

A Multiple Object Geometric Deformable Model for Image Segmentation
- PMID: 23316110
- PMCID: PMC3539759
- DOI: 10.1016/j.cviu.2012.10.006
A Multiple Object Geometric Deformable Model for Image Segmentation
Abstract
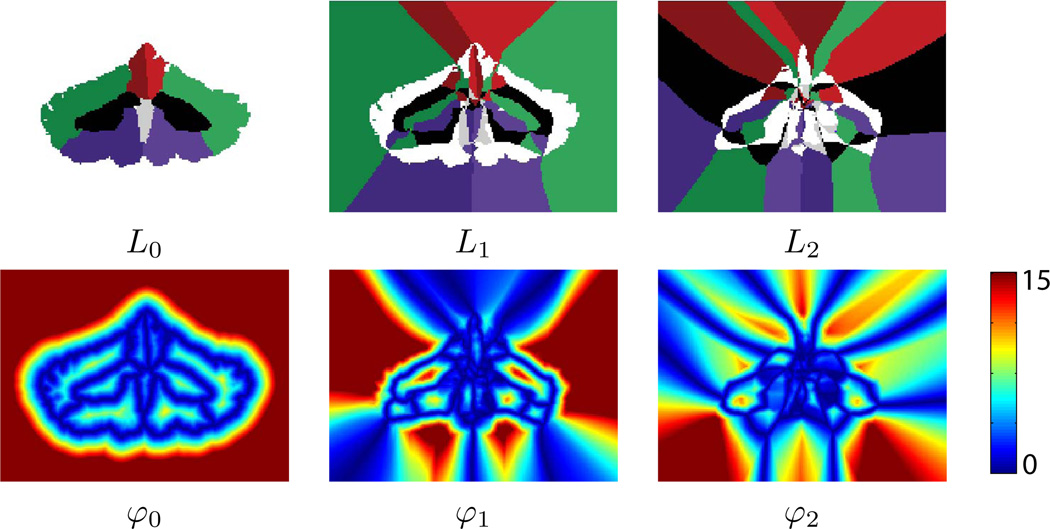
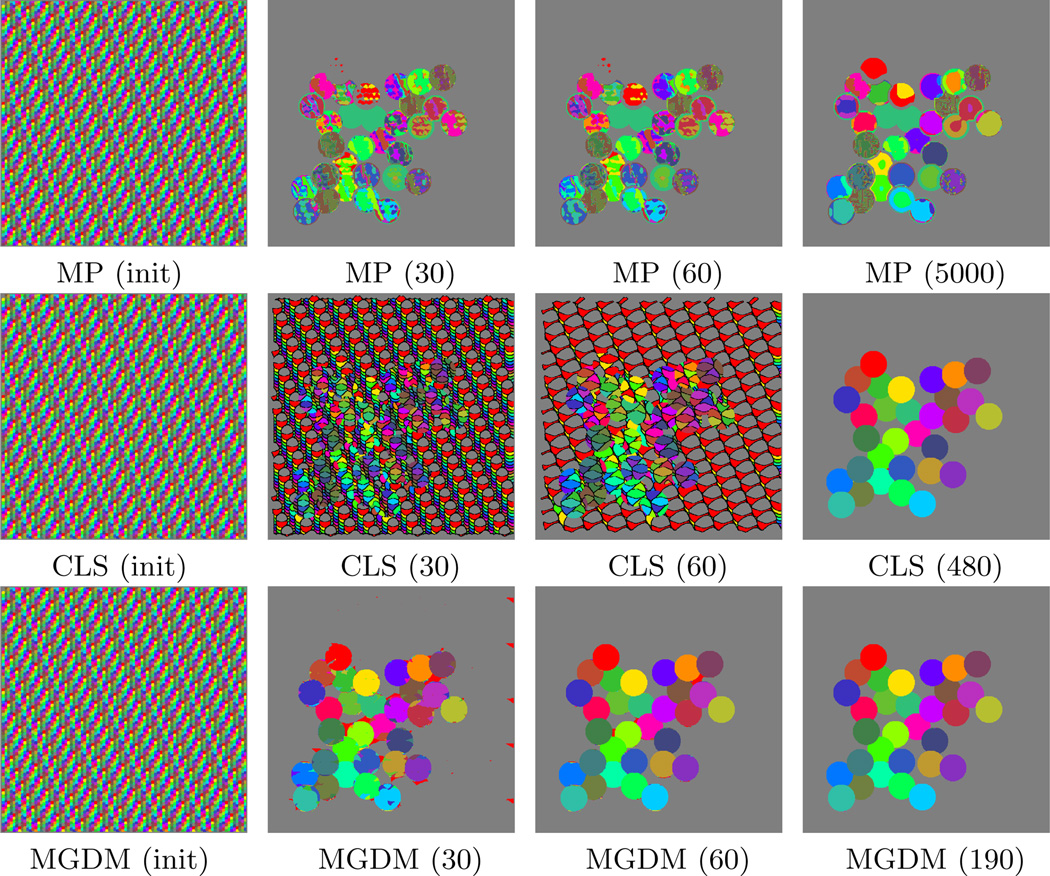
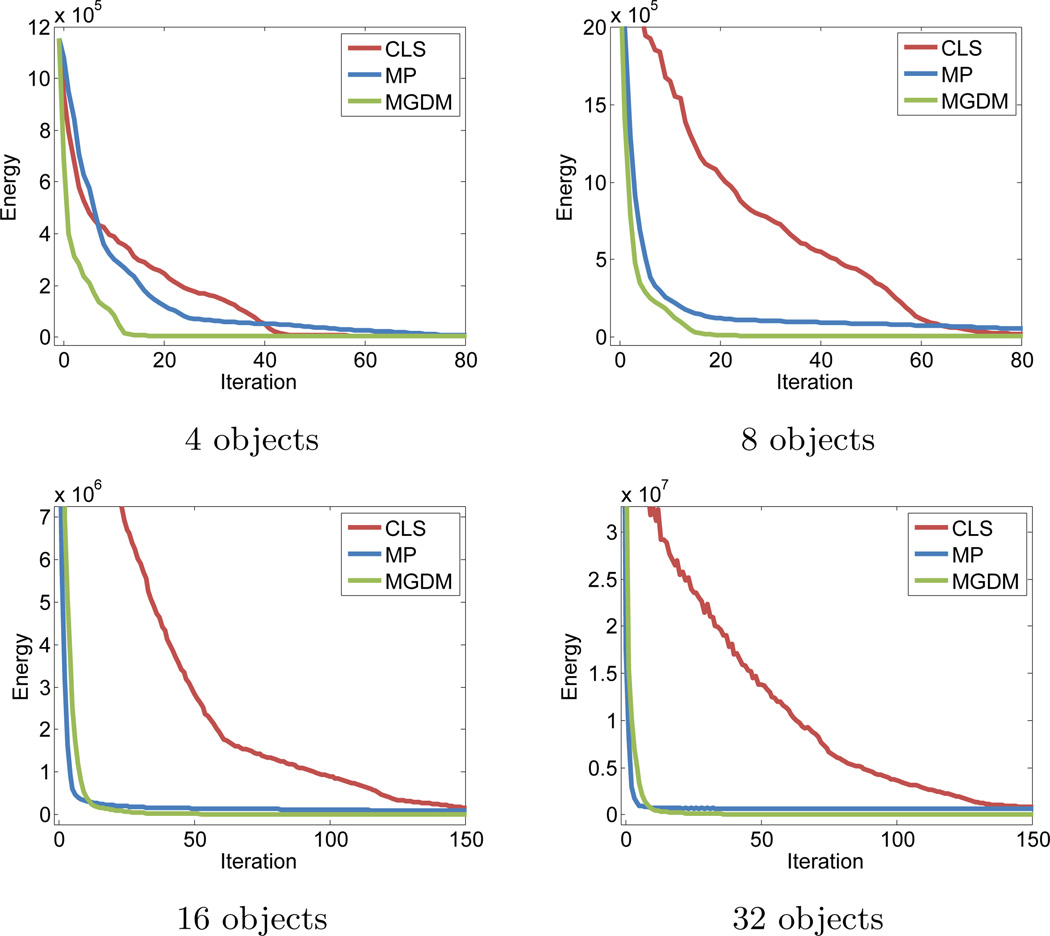
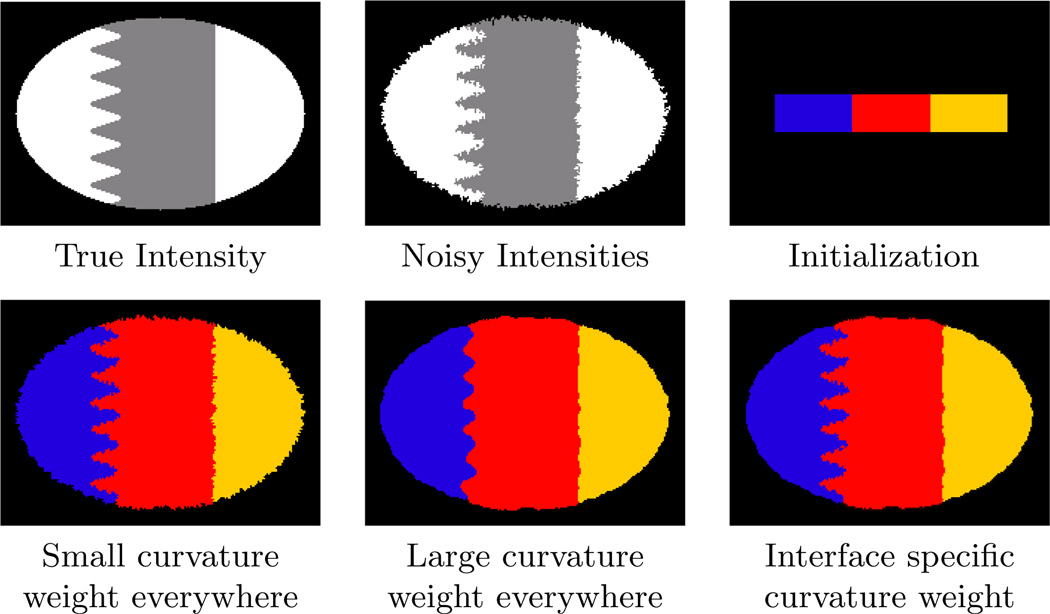
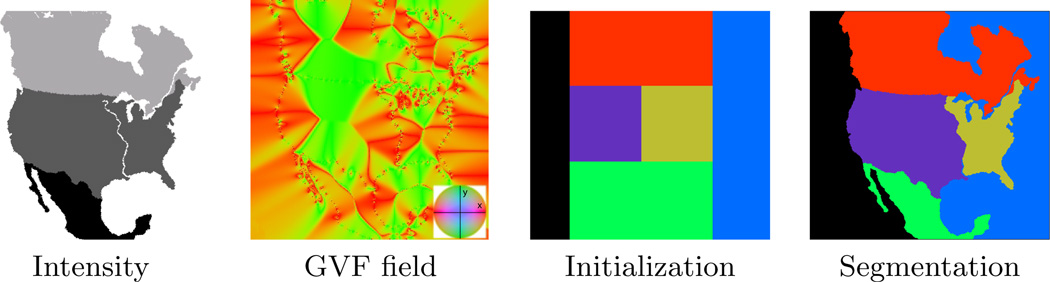
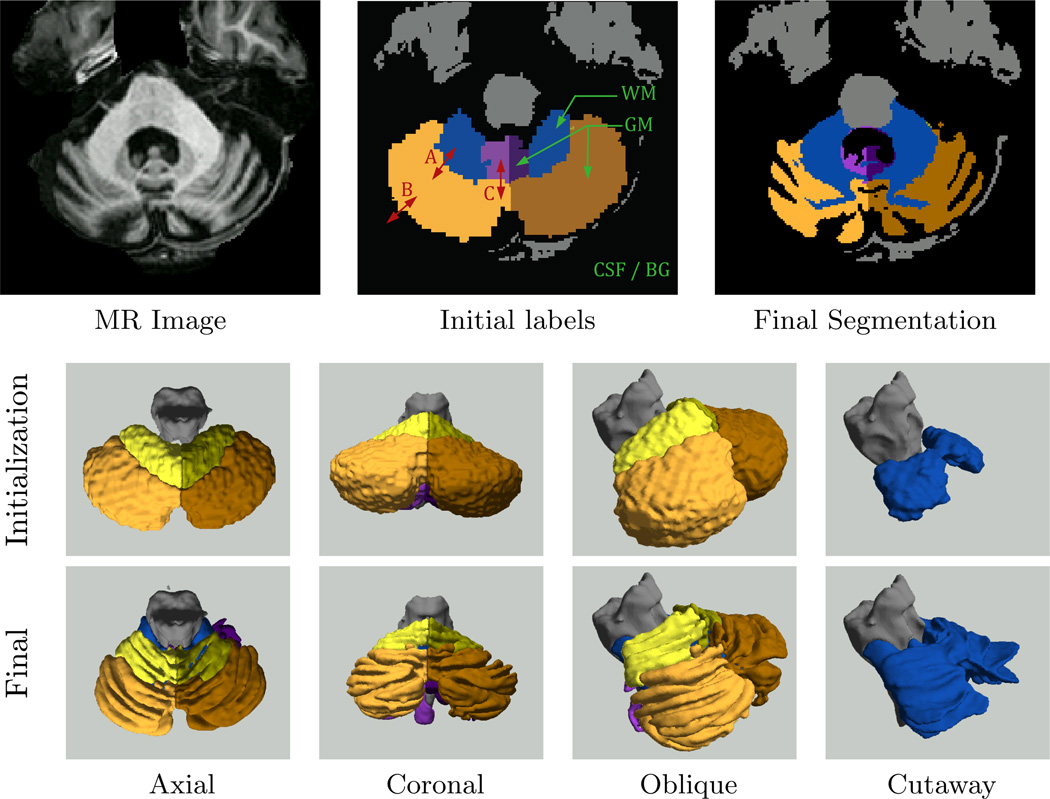
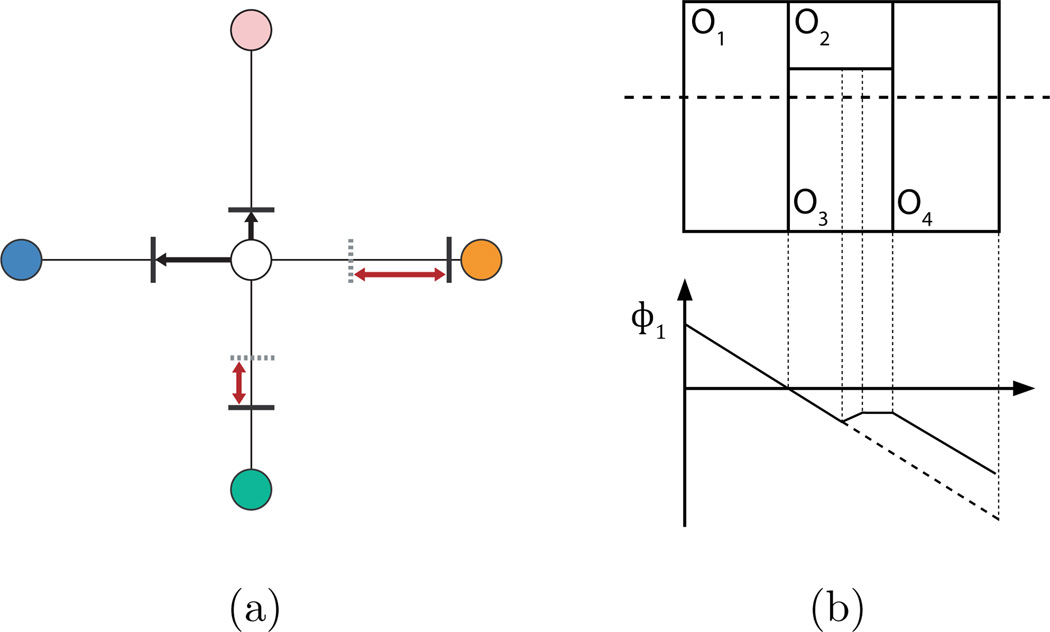
Deformable models are widely used for image segmentation, most commonly to find single objects within an image. Although several methods have been proposed to segment multiple objects using deformable models, substantial limitations in their utility remain. This paper presents a multiple object segmentation method using a novel and efficient object representation for both two and three dimensions. The new framework guarantees object relationships and topology, prevents overlaps and gaps, enables boundary-specific speeds, and has a computationally efficient evolution scheme that is largely independent of the number of objects. Maintaining object relationships and straightforward use of object-specific and boundary-specific smoothing and advection forces enables the segmentation of objects with multiple compartments, a critical capability in the parcellation of organs in medical imaging. Comparing the new framework with previous approaches shows its superior performance and scalability.
Figures

References
-
- Fischl B, Salat DH, Busa E, Albert M, Dieterich M, Haselgrove C, van der Kouwe A, Killiany R, Kennedy D, Klaveness S, Montillo A, Makris N, Rosen B, Dale AM. Whole brain segmentation: automated labeling of neuroanatomical structures in the human brain. Neuron. 2002;33(3):341–355. - PubMed
-
- Okada T, Shimada R, Sato Y, Hori M, Yokota K, Nakamoto M, Chen Y-W, Nakamura H, Tamura S. Automated segmentation of the liver from 3D CT images using probabilistic atlas and multi-level statistical shape model. Proc. MICCAI. 2007;10:86–93. - PubMed
-
- Heimann T, Münzing S, Meinzer H-P, Wolf I. A shape-guided deformable model with evolutionary algorithm initialization for 3D soft tissue segmentation. Proc. IPMI. 2007:1–12. - PubMed
-
- Lu C, Pizer SM, Joshi S, Jeong J-Y. Statistical Multi-Object Shape Models. International Journal of Computer Vision. 2007;75(3):387–404.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources