

Looking just below the eyes is optimal across face recognition tasks
- PMID: 23150543
- PMCID: PMC3511732
- DOI: 10.1073/pnas.1214269109
Looking just below the eyes is optimal across face recognition tasks
Abstract
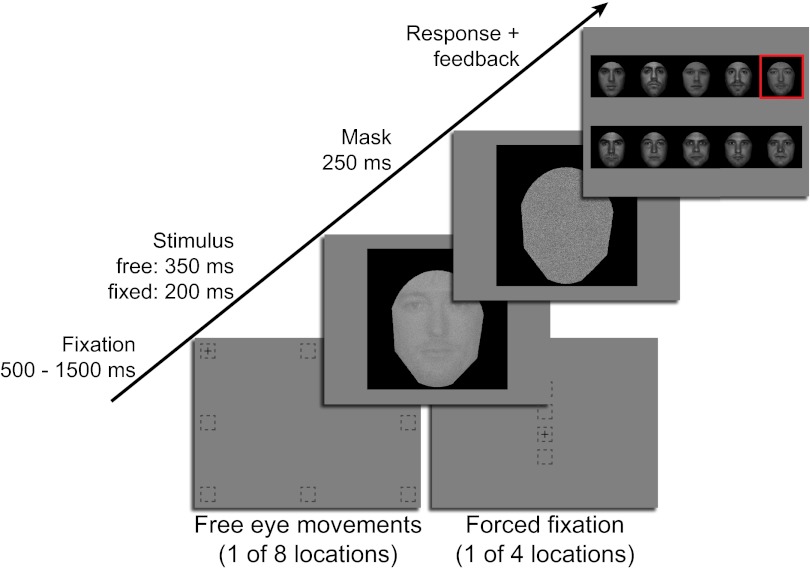
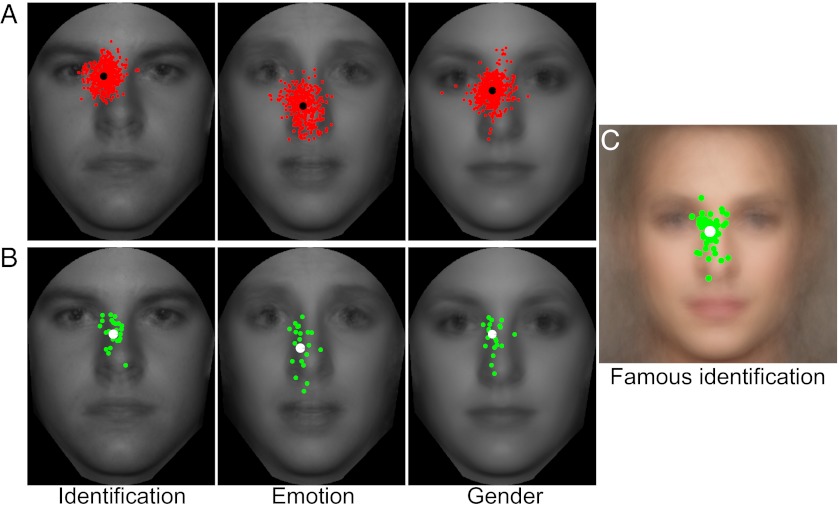
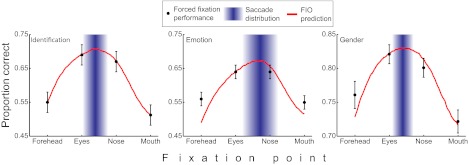
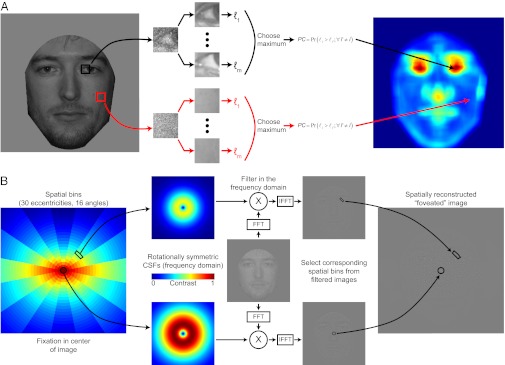
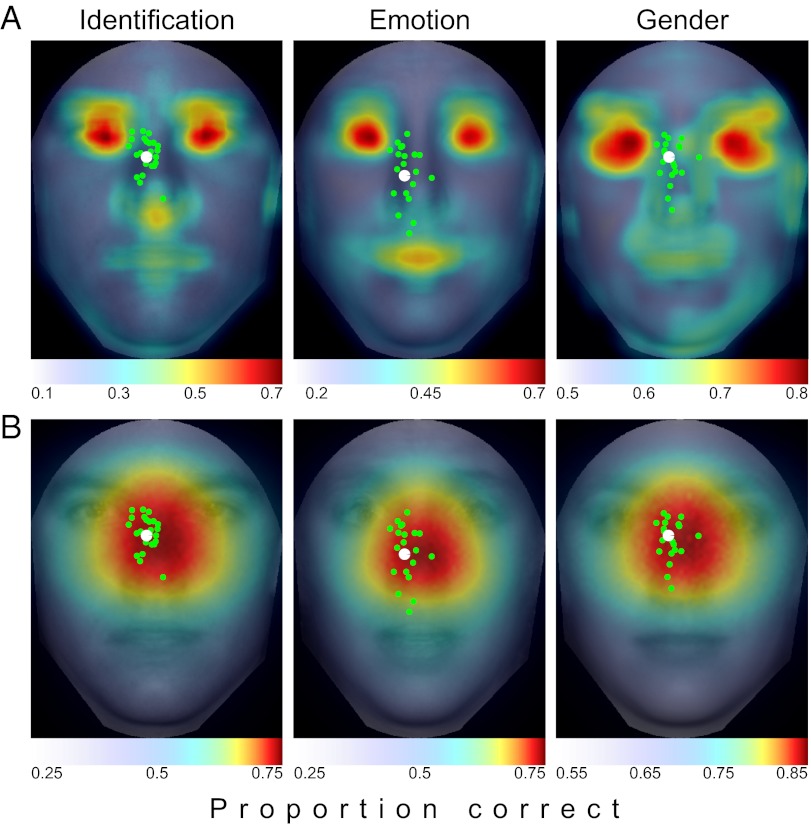
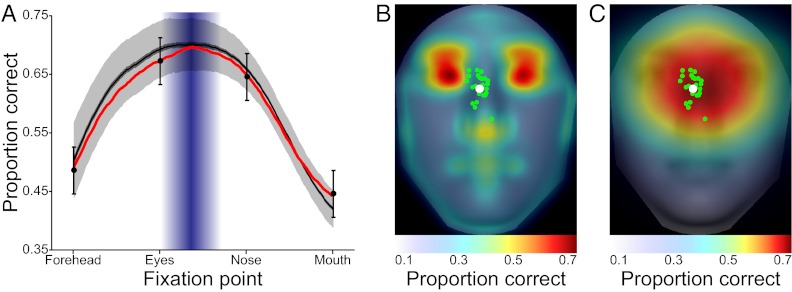
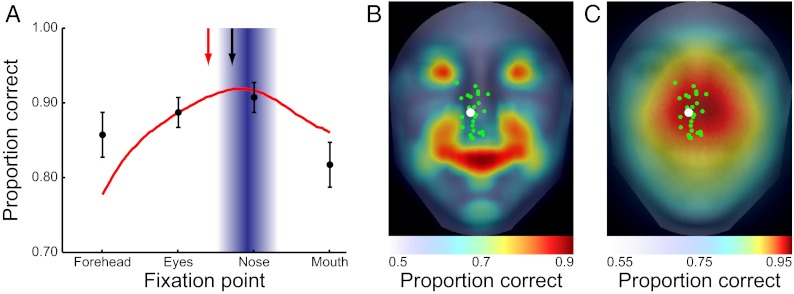
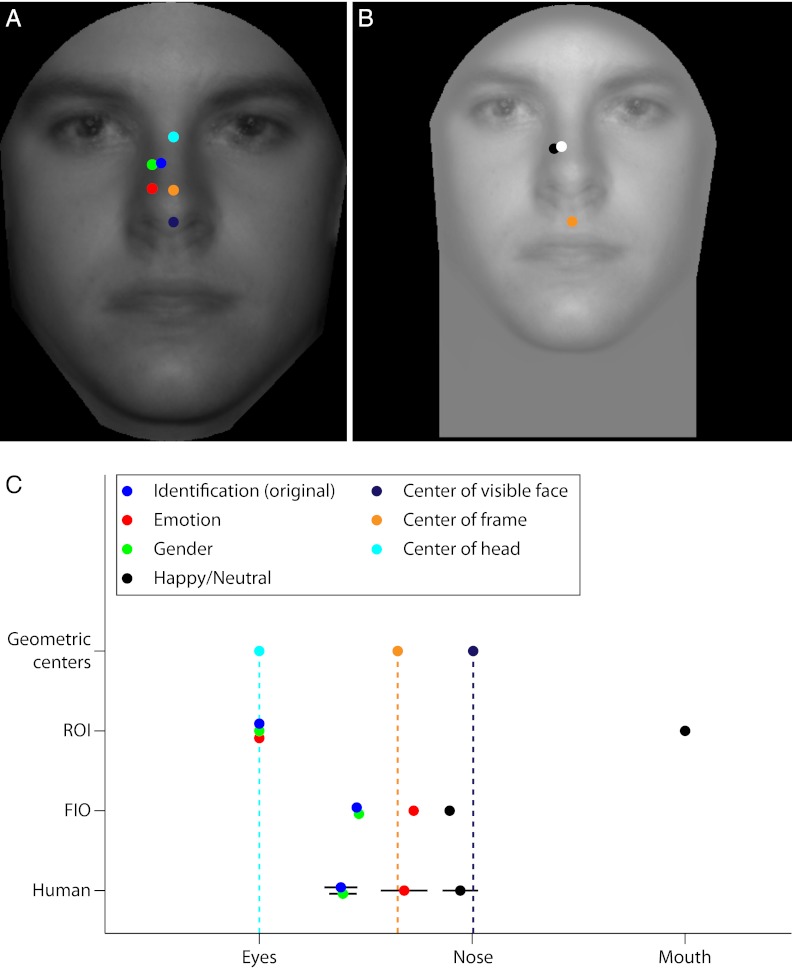
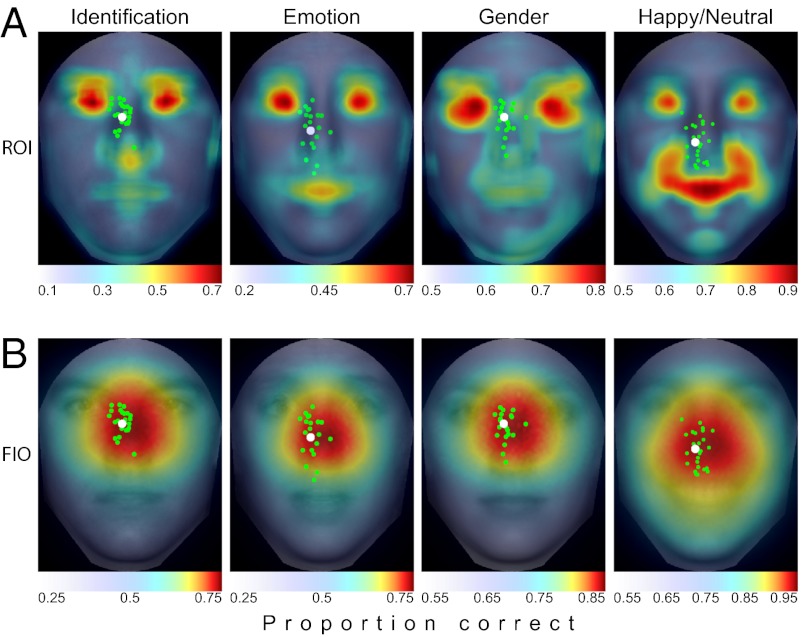
When viewing a human face, people often look toward the eyes. Maintaining good eye contact carries significant social value and allows for the extraction of information about gaze direction. When identifying faces, humans also look toward the eyes, but it is unclear whether this behavior is solely a byproduct of the socially important eye movement behavior or whether it has functional importance in basic perceptual tasks. Here, we propose that gaze behavior while determining a person's identity, emotional state, or gender can be explained as an adaptive brain strategy to learn eye movement plans that optimize performance in these evolutionarily important perceptual tasks. We show that humans move their eyes to locations that maximize perceptual performance determining the identity, gender, and emotional state of a face. These optimal fixation points, which differ moderately across tasks, are predicted correctly by a Bayesian ideal observer that integrates information optimally across the face but is constrained by the decrease in resolution and sensitivity from the fovea toward the visual periphery (foveated ideal observer). Neither a model that disregards the foveated nature of the visual system and makes fixations on the local region with maximal information, nor a model that makes center-of-gravity fixations correctly predict human eye movements. Extension of the foveated ideal observer framework to a large database of real-world faces shows that the optimality of these strategies generalizes across the population. These results suggest that the human visual system optimizes face recognition performance through guidance of eye movements not only toward but, more precisely, just below the eyes.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
Similar articles
-
Domain Specificity of Oculomotor Learning after Changes in Sensory Processing.J Neurosci. 2017 Nov 22;37(47):11469-11484. doi: 10.1523/JNEUROSCI.1208-17.2017. Epub 2017 Oct 20. J Neurosci. 2017. PMID: 29054879 Free PMC article.
-
Eye movement strategies in face ethnicity categorization vs. face identification tasks.Vision Res. 2021 Sep;186:59-70. doi: 10.1016/j.visres.2021.05.007. Epub 2021 May 27. Vision Res. 2021. PMID: 34052698
-
Initial eye movements during face identification are optimal and similar across cultures.J Vis. 2015;15(13):12. doi: 10.1167/15.13.12. J Vis. 2015. PMID: 26382003 Free PMC article.
-
Individual differences in eye movements during face identification reflect observer-specific optimal points of fixation.Psychol Sci. 2013 Jul 1;24(7):1216-25. doi: 10.1177/0956797612471684. Epub 2013 Jun 5. Psychol Sci. 2013. PMID: 23740552 Free PMC article.
-
Complementary effects of gaze direction and early saliency in guiding fixations during free viewing.J Vis. 2014 Nov 4;14(13):3. doi: 10.1167/14.13.3. J Vis. 2014. PMID: 25371549
Cited by
-
Visual Fixation Patterns During Viewing of Half-Face Stimuli in Adults: An Eye-Tracking Study.Front Psychol. 2018 Dec 11;9:2478. doi: 10.3389/fpsyg.2018.02478. eCollection 2018. Front Psychol. 2018. PMID: 30618923 Free PMC article.
-
Great Minds Think Alike? Spatial Search Processes Can Be More Idiosyncratic When Guided by More Accurate Information.Cogn Sci. 2022 Apr;46(4):e13132. doi: 10.1111/cogs.13132. Cogn Sci. 2022. PMID: 35411964 Free PMC article.
-
Patterns of fixation during face recognition: Differences in autism across age.Autism. 2018 Oct;22(7):866-880. doi: 10.1177/1362361317714989. Epub 2017 Aug 6. Autism. 2018. PMID: 28782371 Free PMC article.
-
Context Modulates Attention to Faces in Dynamic Social Scenes in Children and Adults with Autism Spectrum Disorder.J Autism Dev Disord. 2022 Oct;52(10):4219-4232. doi: 10.1007/s10803-021-05279-z. Epub 2021 Oct 8. J Autism Dev Disord. 2022. PMID: 34623583 Free PMC article.
-
The effect of face masks and sunglasses on identity and expression recognition with super-recognizers and typical observers.R Soc Open Sci. 2021 Mar 24;8(3):201169. doi: 10.1098/rsos.201169. R Soc Open Sci. 2021. PMID: 33959312 Free PMC article.
References
-
- Zhao W, Chellappa R, Phillips PJ, Rosenfeld A. Face recognition: A literature survey. Association for Computing Machinery: Computer Surveys. 2003;35(4):399–458.
-
- Diamond R, Carey S. Why faces are and are not special: An effect of expertise. J Exp Psychol Gen. 1986;115(2):107–117. - PubMed
-
- Haxby JV, Hoffman EA, Gobbini MI. The distributed human neural system for face perception. Trends Cogn Sci. 2000;4(6):223–233. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
