

SANS: high-throughput retrieval of protein sequences allowing 50% mismatches
- PMID: 22962464
- PMCID: PMC3436844
- DOI: 10.1093/bioinformatics/bts417
SANS: high-throughput retrieval of protein sequences allowing 50% mismatches
Abstract
Motivation: The genomic era in molecular biology has brought on a rapidly widening gap between the amount of sequence data and first-hand experimental characterization of proteins. Fortunately, the theory of evolution provides a simple solution: functional and structural information can be transferred between homologous proteins. Sequence similarity searching followed by k-nearest neighbor classification is the most widely used tool to predict the function or structure of anonymous gene products that come out of genome sequencing projects.
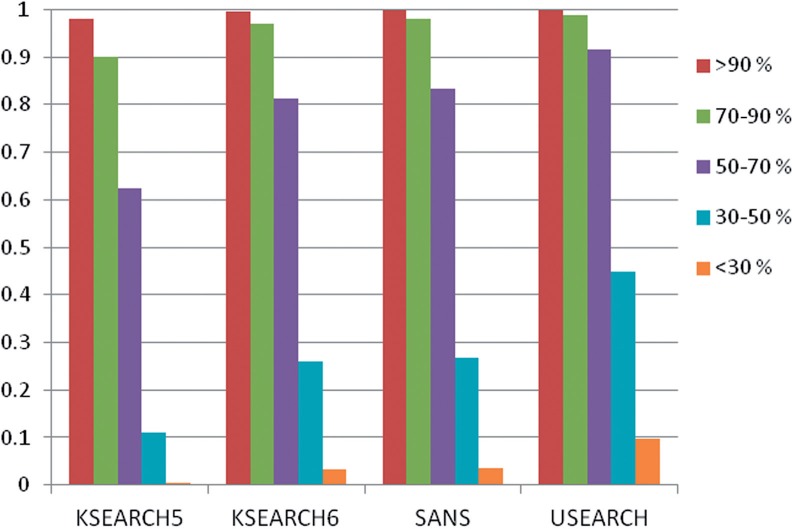
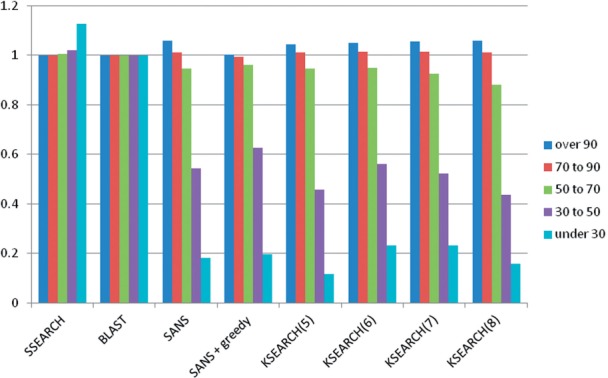
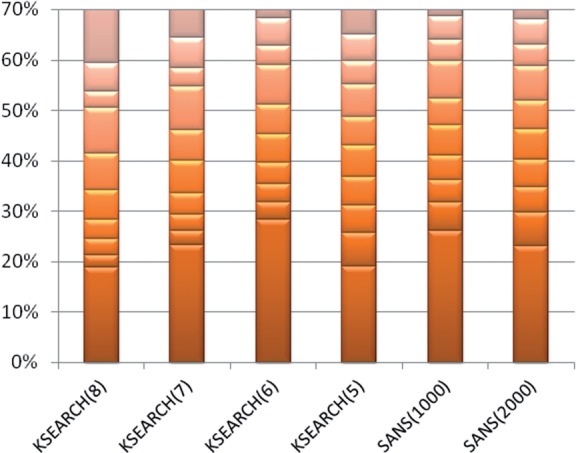
Results: We present a novel word filter, suffix array neighborhood search (SANS), to identify protein sequence similarities in the range of 50-100% identity with sensitivity comparable to BLAST and 10 times the speed of USEARCH. In contrast to these previous approaches, the complexity of the search is proportional only to the length of the query sequence and independent of database size, enabling fast searching and functional annotation into the future despite rapidly expanding databases.
Availability and implementation: The software is freely available to non-commercial users from our website http://ekhidna.biocenter.helsinki.fi/downloads/sans.
Contact: liisa.holm@helsinki.fi.
Figures
References
-
- Altschul S.F., et al. Basic local alignment search tool. J. Mol. Biol. 1990;215:403–410. - PubMed
-
- Bejerano G., Yona G. The Proceedings of RECOMB 1999. Lyon, France: ACM Press; 1999. Modeling protein families using probabilistic suffix trees; pp. 15–24.
-
- Burkhard S., et al. RECOMB'99 Proceedings of the third annual international conference on Computational molecular biology. Lyon, France: 1999. q-gram based database searching using a suffix array (QUASAR) pp. 77–83.
-
- Califano A., Rigoutsos I. FLASH: A fast look-up algorithm for string homology. In: Hunter L., et al., editors. Proceedings of the first International Conference on Intelligent Systems for Molecular Biology. Bethesda, Maryland, USA: 1993. pp. 56–64. - PubMed
-
- Devos D., Valencia A. Practical limits of function prediction. Proteins. 2000;41:98–07. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous
