

Spectrotemporal contrast kernels for neurons in primary auditory cortex
- PMID: 22895711
- PMCID: PMC3542625
- DOI: 10.1523/JNEUROSCI.1715-12.2012
Spectrotemporal contrast kernels for neurons in primary auditory cortex
Abstract
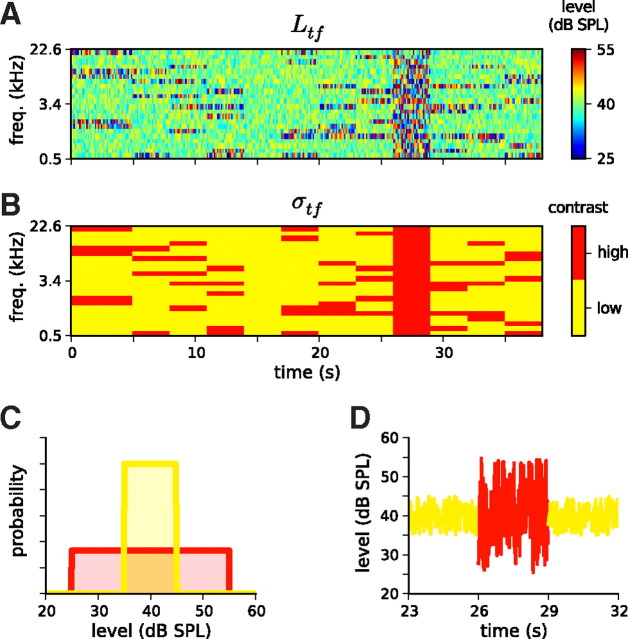
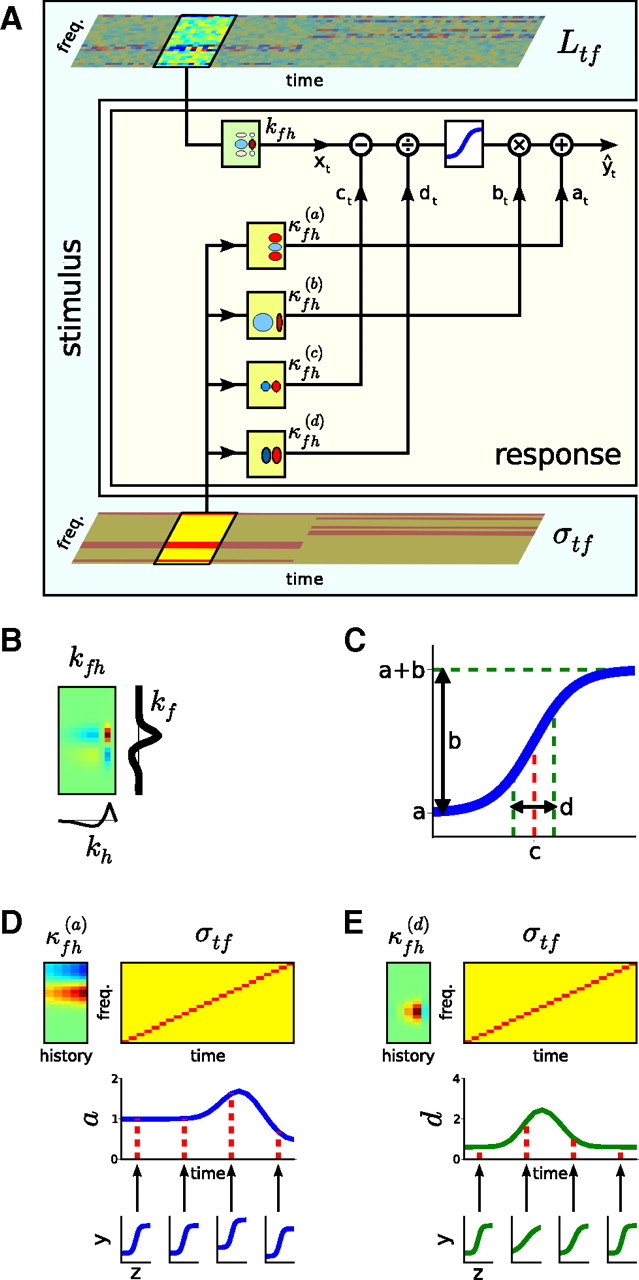
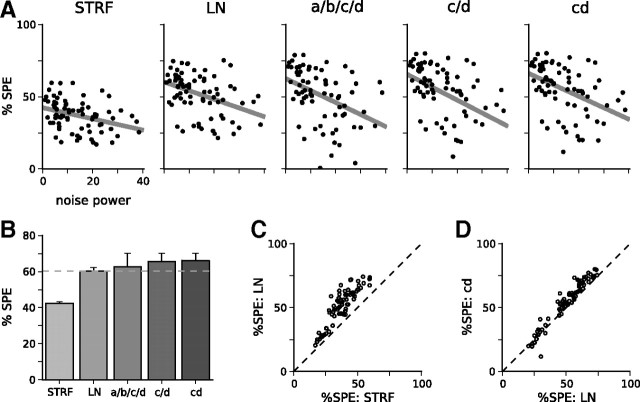
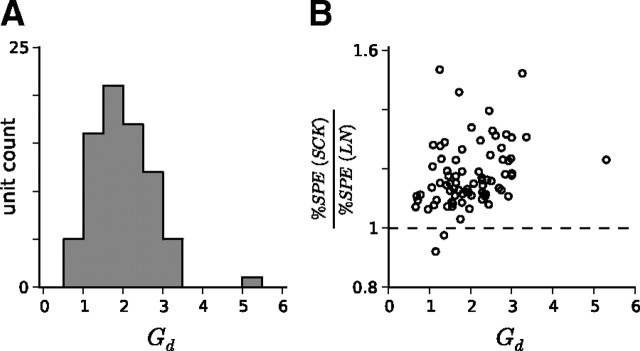
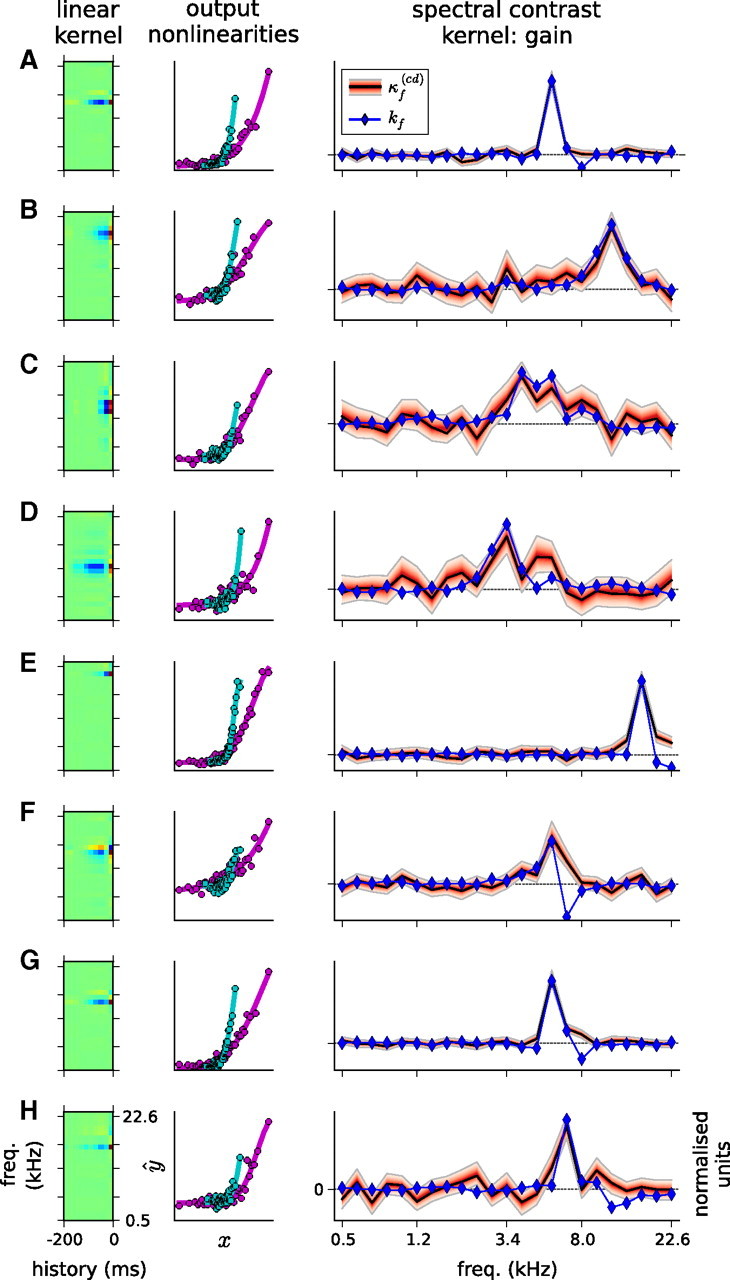
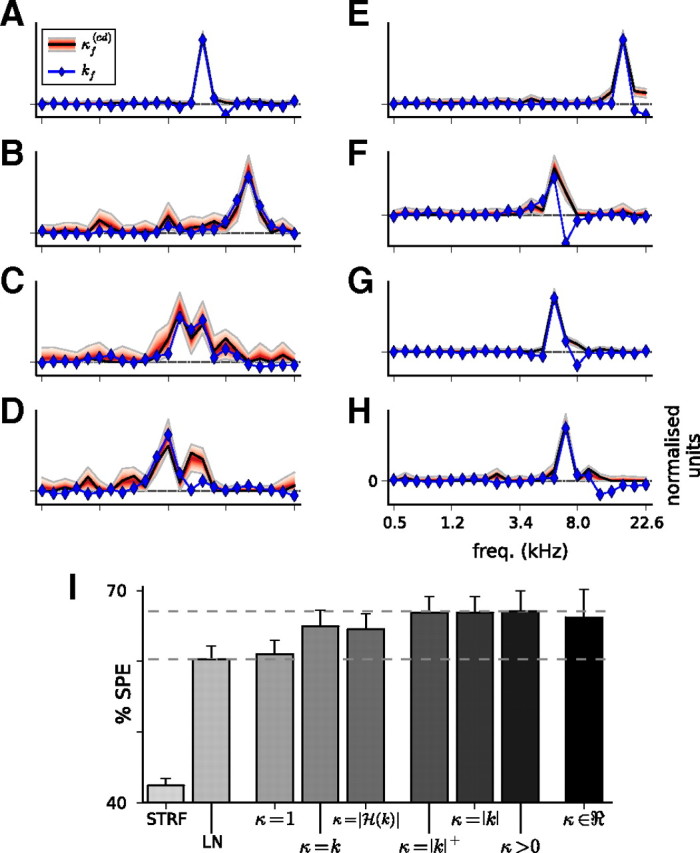
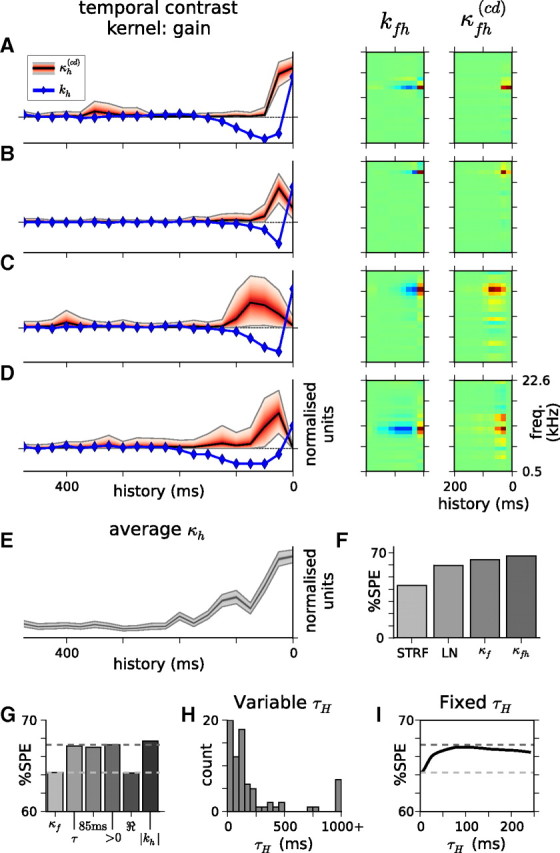
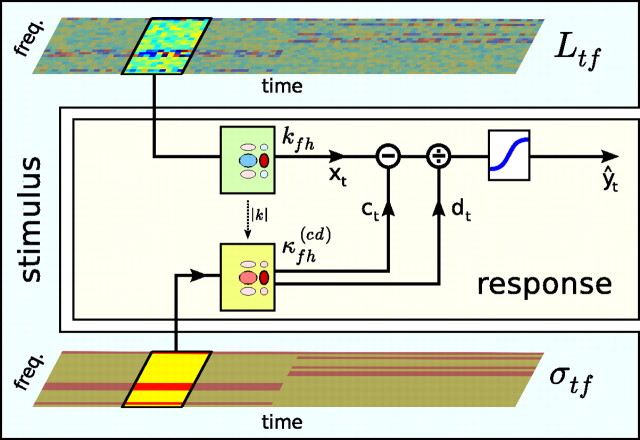
Auditory neurons are often described in terms of their spectrotemporal receptive fields (STRFs). These map the relationship between features of the sound spectrogram and firing rates of neurons. Recently, we showed that neurons in the primary fields of the ferret auditory cortex are also subject to gain control: when sounds undergo smaller fluctuations in their level over time, the neurons become more sensitive to small-level changes (Rabinowitz et al., 2011). Just as STRFs measure the spectrotemporal features of a sound that lead to changes in the firing rates of neurons, in this study, we sought to estimate the spectrotemporal regions in which sound statistics lead to changes in the gain of neurons. We designed a set of stimuli with complex contrast profiles to characterize these regions. This allowed us to estimate the STRFs of cortical neurons alongside a set of spectrotemporal contrast kernels. We find that these two sets of integration windows match up: the extent to which a stimulus feature causes the firing rate of a neuron to change is strongly correlated with the extent to which the contrast of that feature modulates the gain of the neuron. Adding contrast kernels to STRF models also yields considerable improvements in the ability to capture and predict how auditory cortical neurons respond to statistically complex sounds.
Figures
Similar articles
-
Sparse high-dimensional decomposition of non-primary auditory cortical receptive fields.PLoS Comput Biol. 2025 Jan 2;21(1):e1012721. doi: 10.1371/journal.pcbi.1012721. eCollection 2025 Jan. PLoS Comput Biol. 2025. PMID: 39746112 Free PMC article.
-
Plasticity of Multidimensional Receptive Fields in Core Rat Auditory Cortex Directed by Sound Statistics.Neuroscience. 2021 Jul 15;467:150-170. doi: 10.1016/j.neuroscience.2021.04.028. Epub 2021 May 2. Neuroscience. 2021. PMID: 33951506 Free PMC article.
-
Network Receptive Field Modeling Reveals Extensive Integration and Multi-feature Selectivity in Auditory Cortical Neurons.PLoS Comput Biol. 2016 Nov 11;12(11):e1005113. doi: 10.1371/journal.pcbi.1005113. eCollection 2016 Nov. PLoS Comput Biol. 2016. PMID: 27835647 Free PMC article.
-
Does attention play a role in dynamic receptive field adaptation to changing acoustic salience in A1?Hear Res. 2007 Jul;229(1-2):186-203. doi: 10.1016/j.heares.2007.01.009. Epub 2007 Jan 16. Hear Res. 2007. PMID: 17329048 Free PMC article. Review.
-
Context dependence of spectro-temporal receptive fields with implications for neural coding.Hear Res. 2011 Jan;271(1-2):123-32. doi: 10.1016/j.heares.2010.01.014. Epub 2010 Feb 1. Hear Res. 2011. PMID: 20123121 Review.
Cited by
-
Subcortical origin of nonlinear sound encoding in auditory cortex.Curr Biol. 2024 Aug 5;34(15):3405-3415.e5. doi: 10.1016/j.cub.2024.06.057. Epub 2024 Jul 19. Curr Biol. 2024. PMID: 39032492 Free PMC article.
-
Sparse identification of contrast gain control in the fruit fly photoreceptor and amacrine cell layer.J Math Neurosci. 2020 Feb 12;10(1):3. doi: 10.1186/s13408-020-0080-5. J Math Neurosci. 2020. PMID: 32052209 Free PMC article.
-
The Essential Complexity of Auditory Receptive Fields.PLoS Comput Biol. 2015 Dec 18;11(12):e1004628. doi: 10.1371/journal.pcbi.1004628. eCollection 2015 Dec. PLoS Comput Biol. 2015. PMID: 26683490 Free PMC article.
-
Contextual modulation of sound processing in the auditory cortex.Curr Opin Neurobiol. 2018 Apr;49:8-15. doi: 10.1016/j.conb.2017.10.012. Epub 2017 Nov 7. Curr Opin Neurobiol. 2018. PMID: 29125987 Free PMC article. Review.
-
Distinct Spatiotemporal Response Properties of Excitatory Versus Inhibitory Neurons in the Mouse Auditory Cortex.Cereb Cortex. 2016 Oct 17;26(11):4242-4252. doi: 10.1093/cercor/bhw266. Cereb Cortex. 2016. PMID: 27600839 Free PMC article.
References
-
- Abolafia JM, Vergara R, Arnold MM, Reig R, Sanchez-Vives MV. Cortical auditory adaptation in the awake rat and the role of potassium currents. Cereb Cortex. 2011;21:977–990. - PubMed
-
- Aertsen AM, Johannesma PI. The spectro-temporal receptive field. Biol Cybern. 1981;42:133–143. - PubMed
-
- Aertsen AM, Johannesma PI, Hermes DJ. Spectro-temporal receptive fields of auditory neurons in the grassfrog. II. Analysis of the stimulus-event relation for tonal stimuli. Biol Cybern. 1980;38:235–248. - PubMed
-
- Ahrens MB, Paninski L, Sahani M. Inferring input nonlinearities in neural encoding models. Network. 2008b;19:35–67. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources