

Invariant object recognition based on extended fragments
- PMID: 22936910
- PMCID: PMC3426810
- DOI: 10.3389/fncom.2012.00056
Invariant object recognition based on extended fragments
Abstract
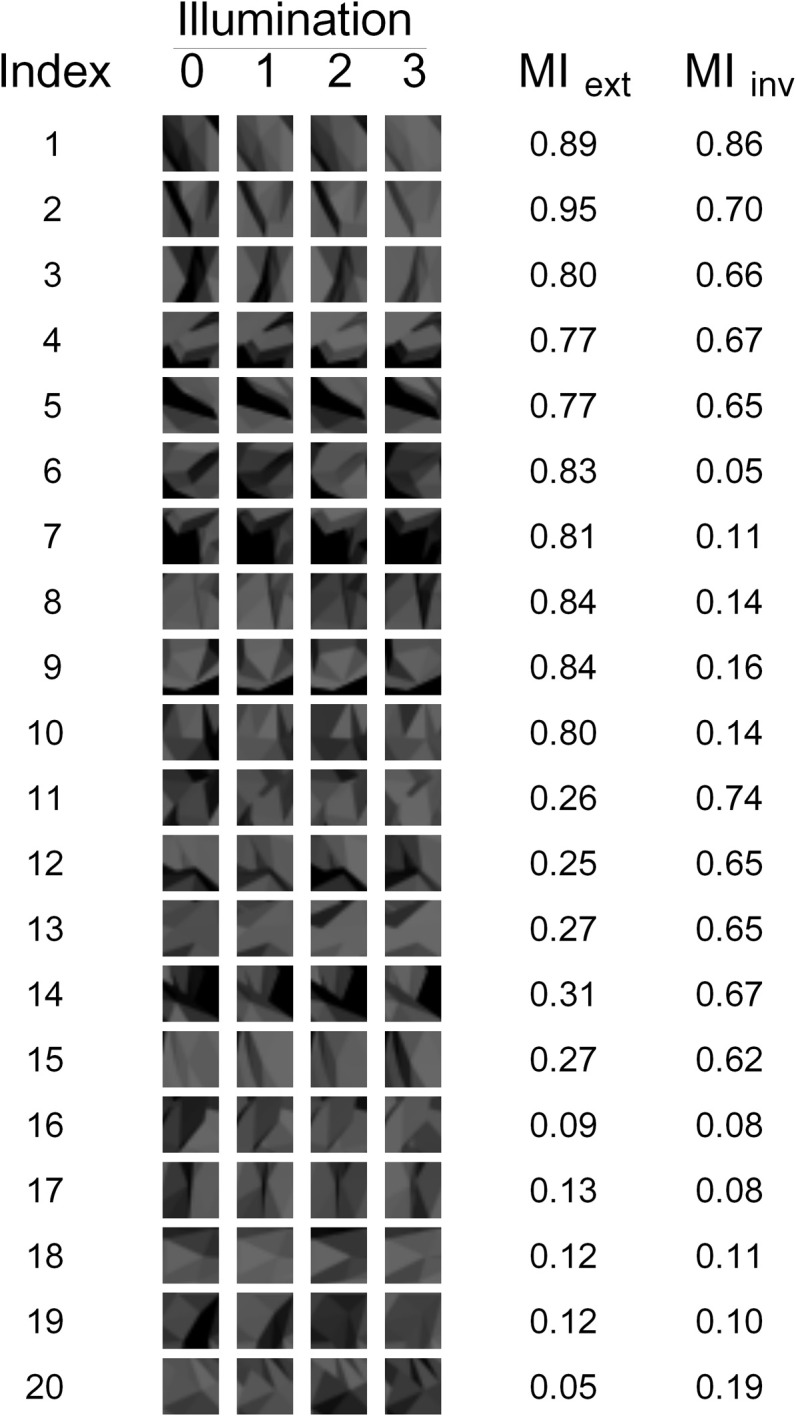
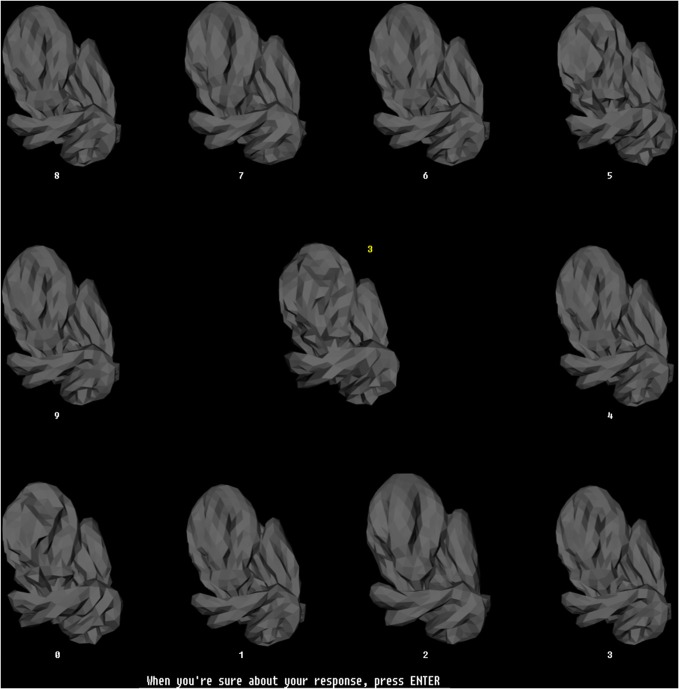
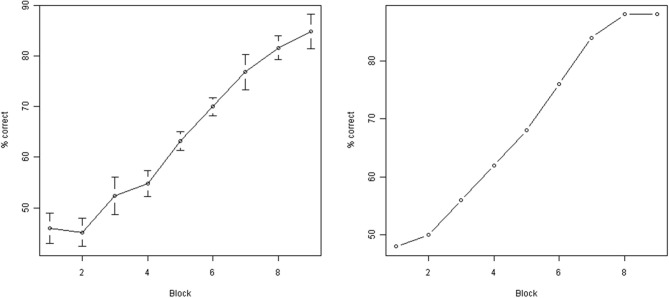
Visual appearance of natural objects is profoundly affected by viewing conditions such as viewpoint and illumination. Human subjects can nevertheless compensate well for variations in these viewing conditions. The strategies that the visual system uses to accomplish this are largely unclear. Previous computational studies have suggested that in principle, certain types of object fragments (rather than whole objects) can be used for invariant recognition. However, whether the human visual system is actually capable of using this strategy remains unknown. Here, we show that human observers can achieve illumination invariance by using object fragments that carry the relevant information. To determine this, we have used novel, but naturalistic, 3-D visual objects called "digital embryos." Using novel instances of whole embryos, not fragments, we trained subjects to recognize individual embryos across illuminations. We then tested the illumination-invariant object recognition performance of subjects using fragments. We found that the performance was strongly correlated with the mutual information (MI) of the fragments, provided that MI value took variations in illumination into consideration. This correlation was not attributable to any systematic differences in task difficulty between different fragments. These results reveal two important principles of invariant object recognition. First, the subjects can achieve invariance at least in part by compensating for the changes in the appearance of small local features, rather than of whole objects. Second, the subjects do not always rely on generic or pre-existing invariance of features (i.e., features whose appearance remains largely unchanged by variations in illumination), and are capable of using learning to compensate for appearance changes when necessary. These psychophysical results closely fit the predictions of earlier computational studies of fragment-based invariant object recognition.
Keywords: form vision; illumination constancy; informative fragments; invariant recognition; mutual information.
Figures






Similar articles
-
Recognition invariance obtained by extended and invariant features.Neural Netw. 2004 Jun-Jul;17(5-6):833-48. doi: 10.1016/j.neunet.2004.01.006. Neural Netw. 2004. PMID: 15288901
-
Object similarity affects the perceptual strategy underlying invariant visual object recognition in rats.Front Neural Circuits. 2015 Mar 12;9:10. doi: 10.3389/fncir.2015.00010. eCollection 2015. Front Neural Circuits. 2015. PMID: 25814936 Free PMC article.
-
Creating objects and object categories for studying perception and perceptual learning.J Vis Exp. 2012 Nov 2;(69):e3358. doi: 10.3791/3358. J Vis Exp. 2012. PMID: 23149420 Free PMC article.
-
Achieving visual object constancy across plane rotation and depth rotation.Acta Psychol (Amst). 1999 Sep;102(2-3):221-45. doi: 10.1016/s0001-6918(98)00052-3. Acta Psychol (Amst). 1999. PMID: 10504882 Review.
-
Invariant visual object recognition and shape processing in rats.Behav Brain Res. 2015 May 15;285:10-33. doi: 10.1016/j.bbr.2014.12.053. Epub 2015 Jan 2. Behav Brain Res. 2015. PMID: 25561421 Free PMC article. Review.
Cited by
-
Sparsey™: event recognition via deep hierarchical sparse distributed codes.Front Comput Neurosci. 2014 Dec 15;8:160. doi: 10.3389/fncom.2014.00160. eCollection 2014. Front Comput Neurosci. 2014. PMID: 25566046 Free PMC article.
-
Invariant recognition of visual objects: some emerging computational principles.Front Comput Neurosci. 2012 Aug 24;6:60. doi: 10.3389/fncom.2012.00060. eCollection 2012. Front Comput Neurosci. 2012. PMID: 22936911 Free PMC article. No abstract available.
References
-
- Bart E., Byvatov E., Ullman S. (2004). View-invariant recognition using corresponding object fragments, in Proceedings ECCV, Part II, (New York, NY: Springer-Verlag; ), 152–165
-
- Biederman I., Cooper E. E. (2009). Translational and reflectional priming invariance: a retrospective. Perception 38, 809–817 - PubMed
-
- Brady M. J., Kersten D. (2003). Bootstrapped learning of novel objects. J. Vis. 3, 413–422 - PubMed
LinkOut - more resources
Full Text Sources