

doi: 10.1093/nar/gks1084.
Epub 2012 Nov 24.
The International Nucleotide Sequence Database Collaboration
Affiliations
- PMID: 23180798
- PMCID: PMC3531182
- DOI: 10.1093/nar/gks1084
Item in Clipboard
The International Nucleotide Sequence Database Collaboration
Nucleic Acids Res.
2013 Jan.
Abstract
The International Nucleotide Sequence Database Collaboration (INSDC; http://www.insdc.org), one of the longest-standing global alliances of biological data archives, captures, preserves and provides comprehensive public domain nucleotide sequence information. Three partners of the INSDC work in cooperation to establish formats for data and metadata and protocols that facilitate reliable data submission to their databases and support continual data exchange around the world. In this article, the INSDC current status and update for the year of 2012 are presented. Among discussed items of international collaboration meeting in 2012, BioSample database and changes in submission are described as topics.
Figures
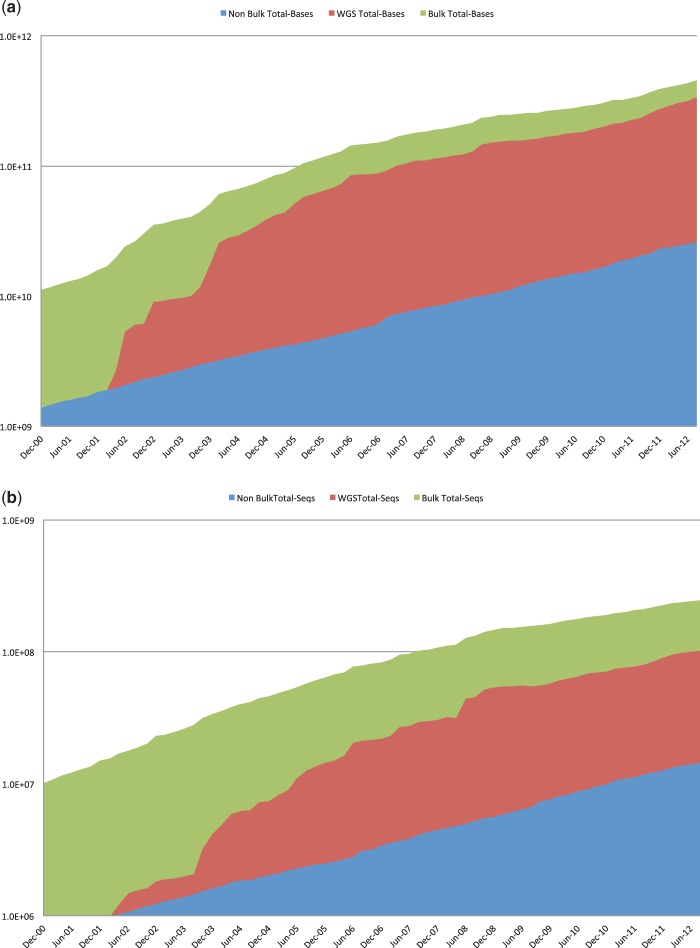
Cumulative growth (a) in the number of entry of sequences (b) in the number of nucleotides included in the traditional INSDC sequence archives over time. Bulk sequence data includes non-WGS bulk submission types, that is, Expressed Sequence Tag (EST), Genome Survey Sequence (GSS), Patent and Transcriptome Shotgun Assembly (TSA). Whole Genome Shotgun (WGS) includes the number of sequence overlap contigs. Non-bulk data are the remainder.
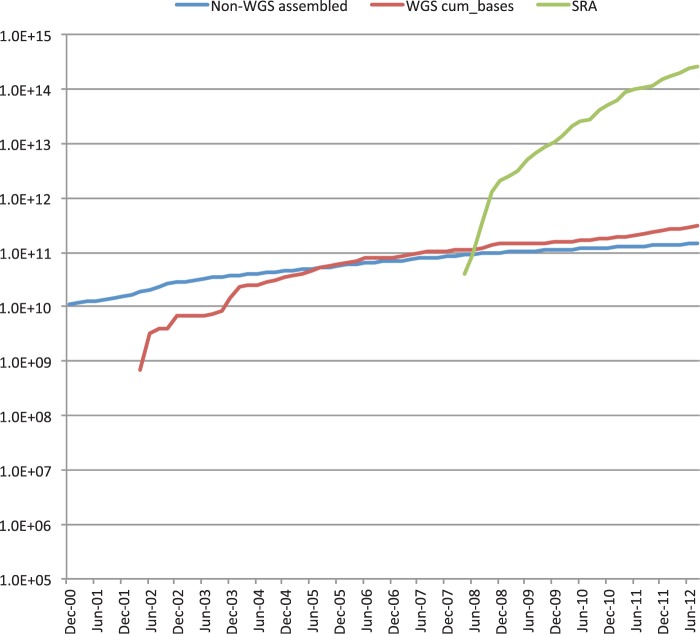
Cumulative base pairs in INSDC over time since 1980, broken down into selected data components. Data volume in base pairs of assembled sequence (whole genome shotgun methods and others) and raw next-generation-sequence data, excluding the Trace Archive (raw data from capillary sequencing platforms).
