

The GENCODE pseudogene resource
- PMID: 22951037
- PMCID: PMC3491395
- DOI: 10.1186/gb-2012-13-9-r51
The GENCODE pseudogene resource
Abstract
Background: Pseudogenes have long been considered as nonfunctional genomic sequences. However, recent evidence suggests that many of them might have some form of biological activity, and the possibility of functionality has increased interest in their accurate annotation and integration with functional genomics data.
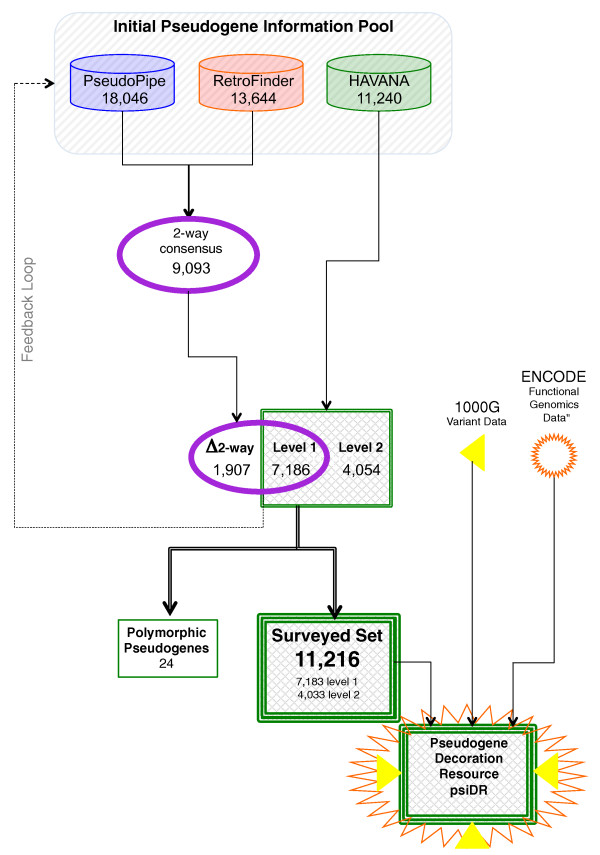
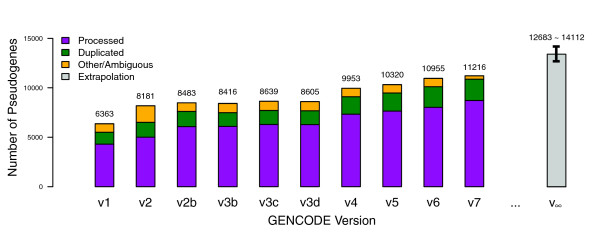
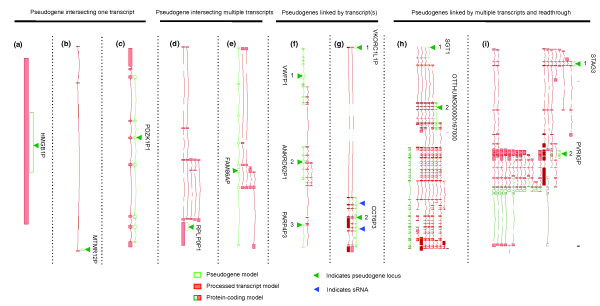
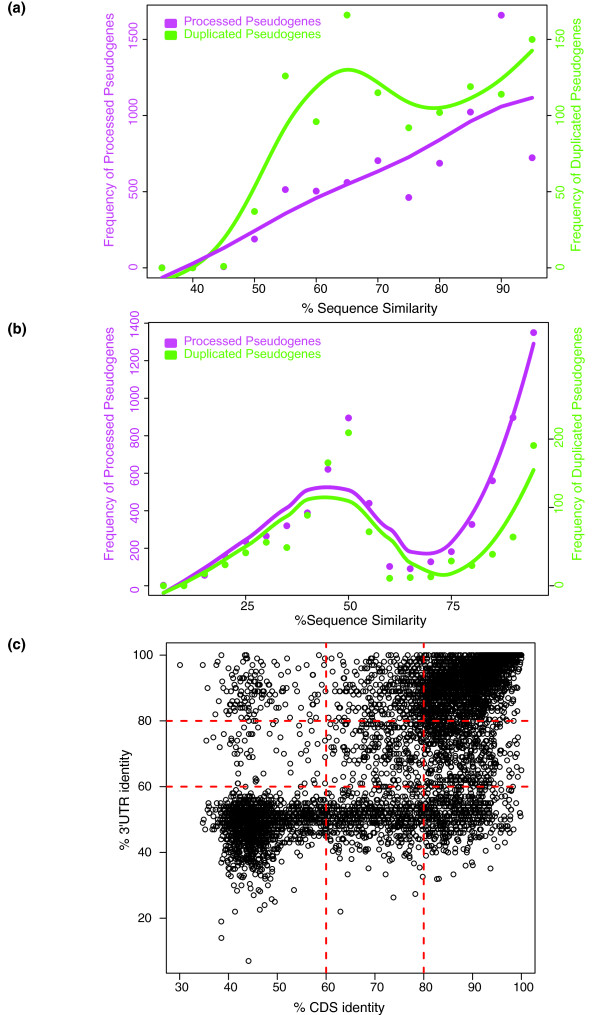
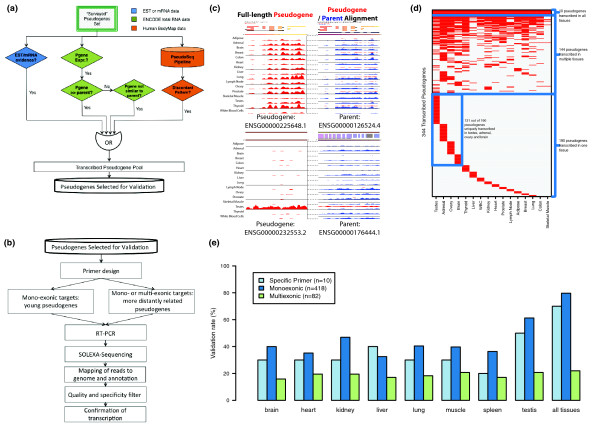
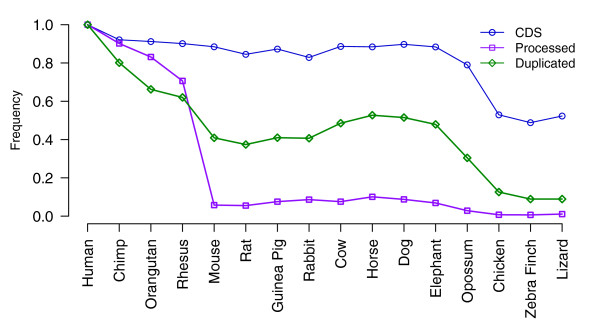
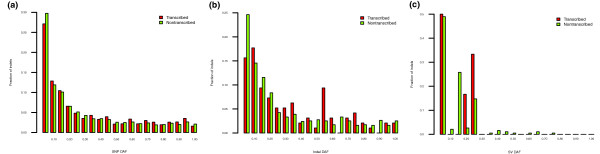
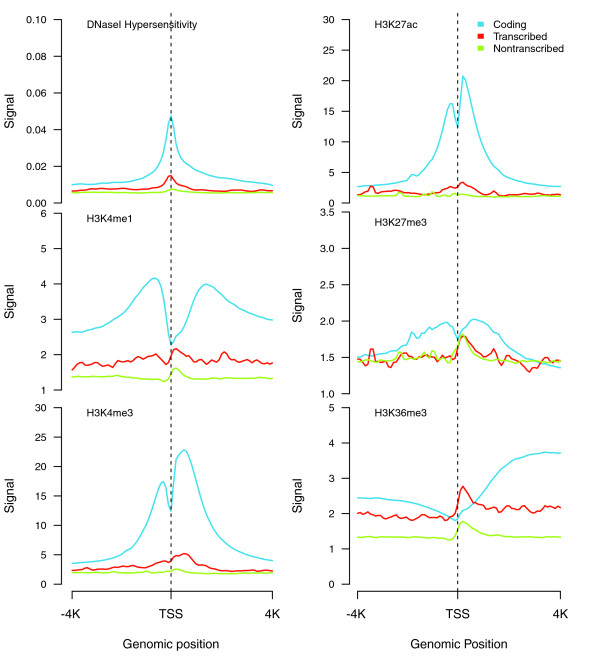
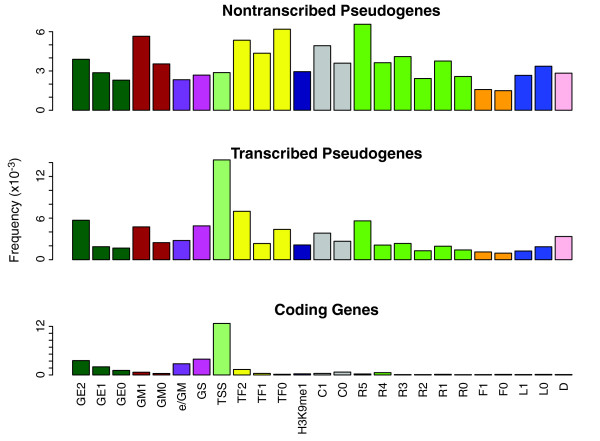
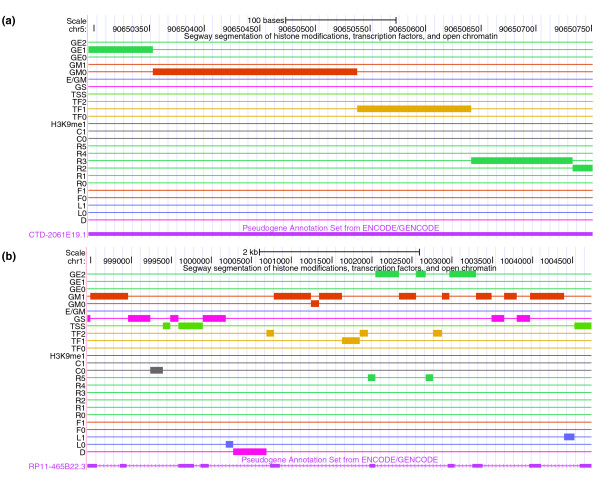
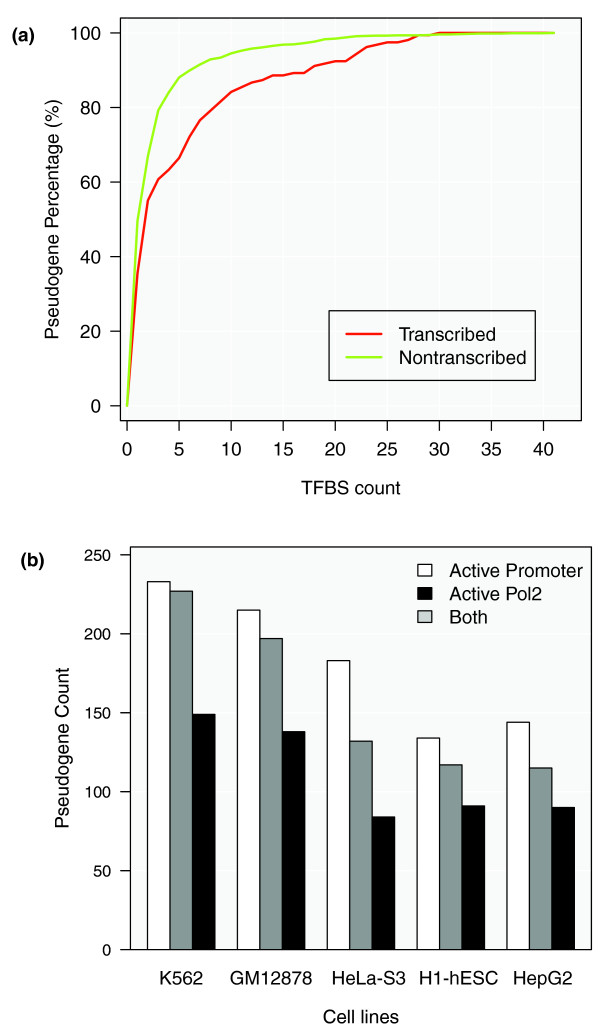
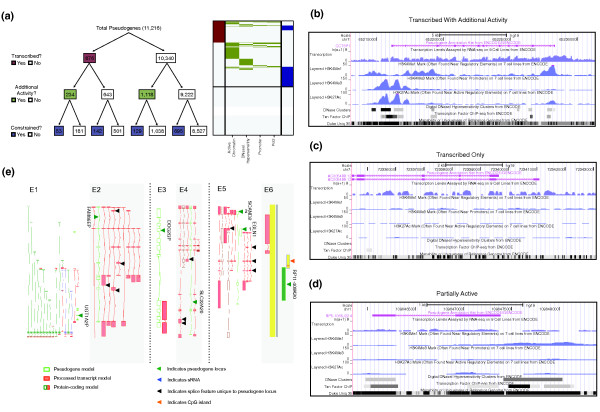
Results: As part of the GENCODE annotation of the human genome, we present the first genome-wide pseudogene assignment for protein-coding genes, based on both large-scale manual annotation and in silico pipelines. A key aspect of this coupled approach is that it allows us to identify pseudogenes in an unbiased fashion as well as untangle complex events through manual evaluation. We integrate the pseudogene annotations with the extensive ENCODE functional genomics information. In particular, we determine the expression level, transcription-factor and RNA polymerase II binding, and chromatin marks associated with each pseudogene. Based on their distribution, we develop simple statistical models for each type of activity, which we validate with large-scale RT-PCR-Seq experiments. Finally, we compare our pseudogenes with conservation and variation data from primate alignments and the 1000 Genomes project, producing lists of pseudogenes potentially under selection.
Conclusions: At one extreme, some pseudogenes possess conventional characteristics of functionality; these may represent genes that have recently died. On the other hand, we find interesting patterns of partial activity, which may suggest that dead genes are being resurrected as functioning non-coding RNAs. The activity data of each pseudogene are stored in an associated resource, psiDR, which will be useful for the initial identification of potentially functional pseudogenes.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
