

Musical melody and speech intonation: singing a different tune
- PMID: 22859909
- PMCID: PMC3409119
- DOI: 10.1371/journal.pbio.1001372
Musical melody and speech intonation: singing a different tune
Abstract
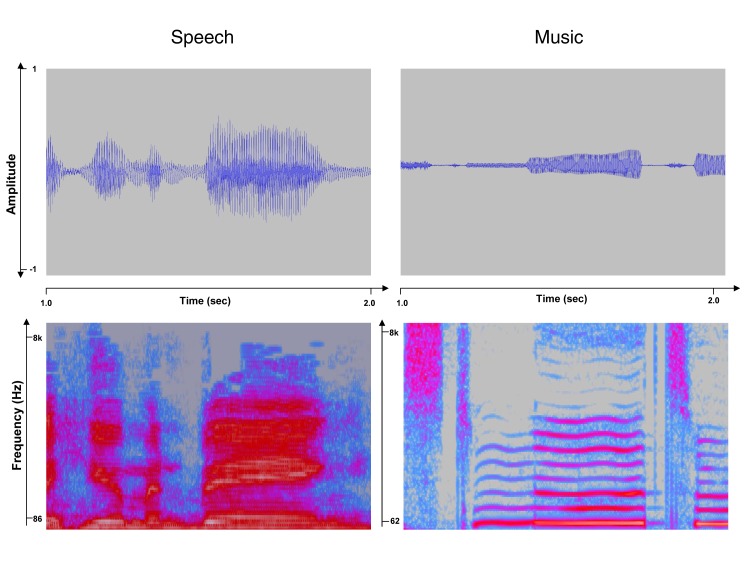
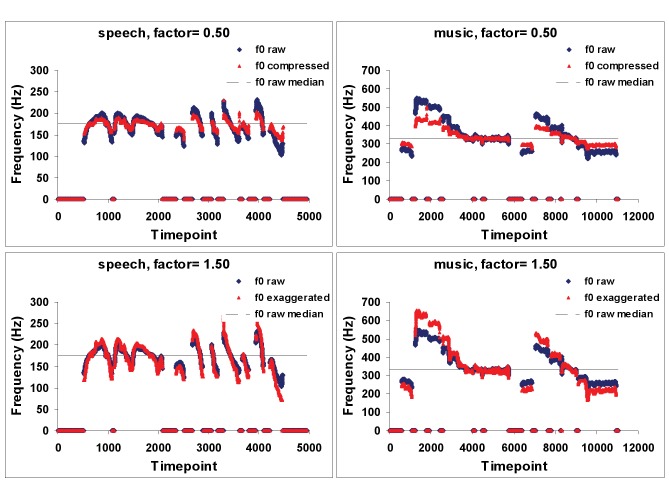
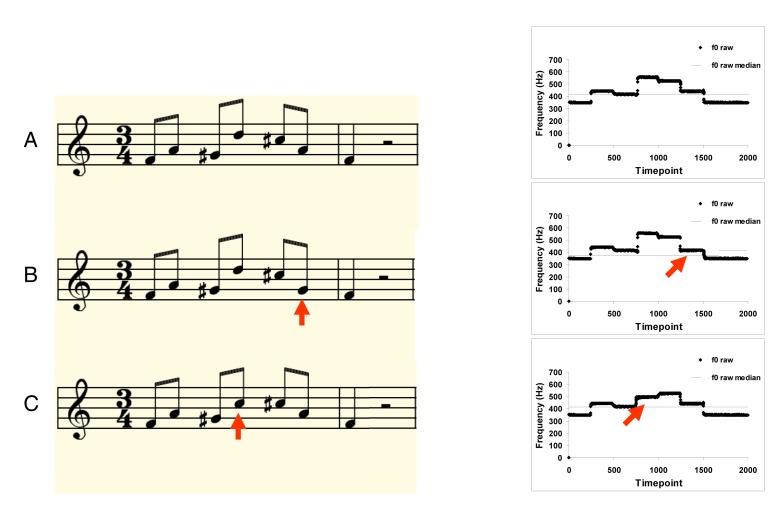
Music and speech are often cited as characteristically human forms of communication. Both share the features of hierarchical structure, complex sound systems, and sensorimotor sequencing demands, and both are used to convey and influence emotions, among other functions [1]. Both music and speech also prominently use acoustical frequency modulations, perceived as variations in pitch, as part of their communicative repertoire. Given these similarities, and the fact that pitch perception and production involve the same peripheral transduction system (cochlea) and the same production mechanism (vocal tract), it might be natural to assume that pitch processing in speech and music would also depend on the same underlying cognitive and neural mechanisms. In this essay we argue that the processing of pitch information differs significantly for speech and music; specifically, we suggest that there are two pitch-related processing systems, one for more coarse-grained, approximate analysis and one for more fine-grained accurate representation, and that the latter is unique to music. More broadly, this dissociation offers clues about the interface between sensory and motor systems, and highlights the idea that multiple processing streams are a ubiquitous feature of neuro-cognitive architectures.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Patel AD (2008) Music, language, and the brain. New York, NY: Oxford University Press.
-
- Deutsch D, Henthorn T, Lapidis R (2011) Illusory transformation from speech to song. Journal of the Acoustical Society of America 129: 2245–2252. - PubMed
-
- Krumhansl CL (1990) Cognitive foundations of musical pitch. New York: Oxford University Press.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
