

High reward makes items easier to remember, but harder to bind to a new temporal context
- PMID: 22969711
- PMCID: PMC3427914
- DOI: 10.3389/fnint.2012.00061
High reward makes items easier to remember, but harder to bind to a new temporal context
Abstract
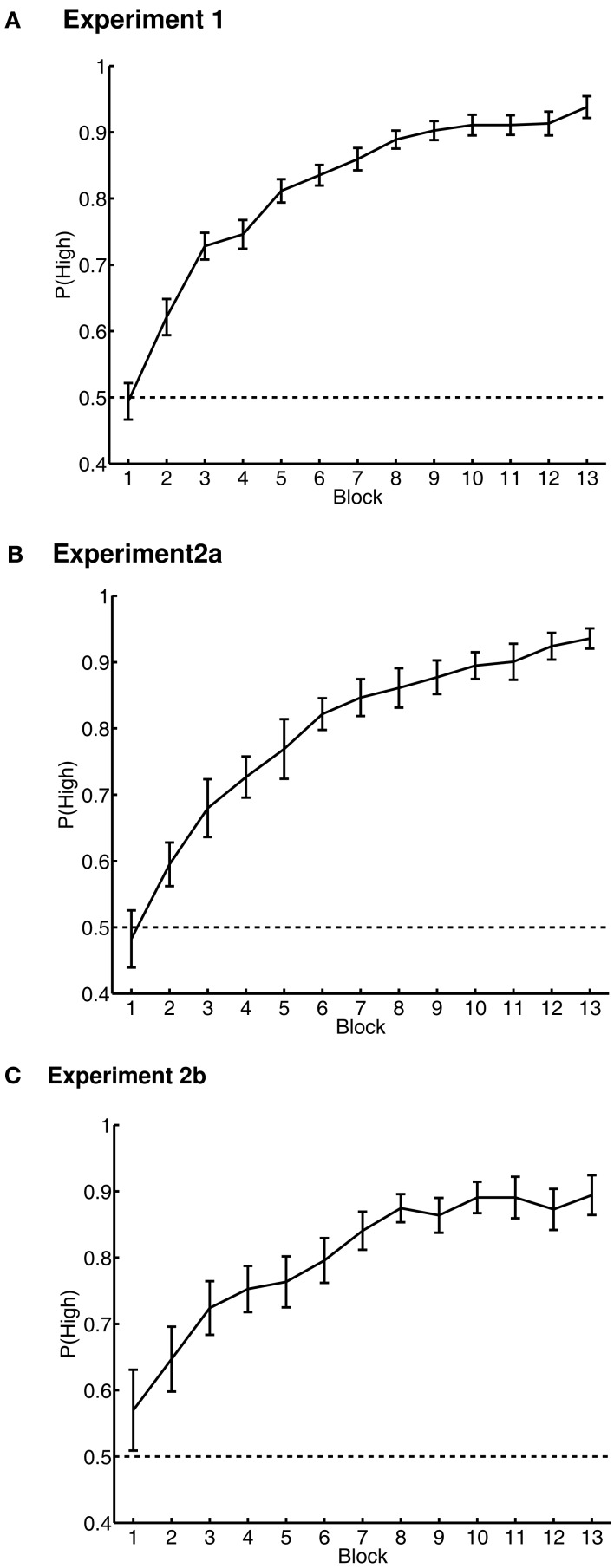
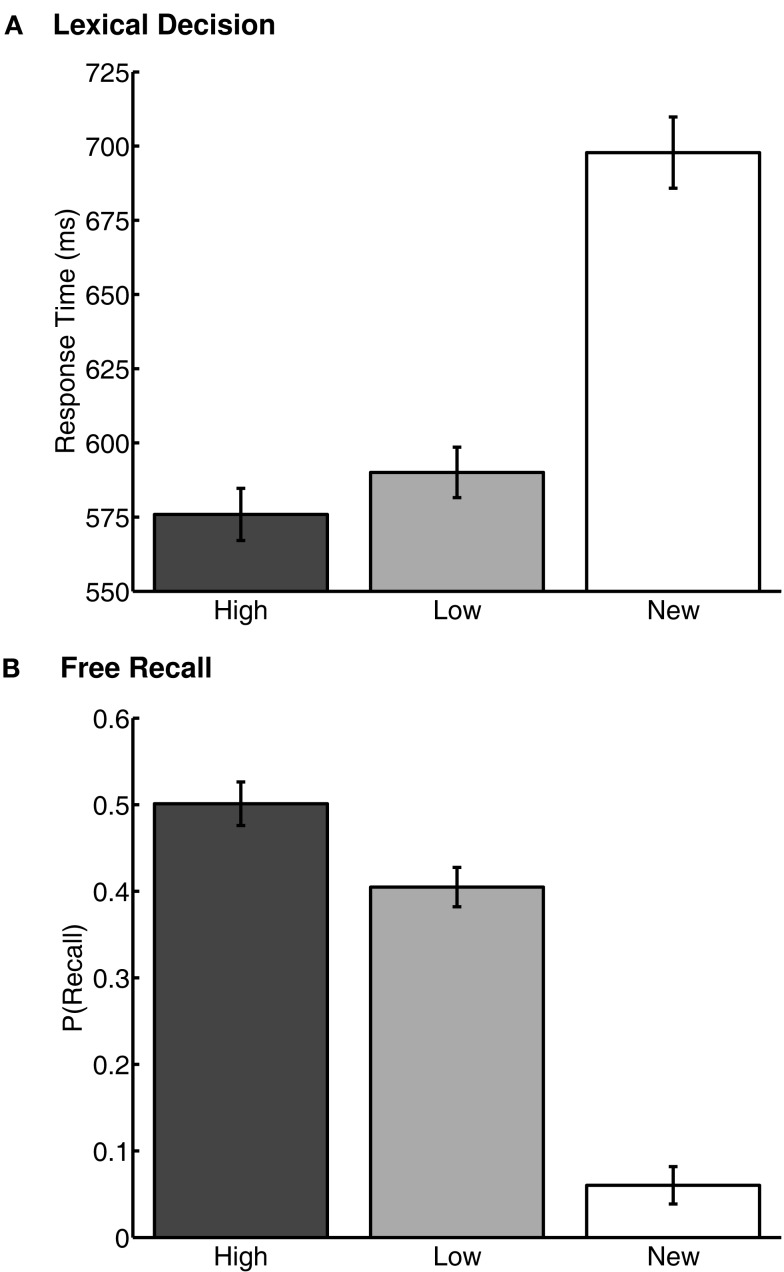
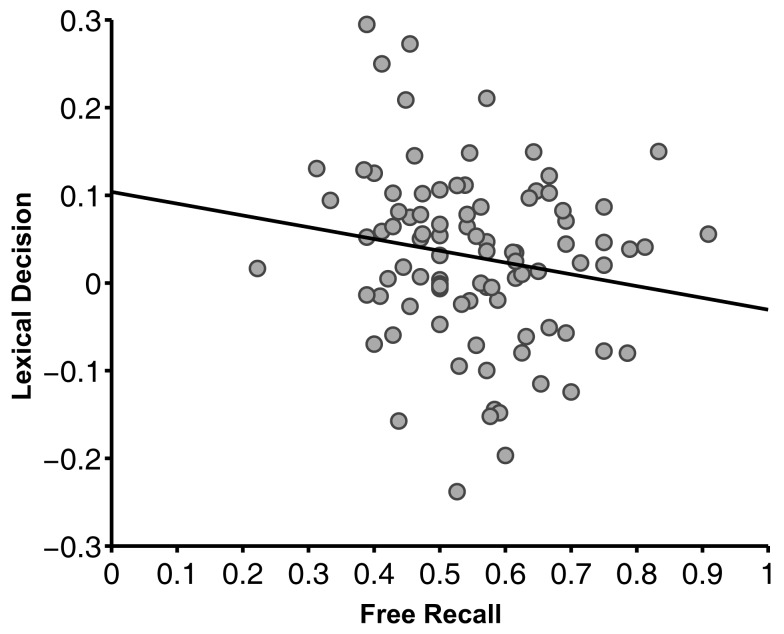
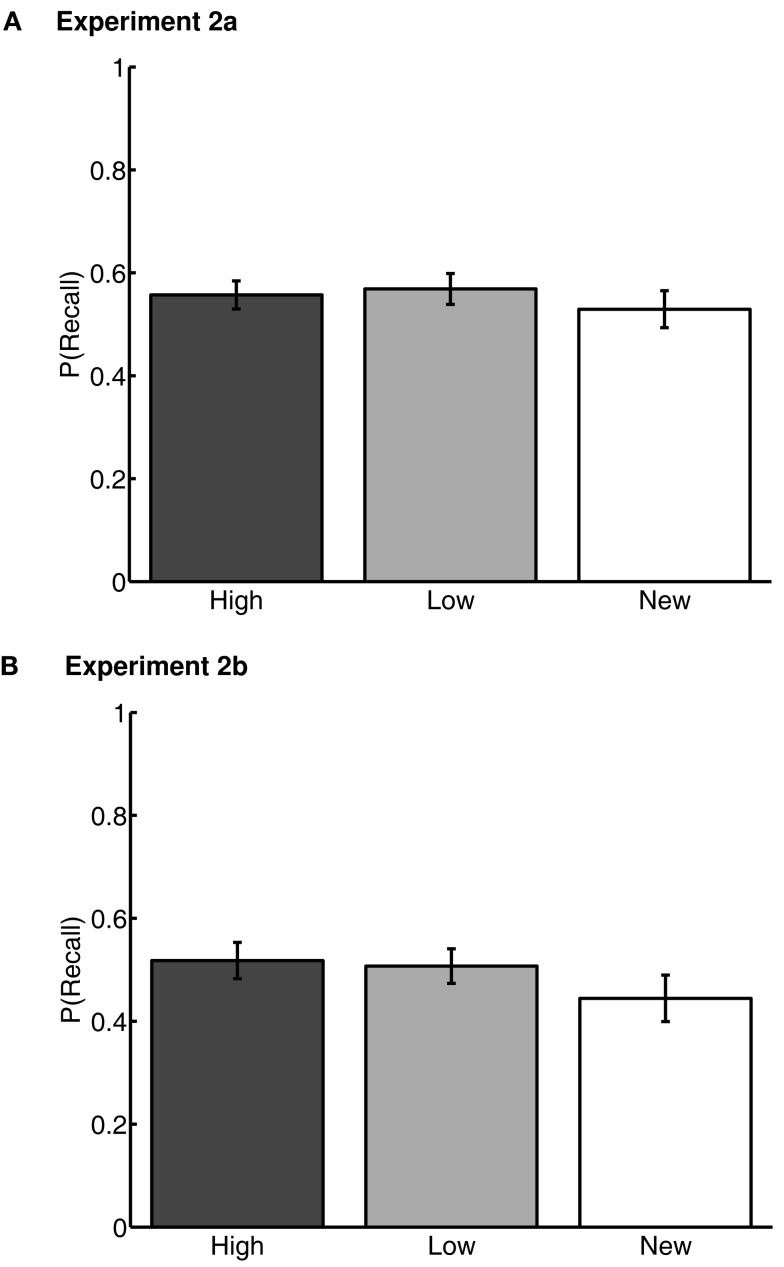
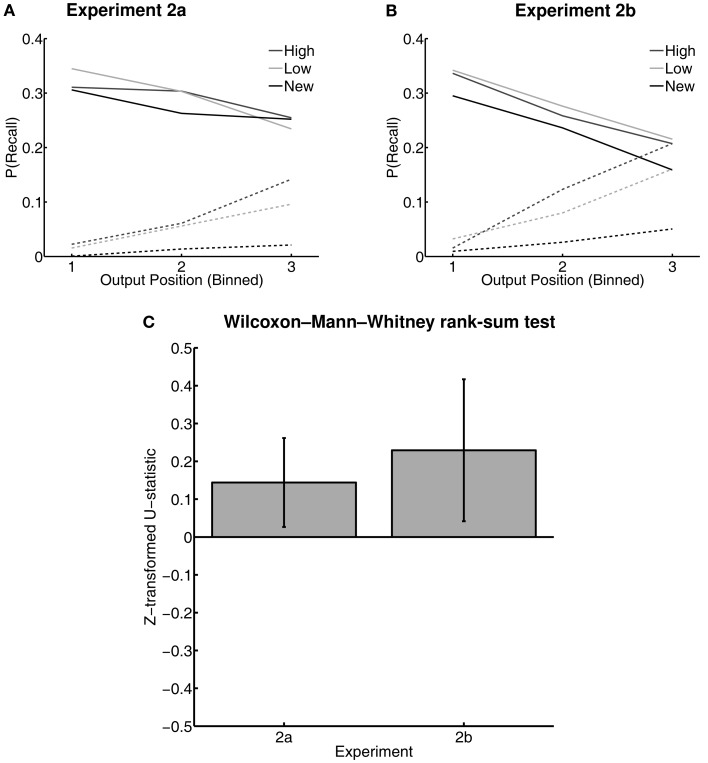
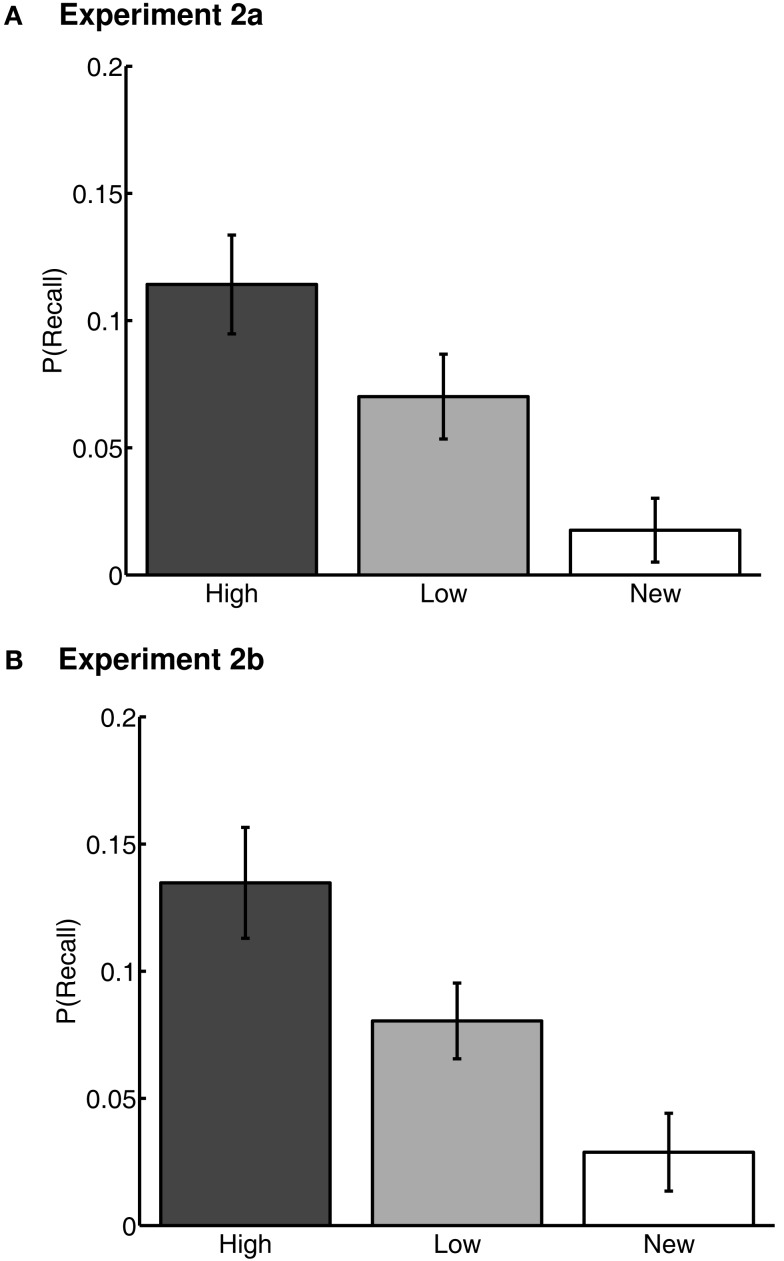
Learning through reward is central to adaptive behavior. Indeed, items are remembered better if they are experienced while participants expect a reward, and people can deliberately prioritize memory for high- over low-valued items. Do memory advantages for high-valued items only emerge after deliberate prioritization in encoding? Or, do reward-based memory enhancements also apply to unrewarded memory tests and to implicit memory? First, we tested for a high-value memory advantage in unrewarded implicit- and explicit-tests (Experiment 1). Participants first learned high or low-reward values of 36 words, followed by unrewarded lexical decision and free-recall tests. High-value words were judged faster in lexical decision, and more often recalled in free recall. These two memory advantages for high-value words were negatively correlated suggesting at least two mechanisms by which reward value can influence later item-memorability. The ease with which the values were originally acquired explained the negative correlation: people who learned values earlier showed reward effects in implicit memory whereas people who learned values later showed reward effects in explicit memory. We then asked whether a high-value advantage would persist if trained items were linked to a new context (Experiments 2a and 2b). Following the same value training as in Experiment 1, participants learned lists composed of previously trained words mixed with new words, each followed by free recall. Thus, participants had to retrieve words only from the most recent list, irrespective of their values. High- and low-value words were recalled equally, but low-value words were recalled earlier than high-value words and high-value words were more often intruded (proactive interference). Thus, the high-value advantage holds for implicit- and explicit-memory, but comes with a side effect: High-value items are more difficult to relearn in a new context. Similar to emotional arousal, reward value can both enhance and impair memory.
Keywords: context; explicit memory; free recall; implicit memory; lexical decision; reward; value.
Figures
Similar articles
-
Memory Recall for High Reward Value Items Correlates With Individual Differences in White Matter Pathways Associated With Reward Processing and Fronto-Temporal Communication.Front Hum Neurosci. 2018 Jun 15;12:241. doi: 10.3389/fnhum.2018.00241. eCollection 2018. Front Hum Neurosci. 2018. PMID: 29973873 Free PMC article.
-
State-dependent effects of alcohol on recollective experience, familiarity and awareness of memories.Psychopharmacology (Berl). 2001 Jan;153(3):295-306. doi: 10.1007/s002130000564. Psychopharmacology (Berl). 2001. PMID: 11271401
-
Is the enhancement of memory due to reward driven by value or salience?Acta Psychol (Amst). 2012 Feb;139(2):343-9. doi: 10.1016/j.actpsy.2011.12.010. Epub 2012 Jan 20. Acta Psychol (Amst). 2012. PMID: 22266252
-
[Memory bias and depression: a critical commentary].Encephale. 2007 May-Jun;33(3 Pt 1):242-8. doi: 10.1016/s0013-7006(07)92035-7. Encephale. 2007. PMID: 17675919 Review. French.
-
Reward prediction errors create event boundaries in memory.Cognition. 2020 Oct;203:104269. doi: 10.1016/j.cognition.2020.104269. Epub 2020 Jun 17. Cognition. 2020. PMID: 32563083 Free PMC article. Review.
Cited by
-
Not all that glittered is gold: neural mechanisms that determine when reward will enhance or impair memory.Front Neurosci. 2014 Jul 16;8:194. doi: 10.3389/fnins.2014.00194. eCollection 2014. Front Neurosci. 2014. PMID: 25076871 Free PMC article. No abstract available.
-
Reward-motivated memories influence new learning across development.Learn Mem. 2022 Oct 17;29(11):421-429. doi: 10.1101/lm.053595.122. Print 2022 Nov. Learn Mem. 2022. PMID: 36253009 Free PMC article.
-
Hippocampal contributions to value-based learning: Converging evidence from fMRI and amnesia.Cogn Affect Behav Neurosci. 2019 Jun;19(3):523-536. doi: 10.3758/s13415-018-00687-8. Cogn Affect Behav Neurosci. 2019. PMID: 30767129 Free PMC article.
-
Individual differences in experienced and observational decision-making illuminate interactions between reinforcement learning and declarative memory.Sci Rep. 2021 Mar 15;11(1):5899. doi: 10.1038/s41598-021-85322-2. Sci Rep. 2021. PMID: 33723288 Free PMC article.
-
Positive affect modulates memory by regulating the influence of reward prediction errors.Commun Psychol. 2024 Jun 5;2(1):52. doi: 10.1038/s44271-024-00106-4. Commun Psychol. 2024. PMID: 39242805 Free PMC article.
References
-
- Allen G. A., Estes K. (1972). Acquisition of correct choices and value judgements in binary choice learning with differential rewards. Psychon. Sci. 27, 68–72
LinkOut - more resources
Full Text Sources