

Review
doi: 10.1016/j.febslet.2012.12.029.
Epub 2013 Jan 18.
Trendspotting in the Protein Data Bank
Affiliations
- PMID: 23337870
- PMCID: PMC4068610
- DOI: 10.1016/j.febslet.2012.12.029
Item in Clipboard
Review
Trendspotting in the Protein Data Bank
FEBS Lett.
.
Abstract
The Protein Data Bank (PDB) was established in 1971 as a repository for the three dimensional structures of biological macromolecules. Since then, more than 85000 biological macromolecule structures have been determined and made available in the PDB archive. Through analysis of the corpus of data, it is possible to identify trends that can be used to inform us abou the future of structural biology and to plan the best ways to improve the management of the ever-growing amount of PDB data.
Copyright © 2013 Federation of European Biochemical Societies. Published by Elsevier B.V. All rights reserved.
Figures
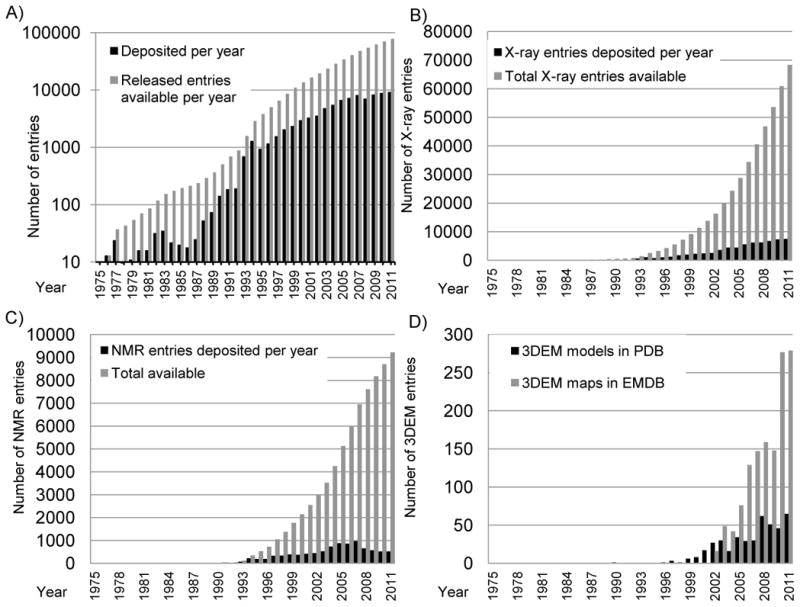
Growth of the PDB archive. A) Depositions per year are shown in black and total released entries available in gray on a logarithmic scale. Reprinted from Berman [46] with permission from Wiley; B) Growth of depositions from X-ray crystallography. Depositions per year are shown in black and total released entries available in light gray; C) Growth in depositions from NMR. Depositions per year are shown in black and total released entries available in light gray; D) Growth in depositions from 3DEM. Depositions per year of 3DEM maps are shown in light gray and depositions per year of model coordinates in black.
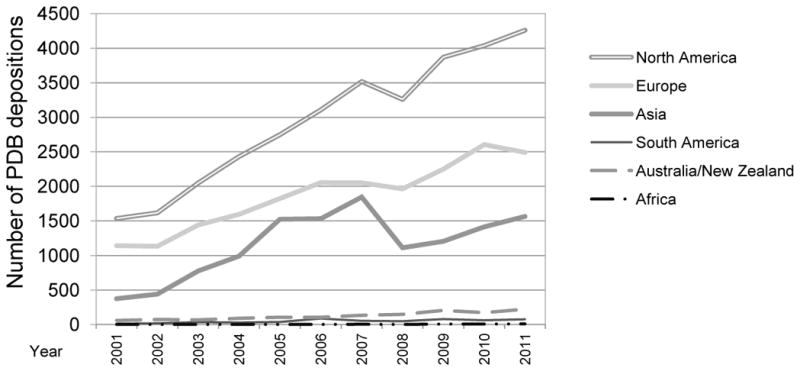
Number of PDB entries deposited per year by continent.
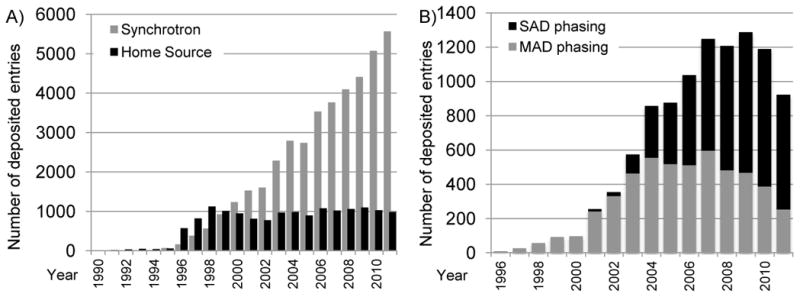
Use of synchrotron radiation in the PDB. A) The number of structures determined using synchrotron radiation deposited per year is shown in grey; the number using home-laboratory sources in black. This plot shows that while the use of home sources for X-ray structure determination has remained roughly constant, the use of synchrotron sources has increased rapidly. Reprinted from Berman [46] with permission from Wiley. B) Use of SAD (in black) and MAD (in gray) phasing in PDB entries deposited per year. After an initial growth in MAD phasing, SAD phasing has become more widely used.
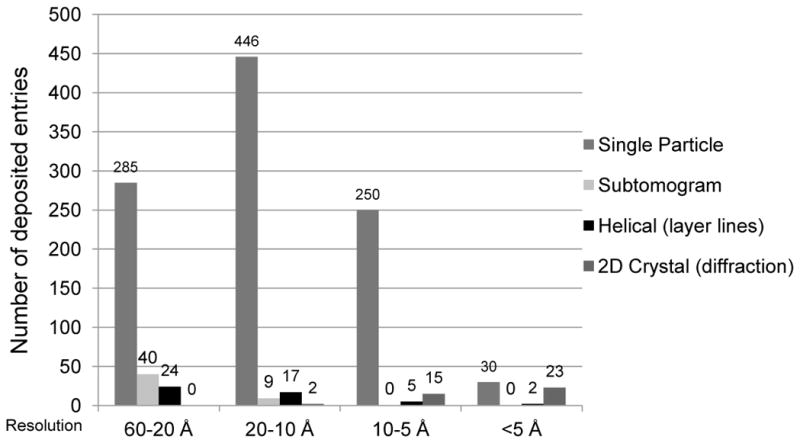
3DEM structures released in the PDB and EMDB [25] by resolution range and reconstruction method. Structures archived in the PDB were represented in this plot exclusively by method and not by mixed type. “Helical” represents the traditional layer-line approach, and “2D Crystal” denotes electron crystallography. Helical structures solved using the single particle approach are grouped under “Single Particle;” two-dimensional crystal structures solved exclusively using subtomogram averaging with no calculation of structure factors from images or measurement of structure factor intensities were grouped under “Subtomogram.” The graph represents 1148 total deposited EM structures encompassing 1146 maps deposited to EMDB and 415 models deposited to PDB. These include 840 map-only structures, 277 maps with one or more associated PDB models, and 31 electron crystallography PDB entries.
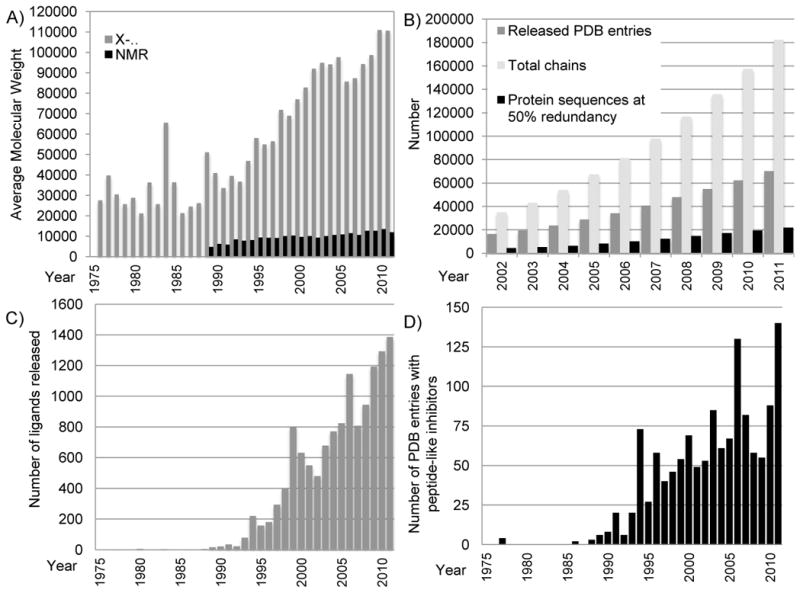
Growth in the size and complexity of PDB entries. A) Average molecular weight of entries released each year for structures determined by X-ray crystallography (for the asymmetric unit; in grey) and NMR (in black). Calculations excluded water and counted extremely large structures as single entries. For viruses and entries that used non-crystallographic symmetry (NCS), molecular weights for the full asymmetric unit were calculated by multiplying the molecular weight of the explicit polymer chains by the number of NCS operators. The large increase shown in 1984 was due to the release of the tomato bushy stunt virus 2tbv [47]. B) The number of PDB entries, total related polymer chains, and protein sequences (with 50% redundancy as calculated using blastclust [48]) available in the archive each year. C) The number of unique non-polymer ligands released each year (a single entry may have several ligands). There are three notable peaks: 73 structures with an inhibitor/antibiotic were released in 1994, the majority of which are thrombin inhibitors and renin inhibitors; 130 structures in 2006, the majority of which are thrombin inhibitors and other protease inhibitors; and 140 structures in 2011, the majority of which are protease inhibitors, including caspase inhibitors. Figures B & C reprinted from Berman [46] with permission from Wiley. D) The number of peptide-like inhibitor/antibiotic entries released per year.
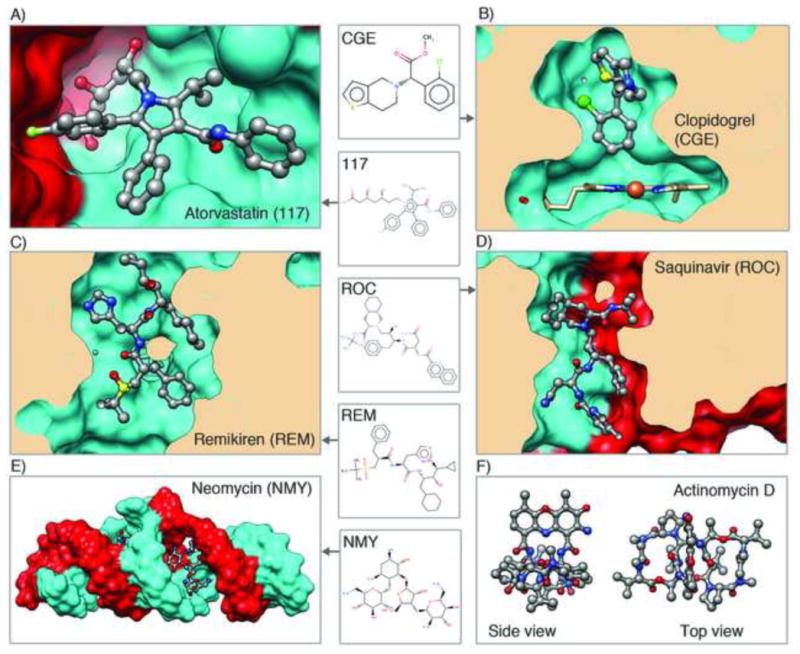
Examples of molecules in the PDB that are or have been used as drugs, shown in ball and stick. For each, the corresponding 3-character code from the Chemical Component Dictionary is listed. Blockbuster drugs shown are A) atorvastatin bound to HMG-CoA reductase, a key enzyme in the cholesterol biosynthesis pathway (PDB ID 1hwk [49]) and B) clopidogrel bound to cytochrome P450 2B4, which activates the prodrug (PDB ID 3me6 [50]); Peptidomimetic inhibitors shown are C) remikiren bound to human renin (PDB ID 3d91 [51]) and D) saquinavir bound to HIV protease (PDB ID 1hxb [52]). E) Aminoglycoside antibiotic shown is neomycin bound to extended duplex RNA (PDB ID 3c7r [53]). F) Peptide-like antibiotic/antitumor agent actinomycin D structure (PDB ID 1a7y [54])
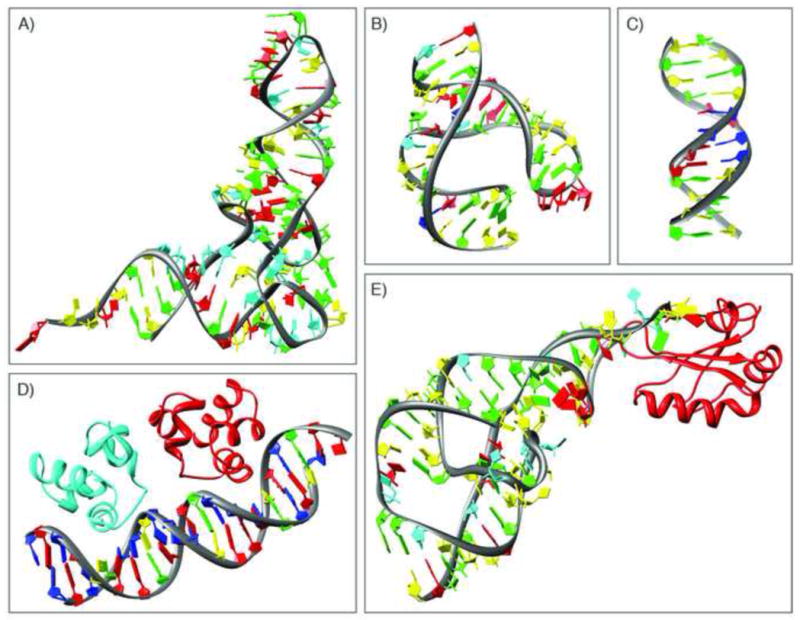
Examples of some of the early nucleic-acid containing structures. A) yeast tRNA-Phe (PDB ID 4tna [55]); B) hammerhead ribozyme (PDB ID 1hmh [30]); c) B-DNA dodecamer (PDB ID 1bna [29]); D) complex of the DNA operator and the phage 434 repressor (PDB ID 2or1 [56]); E) hepatitis delta virus ribozyme (PDB ID 1drz [57]).
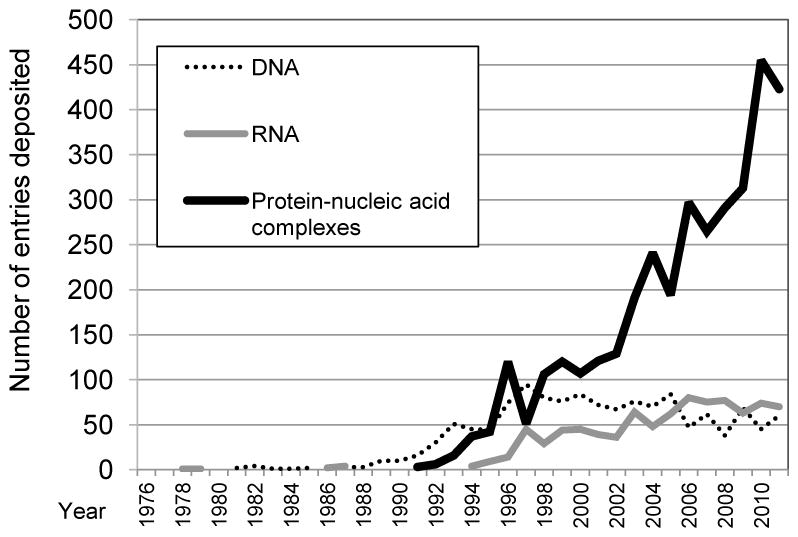
Growth in the number of depositions per year for nucleic acid-containing entries.
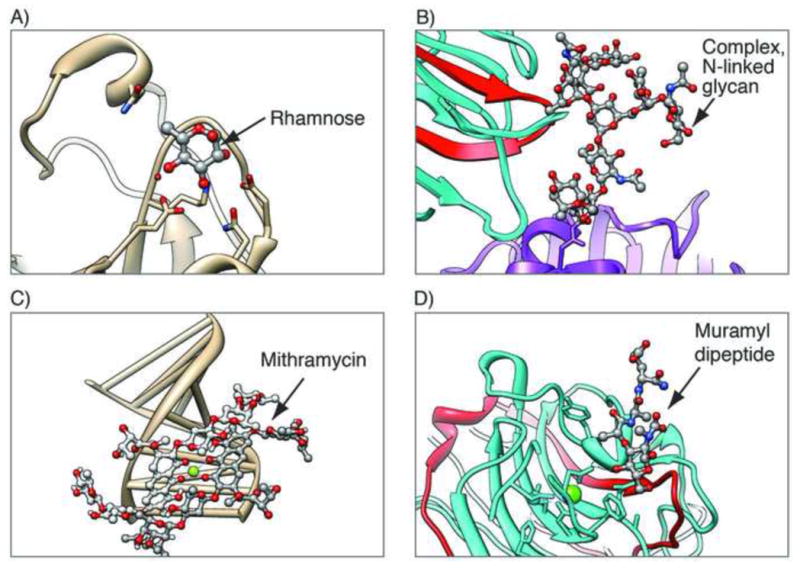
Examples of carbohydrate-containing entries, with the carbohydrates shown in ball and stick. A) Single unbound monosaccharide, rhamnose, in the structure of rhamnose-binding lectin, a pattern recognition protein with a role in innate immunity (PDB ID 2zx2 [58]); B) Polymeric glycoprotein in glycosylated human lactotransferrin N2 fragment (purple) in complex with legume lectin chains (cyan and red, PDB ID 1lg2 [59]); C) Polysaccharide antitumor drug mithramycin bound to a DNA fragment (PDB ID 1bp8 [32]); D) Mixed polymers: bacterial cell wall muramyl peptide (peptidoglycan) bound to legume isolectin chains (cyan and red, PDB ID 1loc [33])
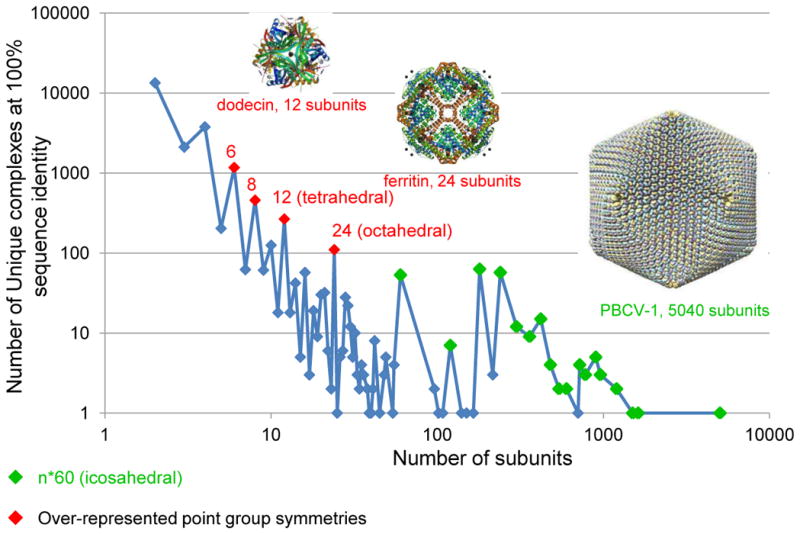
Distribution of unique protein complexes by the number of protein subunits. Any peptide chain with 24 or more residues is considered a protein subunit. The number of over-represented point group symmetries are in red; viral capsids with n*60 subunits are marked in green. The number of complexes decreases with the number of subunits, with a few exceptions. There are fewer complexes with an odd number of subunits than there are complexes with an even number of subunits. Examples shown are dodecin (PDB ID 2yiz [60]), ferritin (PDB ID 1aew [61]), and Paramecium bursaria Chlorella virus type 1 (PDB ID 1m4x [62]).
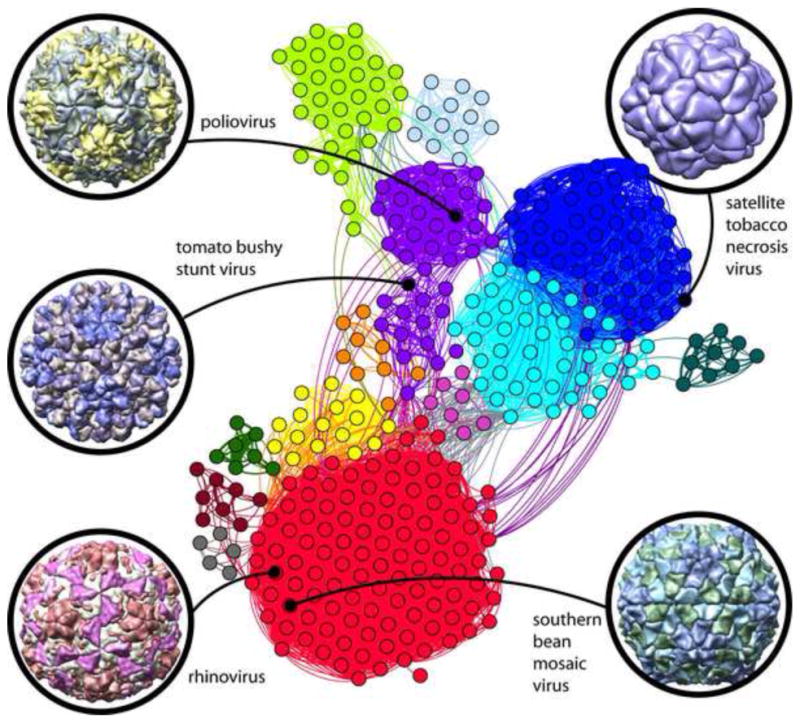
Strongly interconnected research community built around early virus structures. The network diagram shown at center illustrates author relationships among icosahedral virus structures deposited in the PDB. Structures are represented as nodes (circles); a curved line connects pairs of nodes where one or more authors are shared in common. The highest connectivity densities define thirteen major author clusters. Color key/cluster principle investigators: red: M.G. Rossmann, T.S. Baker; blue: L. Liljas, S.E.V. Phillips, P.G. Stockley; cyan: J.E. Johnson; purple: S.C. Harrison, J.M. Hogle; light green: D.I. Stuart, E.E. Fry, Z. Rao; yellow: M. Agbandje-McKenna; light blue: M.R.N. Murthy; orange: H. Zhou; dark cyan: A. McPherson; dark red: M.S. Chapman; pink: T. Tsukihara; dark green: W. Chiu; grey: E. Arnold. The nodes belonging to the first five structures are identified for reference: tomato bushy stunt virus (PDB ID 2tbv [47]), southern bean mosaic virus (PDB ID 4sbv [63]), satellite tobacco necrosis virus (PDB ID 2buk [37]), rhinovirus (PDB ID 4rhv [64]), and poliovirus (PDB ID 2plv [65]). Gephi [66] was used for cluster analysis of 375 icosahedral virus PDB entries connected by 364 deposition authors.
References
-
- Protein Data Bank. Protein Data Bank. Nature New Biol. 1971:233, 223.
-
- Berman H. The Protein Data Bank: a historical perspective. Acta Crystallogr A: Foundations of Crystallography. 2008;64:88–95. - PubMed
-
- International Union of Crystallography. Policy on publication and the deposition of data from crystallographic studies of biological macromolecules. Acta Cryst. 1989;A45:658.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
