

Automated motif discovery from glycan array data
- PMID: 22877213
- PMCID: PMC3459425
- DOI: 10.1089/omi.2012.0013
Automated motif discovery from glycan array data
Abstract
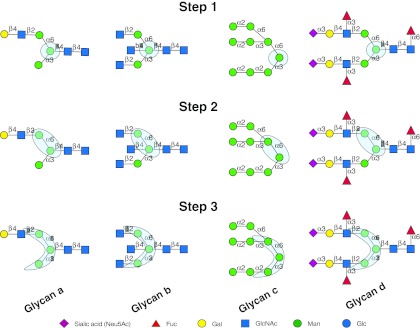
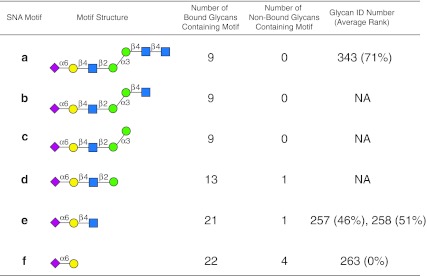
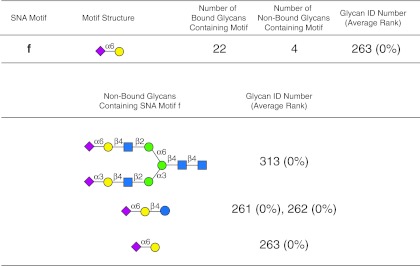
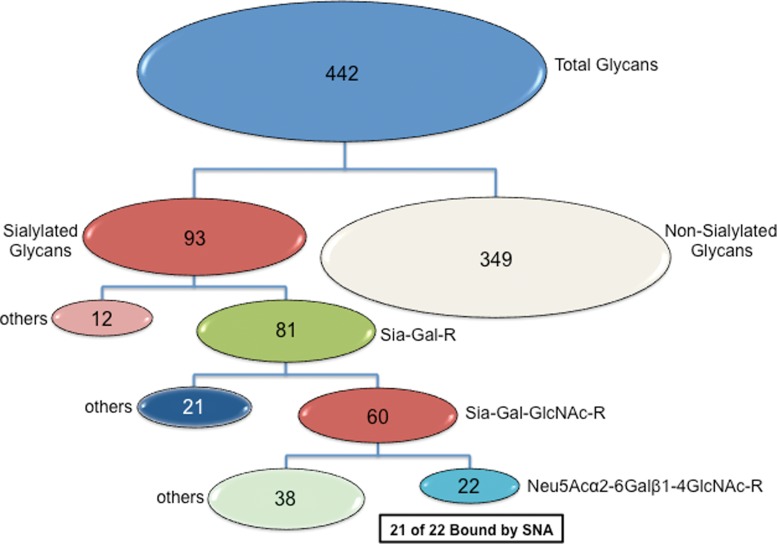
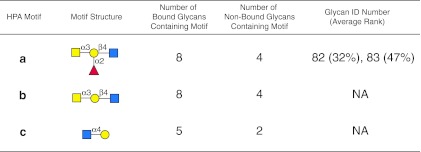
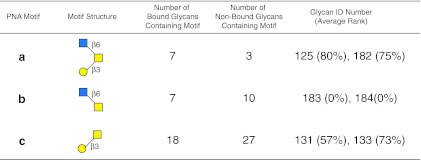
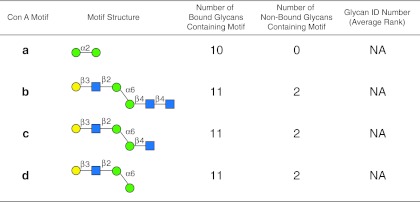
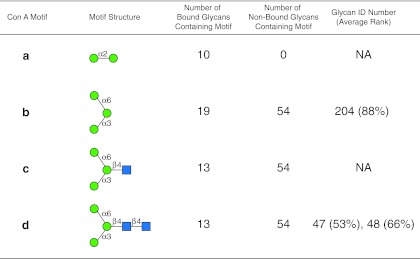
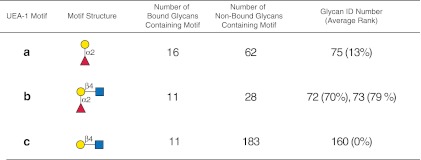
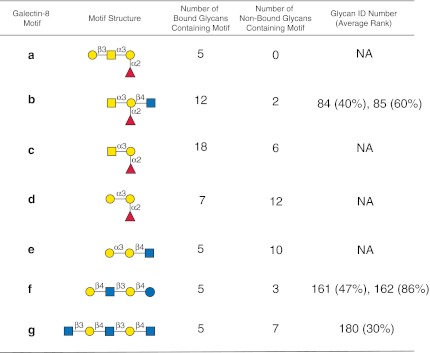
Assessing interactions of a glycan-binding protein (GBP) or lectin with glycans on a microarray generates large datasets, making it difficult to identify a glycan structural motif or determinant associated with the highest apparent binding strength of the GBP. We have developed a computational method, termed GlycanMotifMiner, that uses the relative binding of a GBP with glycans within a glycan microarray to automatically reveal the glycan structural motifs recognized by a GBP. We implemented the software with a web-based graphical interface for users to explore and visualize the discovered motifs. The utility of GlycanMotifMiner was determined using five plant lectins, SNA, HPA, PNA, Con A, and UEA-I. Data from the analyses of the lectins at different protein concentrations were processed to rank the glycans based on their relative binding strengths. The motifs, defined as glycan substructures that exist in a large number of the bound glycans and few non-bound glycans, were then discovered by our algorithm and displayed in a web-based graphical user interface ( http://glycanmotifminer.emory.edu ). The information is used in defining the glycan-binding specificity of GBPs. The results were compared to the known glycan specificities of these lectins generated by manual methods. A more complex analysis was also carried out using glycan microarray data obtained for a recombinant form of human galectin-8. Results for all of these lectins show that GlycanMotifMiner identified the major motifs known in the literature along with some unexpected novel binding motifs.
Figures

Similar articles
-
Global comparisons of lectin-glycan interactions using a database of analyzed glycan array data.Mol Cell Proteomics. 2013 Apr;12(4):1026-35. doi: 10.1074/mcp.M112.026641. Epub 2013 Feb 11. Mol Cell Proteomics. 2013. PMID: 23399549 Free PMC article.
-
MCAW-DB: A glycan profile database capturing the ambiguity of glycan recognition patterns.Carbohydr Res. 2018 Jul 15;464:44-56. doi: 10.1016/j.carres.2018.05.003. Epub 2018 May 11. Carbohydr Res. 2018. PMID: 29859376
-
Use of glycan microarrays to explore specificity of glycan-binding proteins.Methods Enzymol. 2010;480:417-44. doi: 10.1016/S0076-6879(10)80033-3. Methods Enzymol. 2010. PMID: 20816220 Review.
-
The fine specificity of mannose-binding and galactose-binding lectins revealed using outlier motif analysis of glycan array data.Glycobiology. 2012 Jan;22(1):160-9. doi: 10.1093/glycob/cwr128. Epub 2011 Aug 29. Glycobiology. 2012. PMID: 21875884 Free PMC article.
-
Glycan microarrays for decoding the glycome.Annu Rev Biochem. 2011;80:797-823. doi: 10.1146/annurev-biochem-061809-152236. Annu Rev Biochem. 2011. PMID: 21469953 Free PMC article. Review.
Cited by
-
Global comparisons of lectin-glycan interactions using a database of analyzed glycan array data.Mol Cell Proteomics. 2013 Apr;12(4):1026-35. doi: 10.1074/mcp.M112.026641. Epub 2013 Feb 11. Mol Cell Proteomics. 2013. PMID: 23399549 Free PMC article.
-
Using graph convolutional neural networks to learn a representation for glycans.Cell Rep. 2021 Jun 15;35(11):109251. doi: 10.1016/j.celrep.2021.109251. Cell Rep. 2021. PMID: 34133929 Free PMC article.
-
Identifying glycan motifs using a novel subtree mining approach.BMC Bioinformatics. 2020 Feb 4;21(1):42. doi: 10.1186/s12859-020-3374-4. BMC Bioinformatics. 2020. PMID: 32019496 Free PMC article.
-
Glycomics and glycoproteomics of viruses: Mass spectrometry applications and insights toward structure-function relationships.Mass Spectrom Rev. 2020 Jul;39(4):371-409. doi: 10.1002/mas.21629. Epub 2020 Apr 29. Mass Spectrom Rev. 2020. PMID: 32350911 Free PMC article. Review.
-
GlycoPattern: a web platform for glycan array mining.Bioinformatics. 2014 Dec 1;30(23):3417-8. doi: 10.1093/bioinformatics/btu559. Epub 2014 Aug 20. Bioinformatics. 2014. PMID: 25143288 Free PMC article.
References
-
- Baenziger J.U. Fiete D. Structural determinants of concanavalin A specificity for oligosaccharides. J Biol Chem. 1979;254:2400–2407. - PubMed
-
- Baldus S.E. Thiele J. Park Y.O. Hanisch F.G. Bara J. Fischer R. Characterization of the binding specificity of Anguilla anguilla agglutinin (AAA) in comparison to Ulex europaeus agglutinin I (UEA-I) Glycoconj J. 1996;13:585–590. - PubMed
-
- Bird G.W. Anti-T in Peanuts. Vox Sang. 1964;9:748–749. - PubMed
-
- Carlsson S. Oberg C.T. Carlsson M.C., et al. Affinity of galectin-8 and its carbohydrate recognition domains for ligands in solution and at the cell surface. Glycobiology. 2007;17:663–676. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
