

Data Quality in web-based HIV/AIDS research: Handling Invalid and Suspicious Data
- PMID: 23180978
- PMCID: PMC3505140
- DOI: 10.1177/1525822X12443097
Data Quality in web-based HIV/AIDS research: Handling Invalid and Suspicious Data
Abstract
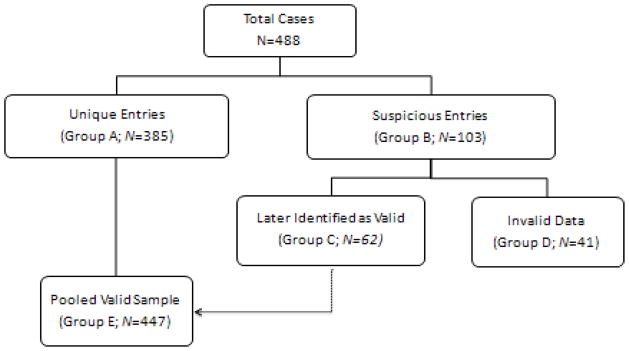
Invalid data may compromise data quality. We examined how decisions taken to handle these data may affect the relationship between Internet use and HIV risk behaviors in a sample of young men who have sex with men (YMSM). We recorded 548 entries during the three-month period, and created 6 analytic groups (i.e., full sample, entries initially tagged as valid, suspicious entries, valid cases mislabeled as suspicious, fraudulent data, and total valid cases) using data quality decisions. We compared these groups on the sample's composition and their bivariate relationships. Forty-one cases were marked as invalid, affecting the statistical precision of our estimates but not the relationships between variables. Sixty-two additional cases were flagged as suspicious entries and found to contribute to the sample's diversity and observed relationships. Using our final analytic sample (N = 447; M = 21.48 years old, SD = 1.98), we found that very conservative criteria regarding data exclusion may prevent researchers from observing true associations. We discuss the implications of data quality decisions and its implications for the design of future HIV/AIDS web-surveys.
Figures
References
-
- Couper M. Designing Effective Web Surveys. Cambridge, MA: Cambridge University Press; 2008.
-
- Konstan J, Simon-Rosser B, Ross M, Stanton J, Edwards W. The story of subject naught: A cautionary but optimistic tale of Internet survey research. Journal of Computer-Mediated Communication. 2005;10(2):article 11.
Grants and funding
LinkOut - more resources
Full Text Sources