

The plant short-chain dehydrogenase (SDR) superfamily: genome-wide inventory and diversification patterns
- PMID: 23167570
- PMCID: PMC3541173
- DOI: 10.1186/1471-2229-12-219
The plant short-chain dehydrogenase (SDR) superfamily: genome-wide inventory and diversification patterns
Abstract
Background: Short-chain dehydrogenases/reductases (SDRs) form one of the largest and oldest NAD(P)(H) dependent oxidoreductase families. Despite a conserved 'Rossmann-fold' structure, members of the SDR superfamily exhibit low sequence similarities, which constituted a bottleneck in terms of identification. Recent classification methods, relying on hidden-Markov models (HMMs), improved identification and enabled the construction of a nomenclature. However, functional annotations of plant SDRs remain scarce.
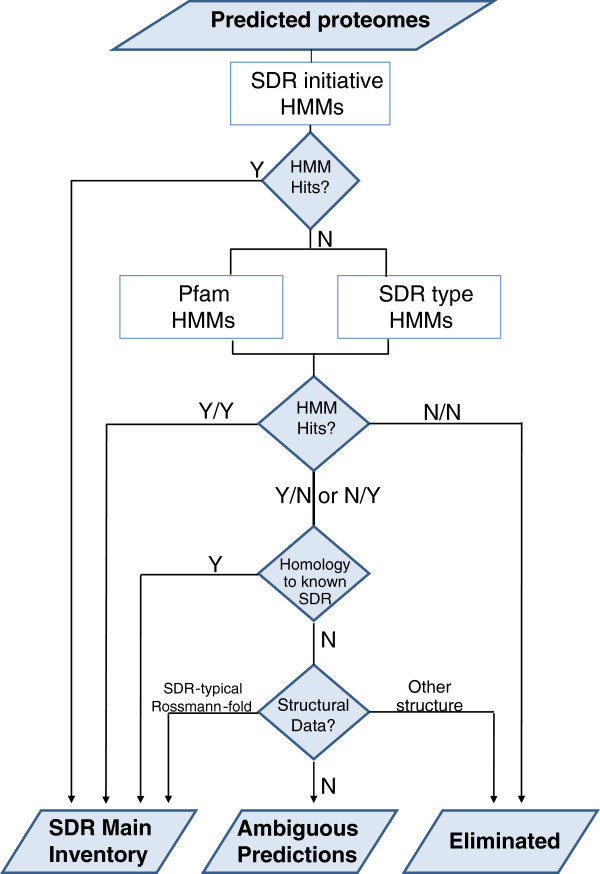
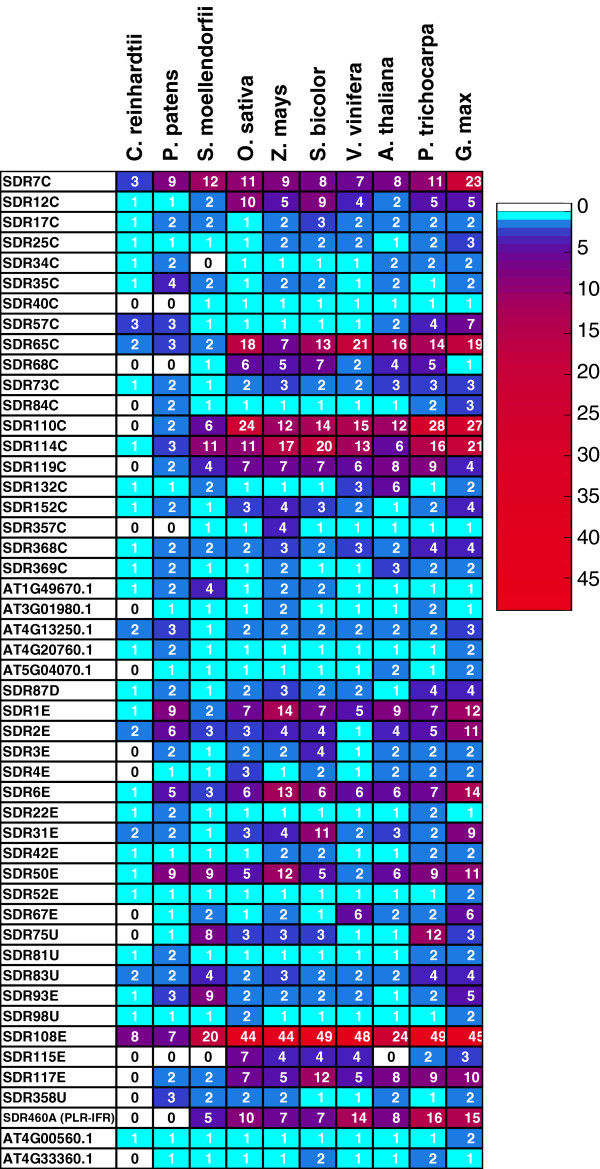
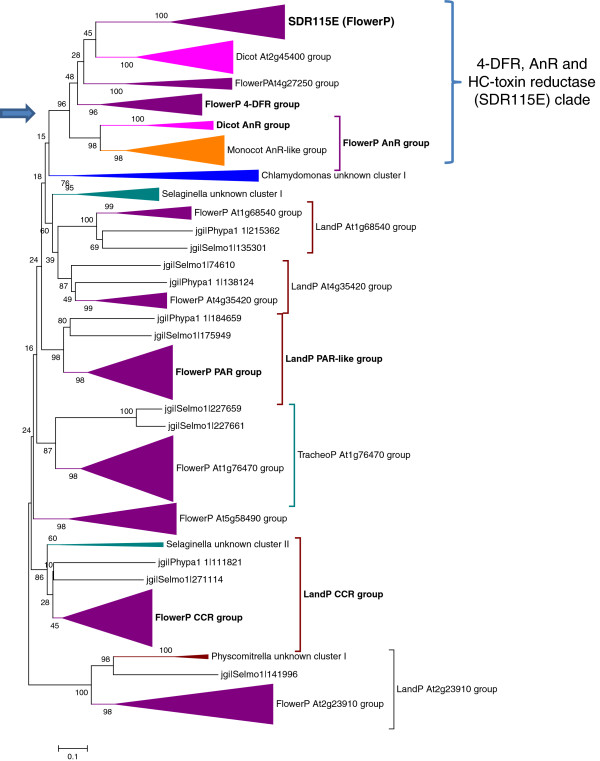
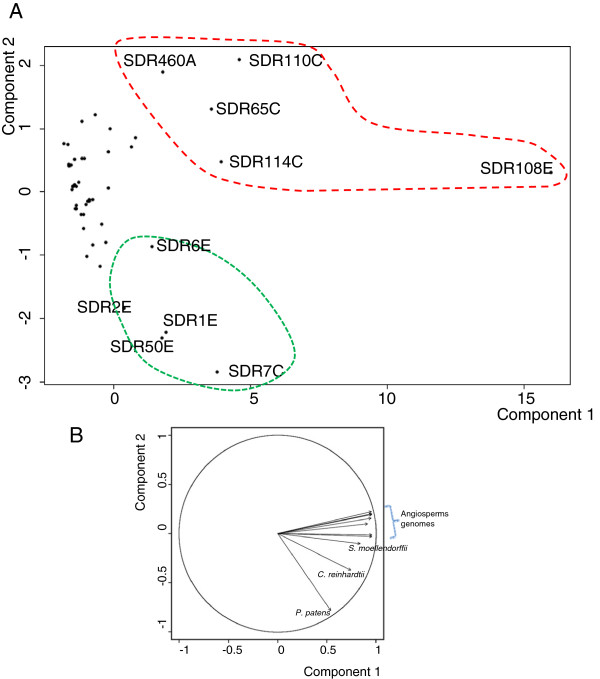
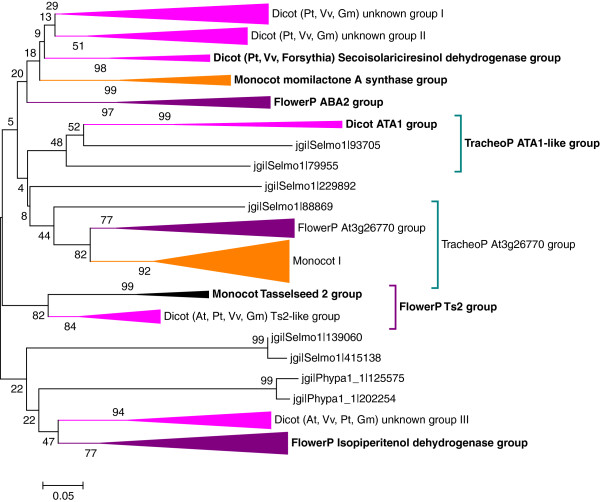
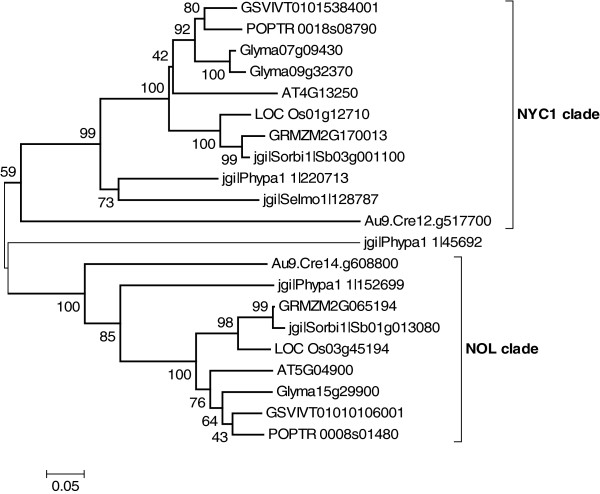
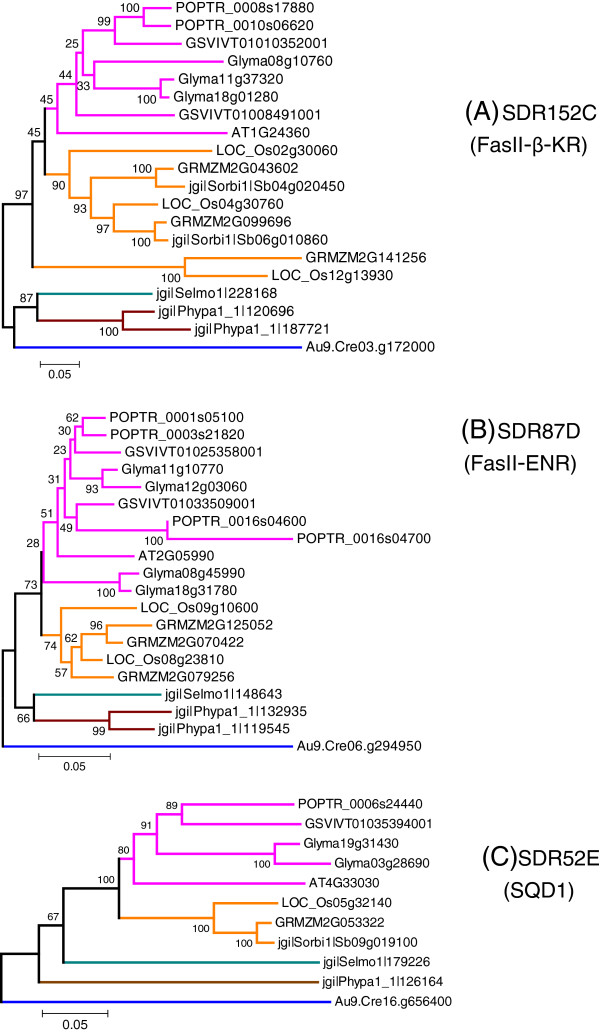
Results: Wide-scale analyses were performed on ten plant genomes. The combination of hidden Markov model (HMM) based analyses and similarity searches led to the construction of an exhaustive inventory of plant SDR. With 68 to 315 members found in each analysed genome, the inventory confirmed the over-representation of SDRs in plants compared to animals, fungi and prokaryotes. The plant SDRs were first classified into three major types - 'classical', 'extended' and 'divergent' - but a minority (10% of the predicted SDRs) could not be classified into these general types ('unknown' or 'atypical' types). In a second step, we could categorize the vast majority of land plant SDRs into a set of 49 families. Out of these 49 families, 35 appeared early during evolution since they are commonly found through all the Green Lineage. Yet, some SDR families - tropinone reductase-like proteins (SDR65C), 'ABA2-like'-NAD dehydrogenase (SDR110C), 'salutaridine/menthone-reductase-like' proteins (SDR114C), 'dihydroflavonol 4-reductase'-like proteins (SDR108E) and 'isoflavone-reductase-like' (SDR460A) proteins - have undergone significant functional diversification within vascular plants since they diverged from Bryophytes. Interestingly, these diversified families are either involved in the secondary metabolism routes (terpenoids, alkaloids, phenolics) or participate in developmental processes (hormone biosynthesis or catabolism, flower development), in opposition to SDR families involved in primary metabolism which are poorly diversified.
Conclusion: The application of HMMs to plant genomes enabled us to identify 49 families that encompass all Angiosperms ('higher plants') SDRs, each family being sufficiently conserved to enable simpler analyses based only on overall sequence similarity. The multiplicity of SDRs in plant kingdom is mainly explained by the diversification of large families involved in different secondary metabolism pathways, suggesting that the chemical diversification that accompanied the emergence of vascular plants acted as a driving force for SDR evolution.
Figures
References
-
- Kavanagh KL, Jörnvall H, Persson B, Oppermann U. Medium- and short-chain dehydrogenase/reductase gene and protein families: the SDR superfamily: functional and structural diversity within a family of metabolic and regulatory enzymes. Cell Mol Life Sci. 2008;65:3895–3906. doi: 10.1007/s00018-008-8588-y. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
