

Updating dopamine reward signals
- PMID: 23267662
- PMCID: PMC3866681
- DOI: 10.1016/j.conb.2012.11.012
Updating dopamine reward signals
Abstract
Recent work has advanced our knowledge of phasic dopamine reward prediction error signals. The error signal is bidirectional, reflects well the higher order prediction error described by temporal difference learning models, is compatible with model-free and model-based reinforcement learning, reports the subjective rather than physical reward value during temporal discounting and reflects subjective stimulus perception rather than physical stimulus aspects. Dopamine activations are primarily driven by reward, and to some extent risk, whereas punishment and salience have only limited activating effects when appropriate controls are respected. The signal is homogeneous in terms of time course but heterogeneous in many other aspects. It is essential for synaptic plasticity and a range of behavioural learning situations.
Copyright © 2012 Elsevier Ltd. All rights reserved.
Figures
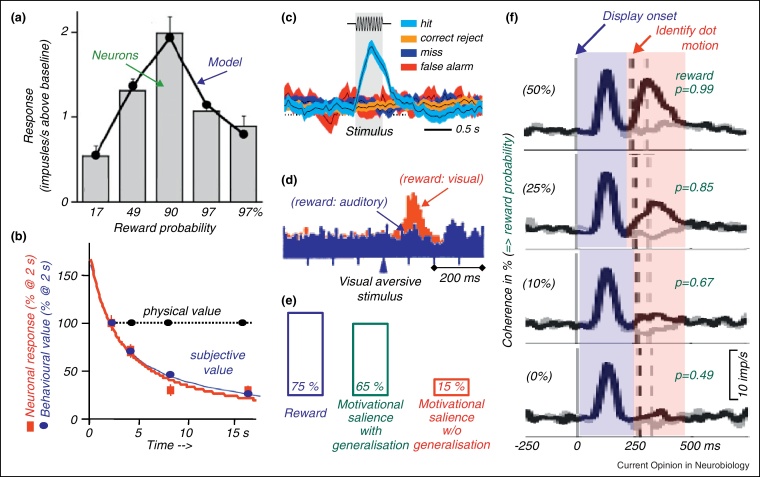
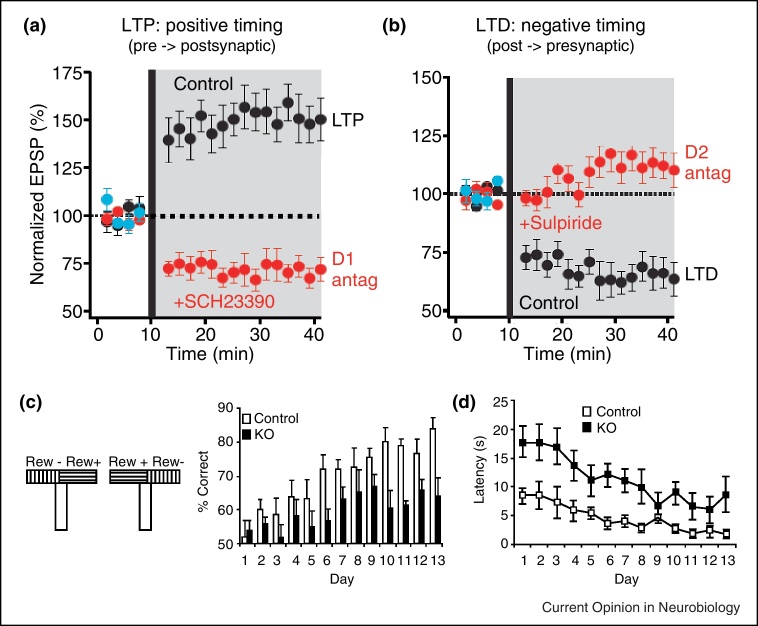
References
-
- Schultz W. Predictive reward signal of dopamine neurons. J Neurophysiol. 1998;80:1–27. - PubMed
-
- Nomoto K., Schultz W., Watanabe T., Sakagami M. Temporally extended dopamine responses to perceptually demanding reward-predictive stimuli. J Neurosci. 2010;30:10692–10702. - PMC - PubMed
-
Dopamine neurons show two well separated error response components to reward predicting stimuli in a random dot motion task.
-
- Enomoto K., Matsumoto N., Nakai S., Satoh T., Sato T.K., Ueda Y., Inokawa H., Haruno M., Kimura M. Dopamine neurons learn to encode the long-term value of multiple future rewards. Proc Natl Acad Sci USA. 2011;108:15462–15467. - PMC - PubMed
-
The most advanced neurophysiological study to date relating dopamine responses to TD learning.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
