

The Painful Face - Pain Expression Recognition Using Active Appearance Models
- PMID: 22837587
- PMCID: PMC3402903
- DOI: 10.1016/j.imavis.2009.05.007
The Painful Face - Pain Expression Recognition Using Active Appearance Models
Abstract
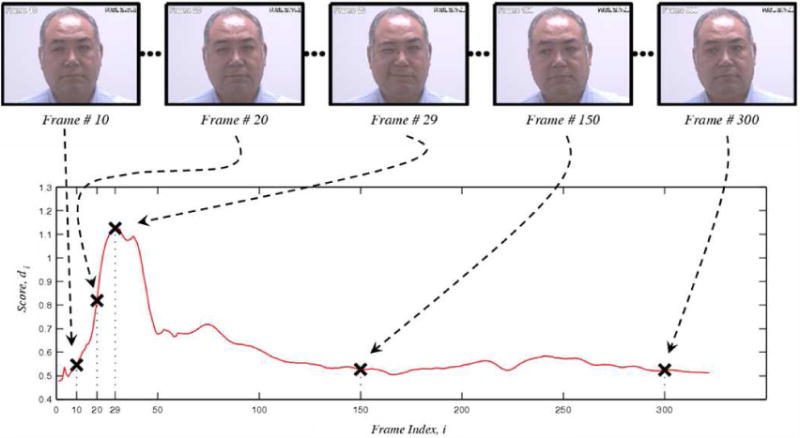
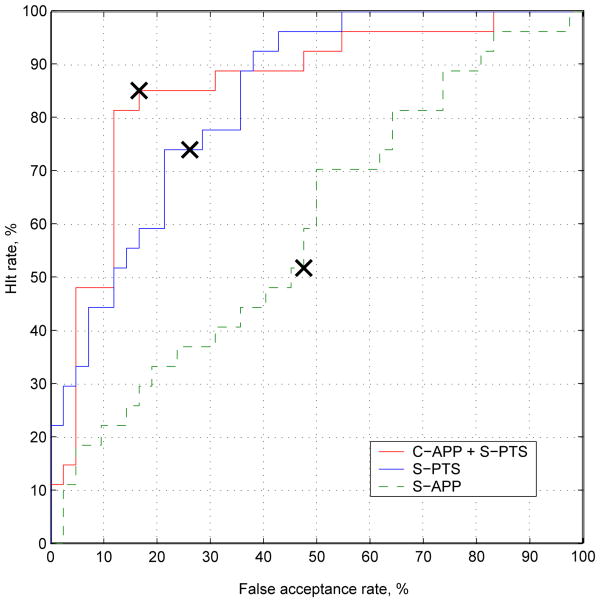
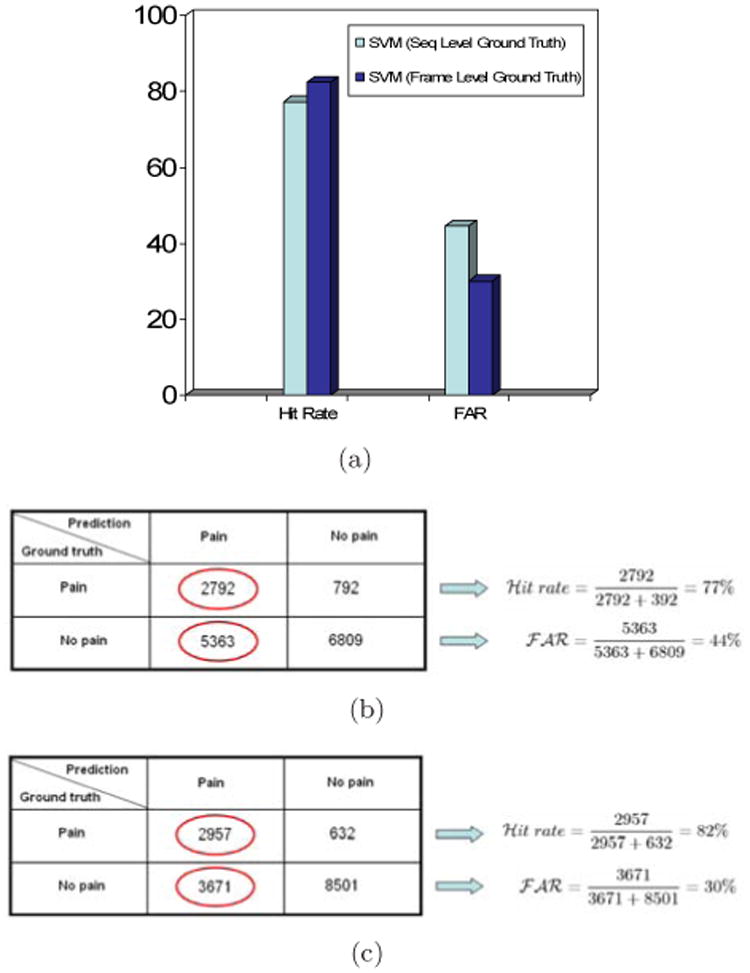
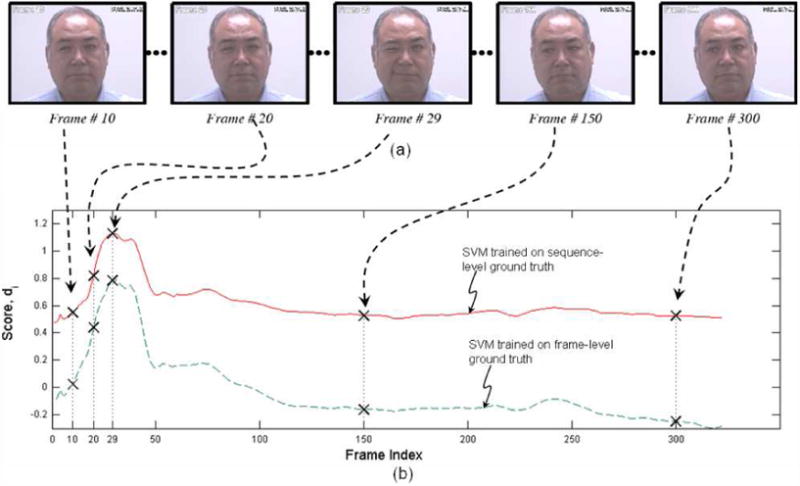
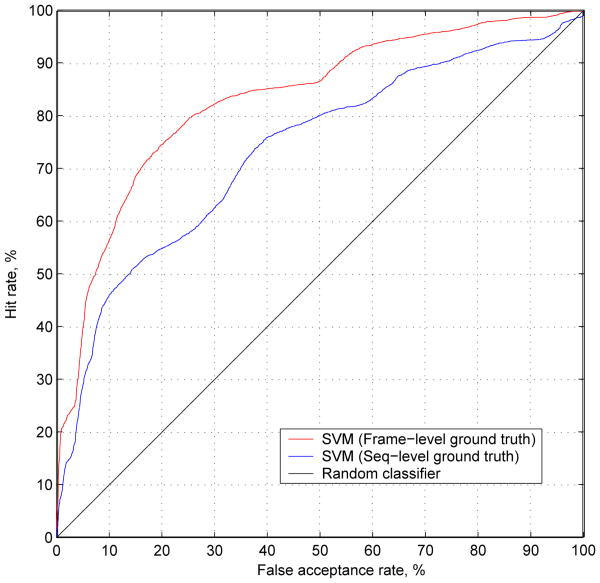
Pain is typically assessed by patient self-report. Self-reported pain, however, is difficult to interpret and may be impaired or in some circumstances (i.e., young children and the severely ill) not even possible. To circumvent these problems behavioral scientists have identified reliable and valid facial indicators of pain. Hitherto, these methods have required manual measurement by highly skilled human observers. In this paper we explore an approach for automatically recognizing acute pain without the need for human observers. Specifically, our study was restricted to automatically detecting pain in adult patients with rotator cuff injuries. The system employed video input of the patients as they moved their affected and unaffected shoulder. Two types of ground truth were considered. Sequence-level ground truth consisted of Likert-type ratings by skilled observers. Frame-level ground truth was calculated from presence/absence and intensity of facial actions previously associated with pain. Active appearance models (AAM) were used to decouple shape and appearance in the digitized face images. Support vector machines (SVM) were compared for several representations from the AAM and of ground truth of varying granularity. We explored two questions pertinent to the construction, design and development of automatic pain detection systems. First, at what level (i.e., sequence- or frame-level) should datasets be labeled in order to obtain satisfactory automatic pain detection performance? Second, how important is it, at both levels of labeling, that we non-rigidly register the face?
Figures


References
-
- Bartlett M, Littlewort G, Lainscesk C, Fasel I, Movellan J. Machine learning methods for fully automatic recognition of facial expressions and facial actions. IEEE International Conference on Systems, Man and Cybernetics. 2004 Oct;:592–597.
-
- Littlewort G, Bartlett M, Lee K. Faces of pain – Automated measurement of spontaneous facial expressions of genuine and posed pain. Proceedings of the 9th international conference on Multimodal interfaces (ICMI) 2007:15–21.
-
- Ashraf AB, Lucey S, Cohn J, Chen T, Ambadar Z, Prkachin K, Solomon P. The Painfule Face – Pain expression recognition using active appearance models. Proceedings of the 9th international conference on Multimodal interfaces (ICMI) 2007:9–14.
-
- Bartlett MS, Littlewort G, Frank M, Lainscesk C, Fasel I, Movellan J. Recognizing facial-expression: Machine learning and application to spontaneous behavior. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2005 Jun;2:568–573.
-
- Bartlett MS, Littlewort G, Frank M, Lainscsek C, Fasel I, Movellan J. Fully automatic facial action recognition in spontaneous behavior. Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition. 2006:223–228.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources