

A combinatorial amino acid code for RNA recognition by pentatricopeptide repeat proteins
- PMID: 22916040
- PMCID: PMC3420917
- DOI: 10.1371/journal.pgen.1002910
A combinatorial amino acid code for RNA recognition by pentatricopeptide repeat proteins
Abstract
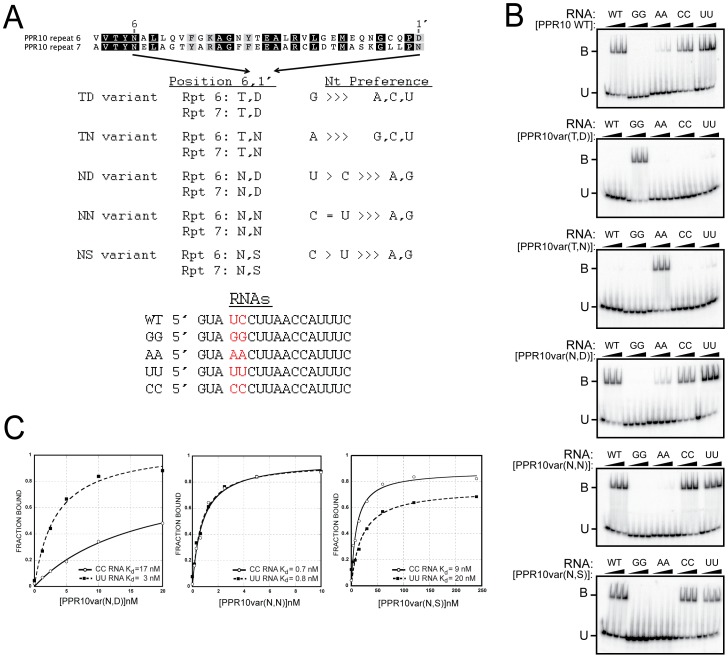
The pentatricopeptide repeat (PPR) is a helical repeat motif found in an exceptionally large family of RNA-binding proteins that functions in mitochondrial and chloroplast gene expression. PPR proteins harbor between 2 and 30 repeats and typically bind single-stranded RNA in a sequence-specific fashion. However, the basis for sequence-specific RNA recognition by PPR tracts has been unknown. We used computational methods to infer a code for nucleotide recognition involving two amino acids in each repeat, and we validated this model by recoding a PPR protein to bind novel RNA sequences in vitro. Our results show that PPR tracts bind RNA via a modular recognition mechanism that differs from previously described RNA-protein recognition modes and that underpins a natural library of specific protein/RNA partners of unprecedented size and diversity. These findings provide a significant step toward the prediction of native binding sites of the enormous number of PPR proteins found in nature. Furthermore, the extraordinary evolutionary plasticity of the PPR family suggests that the PPR scaffold will be particularly amenable to redesign for new sequence specificities and functions.
Conflict of interest statement
The authors have submitted a provisional patent application that is based on this work. In addition, the authors have grant funding that supports this research.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
