

Long noncoding RNAs are rarely translated in two human cell lines
- PMID: 22955977
- PMCID: PMC3431482
- DOI: 10.1101/gr.134767.111
Long noncoding RNAs are rarely translated in two human cell lines
Abstract
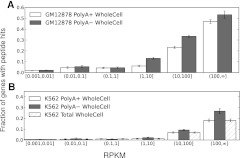
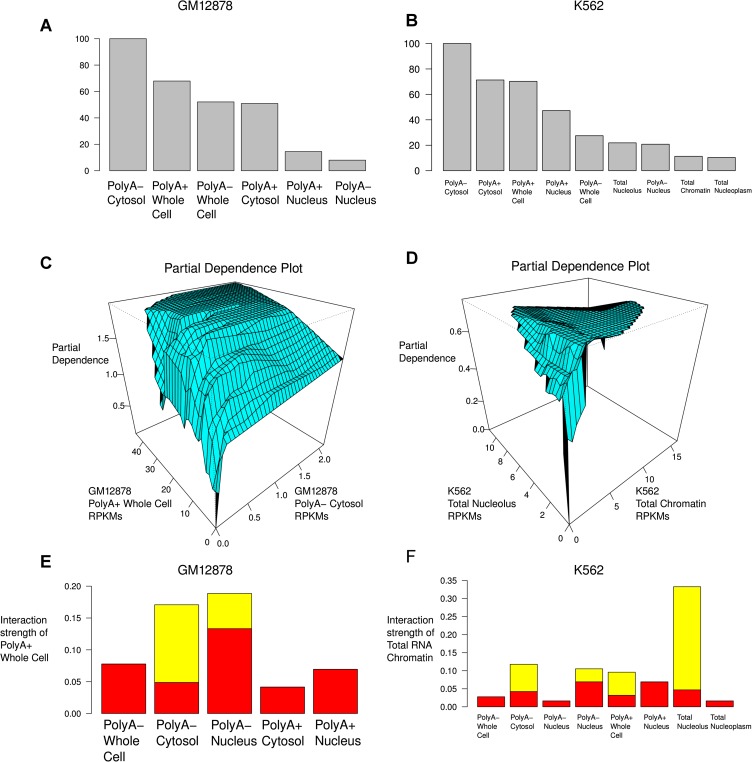
Data from the Encyclopedia of DNA Elements (ENCODE) project show over 9640 human genome loci classified as long noncoding RNAs (lncRNAs), yet only ~100 have been deeply characterized to determine their role in the cell. To measure the protein-coding output from these RNAs, we jointly analyzed two recent data sets produced in the ENCODE project: tandem mass spectrometry (MS/MS) data mapping expressed peptides to their encoding genomic loci, and RNA-seq data generated by ENCODE in long polyA+ and polyA- fractions in the cell lines K562 and GM12878. We used the machine-learning algorithm RuleFit3 to regress the peptide data against RNA expression data. The most important covariate for predicting translation was, surprisingly, the Cytosol polyA- fraction in both cell lines. LncRNAs are ~13-fold less likely to produce detectable peptides than similar mRNAs, indicating that ~92% of GENCODE v7 lncRNAs are not translated in these two ENCODE cell lines. Intersecting 9640 lncRNA loci with 79,333 peptides yielded 85 unique peptides matching 69 lncRNAs. Most cases were due to a coding transcript misannotated as lncRNA. Two exceptions were an unprocessed pseudogene and a bona fide lncRNA gene, both with open reading frames (ORFs) compromised by upstream stop codons. All potentially translatable lncRNA ORFs had only a single peptide match, indicating low protein abundance and/or false-positive peptide matches. We conclude that with very few exceptions, ribosomes are able to distinguish coding from noncoding transcripts and, hence, that ectopic translation and cryptic mRNAs are rare in the human lncRNAome.
Figures


References
-
- Breiman L 2001. Random Forests. Mach Learn 45: 5–32
-
- Carninci P, Kasukawa T, Katayama S, Gough J, Frith MC, Maeda N, Oyama R, Ravasi T, Lenhard B, Wells C, et al. 2005. The transcriptional landscape of the mammalian genome. Science 309: 1559–1563 - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources