

High-resolution mapping of linear antibody epitopes using ultrahigh-density peptide microarrays
- PMID: 22984286
- PMCID: PMC3518105
- DOI: 10.1074/mcp.M112.020800
High-resolution mapping of linear antibody epitopes using ultrahigh-density peptide microarrays
Abstract
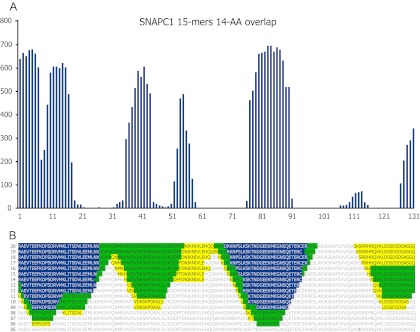
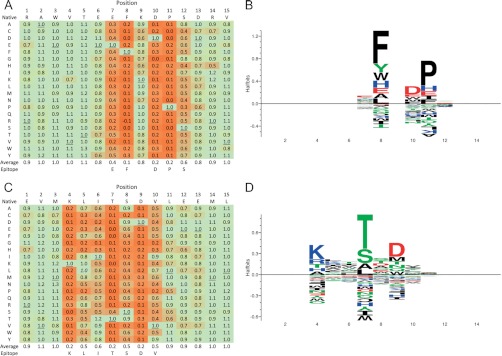
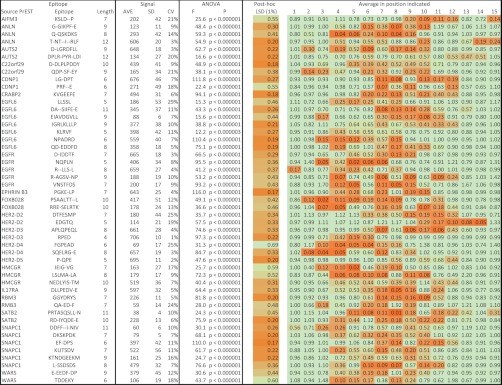
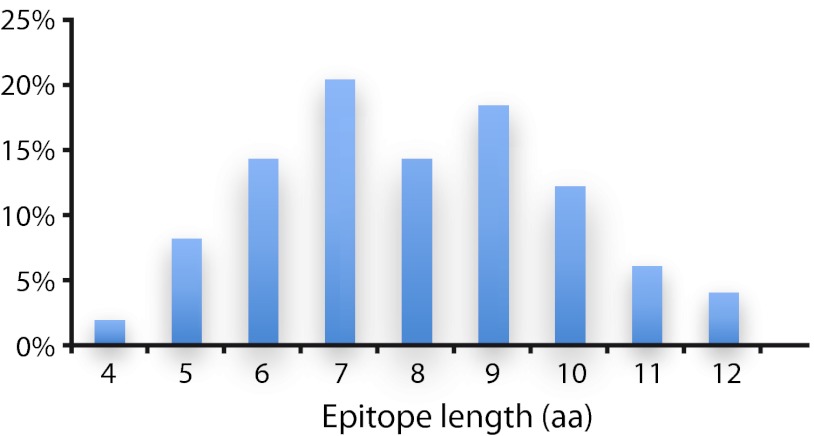
Antibodies empower numerous important scientific, clinical, diagnostic, and industrial applications. Ideally, the epitope(s) targeted by an antibody should be identified and characterized, thereby establishing antibody reactivity, highlighting possible cross-reactivities, and perhaps even warning against unwanted (e.g. autoimmune) reactivities. Antibodies target proteins as either conformational or linear epitopes. The latter are typically probed with peptides, but the cost of peptide screening programs tends to prohibit comprehensive specificity analysis. To perform high-throughput, high-resolution mapping of linear antibody epitopes, we have used ultrahigh-density peptide microarrays generating several hundred thousand different peptides per array. Using exhaustive length and substitution analysis, we have successfully examined the specificity of a panel of polyclonal antibodies raised against linear epitopes of the human proteome and obtained very detailed descriptions of the involved specificities. The epitopes identified ranged from 4 to 12 amino acids in size. In general, the antibodies were of exquisite specificity, frequently disallowing even single conservative substitutions. In several cases, multiple distinct epitopes could be identified for the same target protein, suggesting an efficient approach to the generation of paired antibodies. Two alternative epitope mapping approaches identified similar, although not necessarily identical, epitopes. These results show that ultrahigh-density peptide microarrays can be used for linear epitope mapping. With an upper theoretical limit of 2,000,000 individual peptides per array, these peptide microarrays may even be used for a systematic validation of antibodies at the proteomic level.
Figures


References
-
- Gloriam D. E., Orchard S., Bertinetti D., Bjorling E., Bongcam-Rudloff E., Borrebaeck C. A., Bourbeillon J., Bradbury A. R., de Daruvar A., Dubel S., Frank R., Gibson T. J., Gold L., Haslam N., Herberg F. W., Hiltke T., Hoheisel J. D., Kerrien S., Koegl M., Konthur Z., Korn B., Landegren U., Montecchi-Palazzi L., Palcy S., Rodriguez H., Schweinsberg S., Sievert V., Stoevesandt O., Taussig M. J., Ueffing M., Uhlen M., van der Maarel S., Wingren C., Woollard P., Sherman D. J., Hermjakob H. (2010) A community standard format for the representation of protein affinity reagents. Mol. Cell. Proteomics 9, 1–10 - PMC - PubMed
-
- Dubel S., Stoevesandt O., Taussig M. J., Hust M. (2010) Generating recombinant antibodies to the complete human proteome. Trends Biotechnol. 28, 333–339 - PubMed
-
- Uhlen M., Oksvold P., Fagerberg L., Lundberg E., Jonasson K., Forsberg M., Zwahlen M., Kampf C., Wester K., Hober S., Wernerus H., Bjorling L., Ponten F. (2010) Towards a knowledge-based Human Protein Atlas. Nat. Biotechnol. 28, 1248–1250 - PubMed
-
- Taussig M. J., Stoevesandt O., Borrebaeck C. A., Bradbury A. R., Cahill D., Cambillau C., de Daruvar A., Dubel S., Eichler J., Frank R., Gibson T. J., Gloriam D., Gold L., Herberg F. W., Hermjakob H., Hoheisel J. D., Joos T. O., Kallioniemi O., Koegl M., Konthur Z., Korn B., Kremmer E., Krobitsch S., Landegren U., van der Maarel S., McCafferty J., Muyldermans S., Nygren P. A., Palcy S., Pluckthun A., Polic B., Przybylski M., Saviranta P., Sawyer A., Sherman D. J., Skerra A., Templin M., Ueffing M., Uhlen M. (2007) ProteomeBinders: planning a European resource of affinity reagents for analysis of the human proteome. Nat. Methods 4, 13–17 - PubMed
-
- Uhlen M., Graslund S., Sundstrom M. (2008) A pilot project to generate affinity reagents to human proteins. Nat. Methods 5, 854–855 - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
