

doi: 10.1007/978-1-4614-5037-5_2.
Structure and Mechanisms of SF1 DNA Helicases
Affiliations
- PMID: 23161005
- PMCID: PMC3806203
- DOI: 10.1007/978-1-4614-5037-5_2
Item in Clipboard
Structure and Mechanisms of SF1 DNA Helicases
Adv Exp Med Biol.
2013.
Abstract
Superfamily I is a large and diverse group of monomeric and dimeric helicases defined by a set of conserved sequence motifs. Members of this class are involved in essential processes in both DNA and RNA metabolism in all organisms. In addition to conserved amino acid sequences, they also share a common structure containing two RecA-like motifs involved in ATP binding and hydrolysis and nucleic acid binding and unwinding. Unwinding is facilitated by a "pin" structure which serves to split the incoming duplex. This activity has been measured using both ensemble and single-molecule conditions. SF1 helicase activity is modulated through interactions with other proteins.
Figures
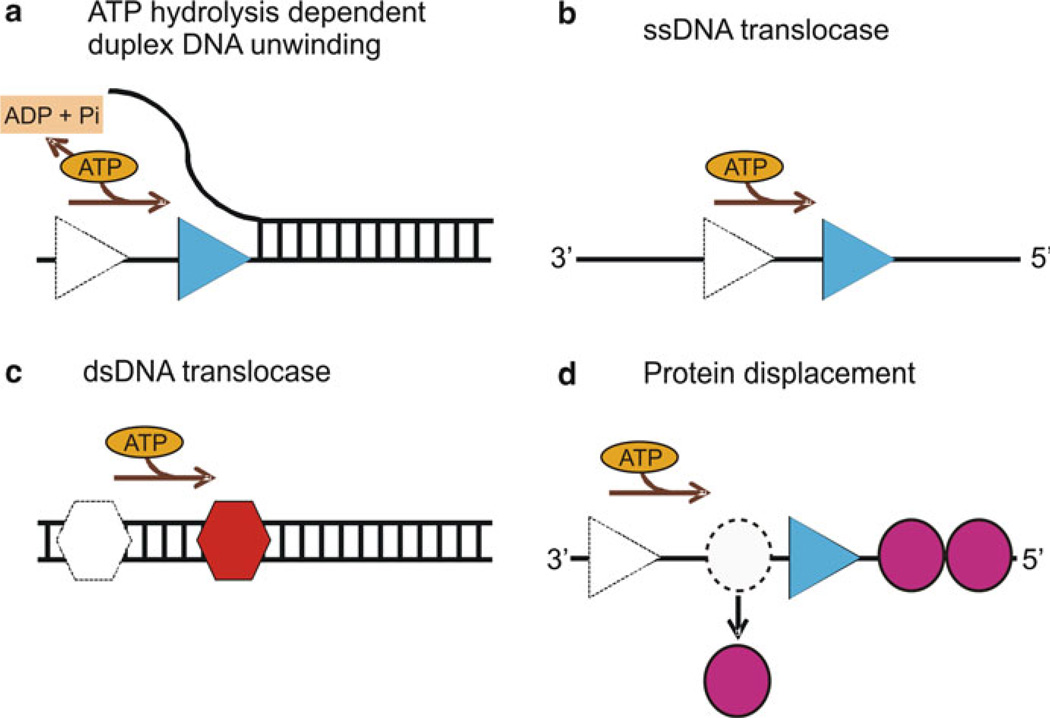
Biochemical properties of helicases: (a) ATP hydrolysis-dependent unwinding of duplex DNA by helicase (blue triangle). The movement of helicase along the DNA utilizing the energy from ATP hydrolysis separates the duplex nucleic acid into single strands. (b) An ssDNA translocase (blue triangle) moves with biased directionality along the DNA powered by ATP binding and hydrolysis. The directionality of translocation can be 3′–5′ or 5′–3′. (c) A dsDNA translocase (red hexagon) moves along dsDNA. (d) Helicases can displace proteins (magenta circles) bound to the DNA strand as a result of their biased directional movement (adapted from ref. [45])
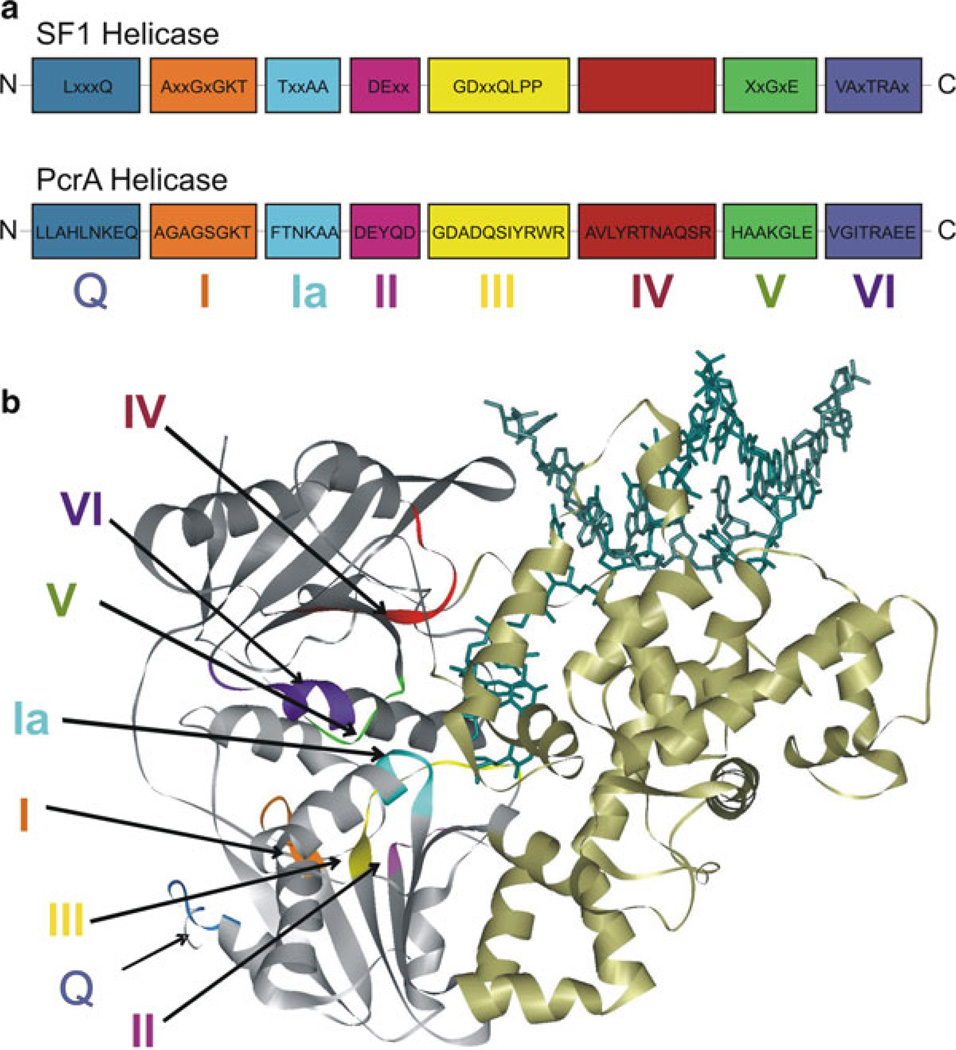
Schematic representation of the motifs of SF1 helicases: (a) The consensus sequences for the conserved helicase motifs of SF1 helicases and PcrA are shown. The N-terminus of the protein is on the left and C-terminus is on the right side. Labels below the boxes are the names assigned to the motifs (motifs Q, I, Ia, II–VI). The relative positions of motifs and spacing between motifs are arbitrary. The consensus amino acid sequences of PcrA are taken from refs. [46, 89]. (b) The crystal structure of PcrA helicase (Protein Data Bank code 3PJR) [87, 89] bound to DNA (dark green) illustrating the different conserved motifs. The helicase motifs are in the cleft formed between the two RecA-like domains (grey). The colors of different motifs in the structure are as follows: motif Q, blue; motif I, orange; motif Ia, cyan; motif II, magenta; motif III, yellow; motif IV, red; motif V, green; motif VI, purple
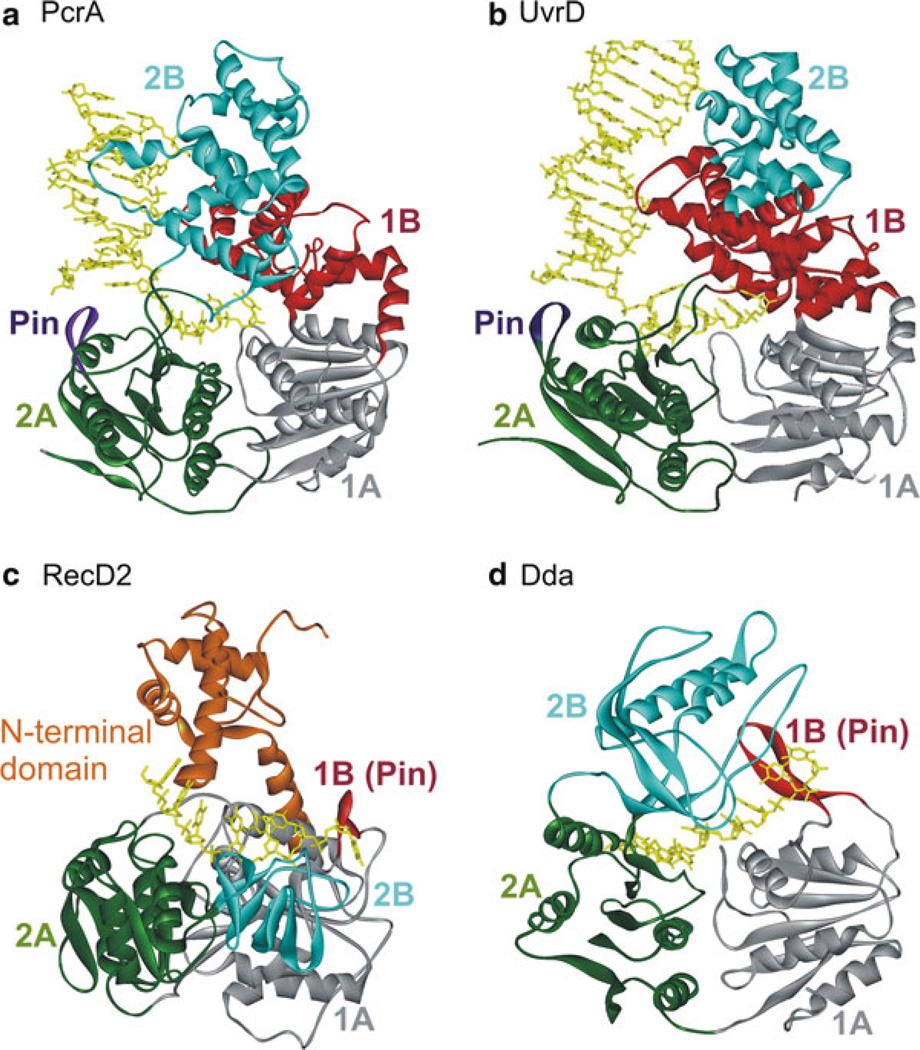
Crystal structures of SF1A (PcrA, UvrD) and SF1B (RecD2, Dda) helicases: (a) Ribbon diagram of PcrA helicase from Bacillus stearothermophilus (Protein Data Bank code 3PJR) [87, 89]. The RecA-like domains 1A and 2A are shown in grey and green colors, respectively. The structure shows the red 1B domain and the pin (purple) separating the strands of duplex DNA. The 2B domain is shown in cyan. (b) Structure of Escherichia coli UvrD helicase (PDB code 2IS1 [122]). Domains are colored as in (a). (c) Structure of RecD2 helicase from Deinococcus radiodurans (PDB code 3GPL [93]). Domains 1A, 2A, and 2B are colored as in (a). The beta-hairpin (1B) is red. The N-terminal domain is colored orange. (d) Structure of bacteriophage T4 Dda helicase bound to ssDNA (PDB id: 3UPU) (He et al., in press). The domains are colored as in (c). Nucleic acid is colored yellow in all structures
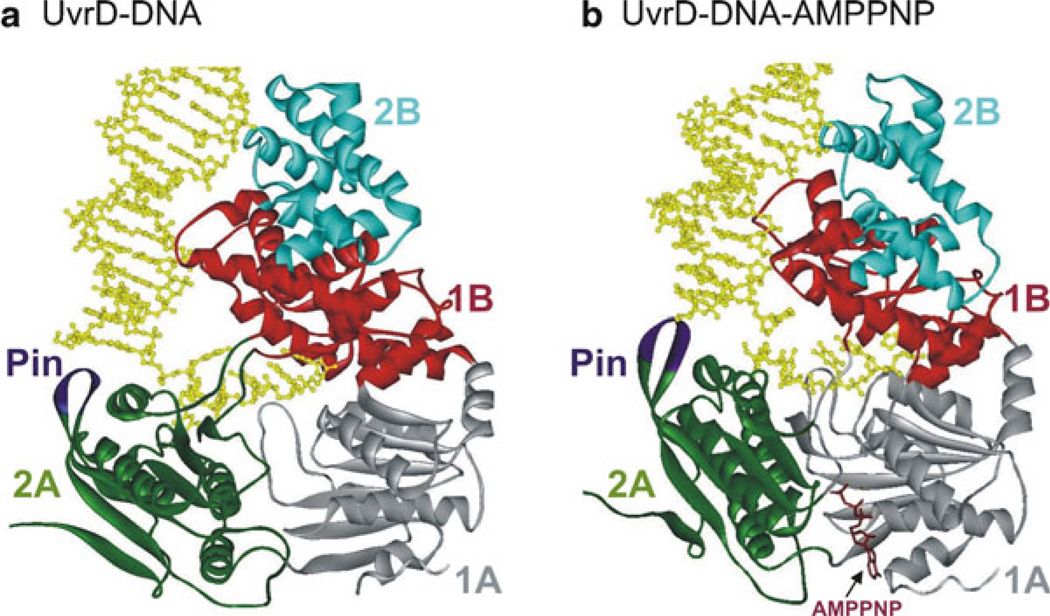
Crystal structures of (a) UvrD–DNA and (b) UvrD–DNA–AMPPNP complexes [122]. The four domains (1A, 1B, 2A, and 2B) are colored grey, red, green, and cyan, respectively. The Pin region is shown in purple. The 3′-ssDNA tail is bound across domains 1A and 2A. Domains 1B and 2B interact with the DNA duplex. Binding of AMPPNP (brown) induces domains 2A and 1A to rotate towards each other by 20°
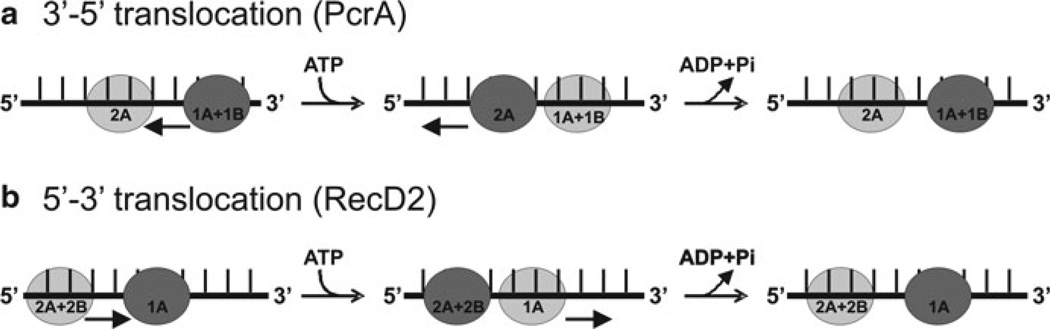
Comparison of the translocation mechanism of SF1A (PcrA) and SF1B (RecD2) helicases: In both enzyme classes, a cycle of ATP binding and hydrolysis induces conformational changes that result in translocation of the protein along DNA, but in opposite directions. Dark grey circles represent domains that have a tight grip on the ssDNA, and light grey circles represent domains that have a weaker grip and can slide along the DNA. Conversion between tight and weak grip (dark and light grey circles) is indicated by arrows. (a) The translocation mechanism of PcrA is shown in cartoon form demonstrating the change in affinity for ssDNA of domains 1A and 2A during translocation. Prior to ATP binding, ssDNA is bound to the enzyme spanning the 1A and 2A domains. Binding of ATP induces closure of the cleft between 1A and 2A domains. At this point, the grip is tightest on the 2A domain, causing the DNA to slide across the 1A/1B domains. Upon ATP hydrolysis, bind to ssDNA in 1A becomes tighter, whereas binding of ssDNA in 2A becomes weaker, releasing ssDNA. The domains also move apart, due to domain 2A sliding forward, causing the ssDNA to be pulled along the DNA-binding channel relative to the domain 2A. The result is translocation along the DNA in a 3′–5′ direction (indicated by black arrows). (b) Translocation mechanism of RecD2 helicase. When ATP binds to the enzyme, the cleft closes between 1A and 2A motor domains, causing domains 2A and 2B to slide along the DNA backbone (black arrows). The contacts between domain 1A and the DNA remain tight to anchor the DNA as domains 2A and 2B slide along it. When the conformational change is complete, the grip of domain 1A on the DNA is loosened. Then, ATP hydrolysis takes place, allowing the cleft to relax to the open conformation. The DNA is pulled back by domains 2A and 2B, which now have a tighter grip on bound DNA than domain 1A. This causes the DNA to slide across the surface of domain 1A as it moves away from domains 2A and 2B. The result is translocation by one base in a 5′–3′ direction (black arrows) during a single round of ATP binding and hydrolysis (adapted from ref. [94])
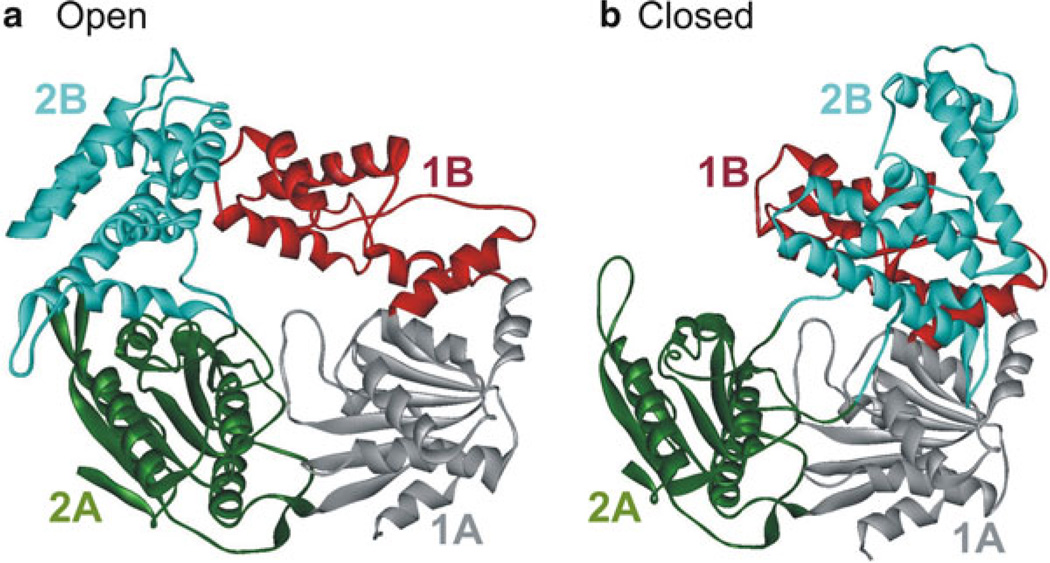
Crystal structure of E. coli Rep helicase (PDB code 1UAA [88]) in the open and closed conformations. Rep consists of four domains 1A, 1B, 2A, and 2B which are colored grey, red, green, and cyan, respectively. The open (a) and closed (b) conformations differ by rotations of around 130° of the 2B domain about a hinge region connecting it to the 2A domain [167]. The other domains are unchanged in both forms
References
-
- Caruthers JM, McKay DB. Helicase structure and mechanism. Curr Opin Struct Biol. 2002;12:123–133. - PubMed
-
- Delagoutte E, von Hippel PH. Helicase mechanisms and the coupling of helicases within macromolecular machines. Part II: integration of helicases into cellular processes. Q Rev Biophys. 2003;36:1–69. - PubMed
-
- Matson SW, Kaiser-Rogers KA. DNA helicases. Annu Rev Biochem. 1990;59:289–329. - PubMed
-
- Schmid SR, Linder P. D-E-A-D protein family of putative RNA helicases. Mol Microbiol. 1992;6:283–291. - PubMed
-
- Matson SW, Bean DW, George JW. DNA helicases: enzymes with essential roles in all aspects of DNA metabolism. Bioessays. 1994;16:13–22. - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
