - PubMed
-
- Bergmann M., Fruton J.S. (1938). Some synthetic and hydrolytic experiments with chymotrypsin. J. Biol. Chem. 124: 321–329
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
