

The sparseness of mixed selectivity neurons controls the generalization-discrimination trade-off
- PMID: 23447596
- PMCID: PMC6119179
- DOI: 10.1523/JNEUROSCI.2753-12.2013
The sparseness of mixed selectivity neurons controls the generalization-discrimination trade-off
Abstract
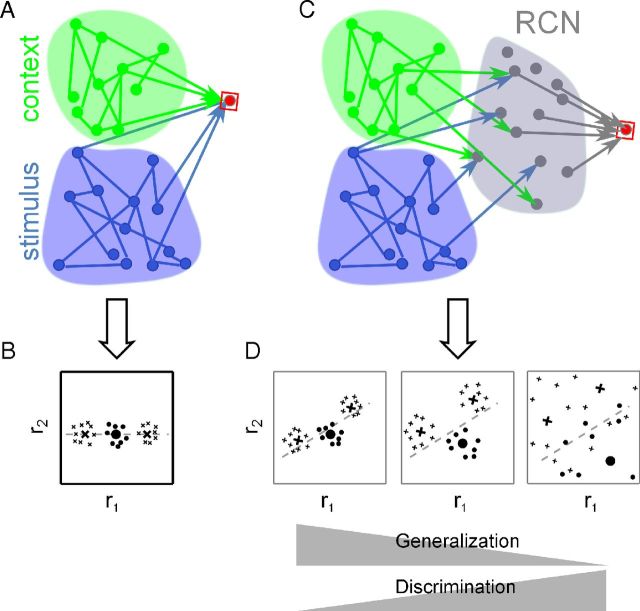
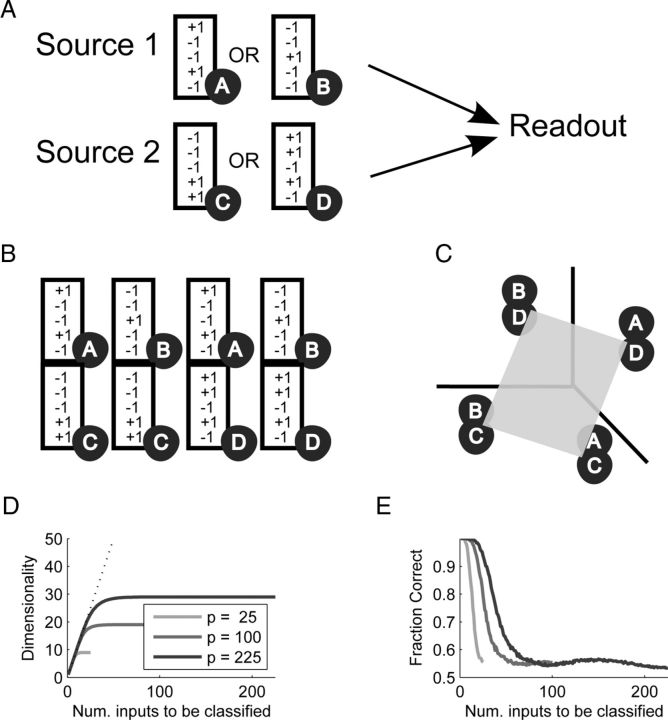
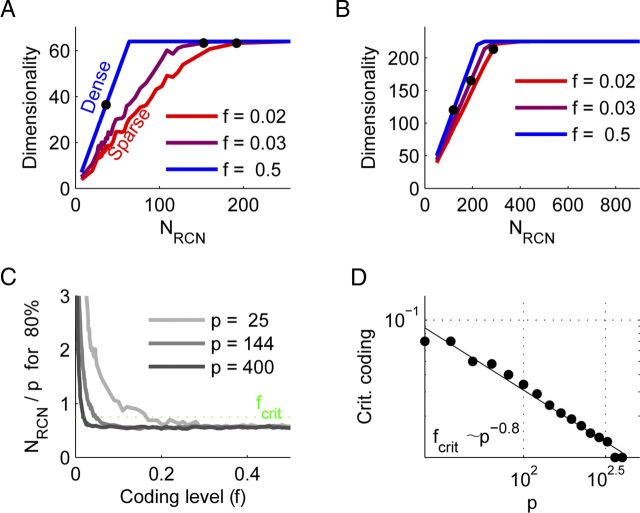
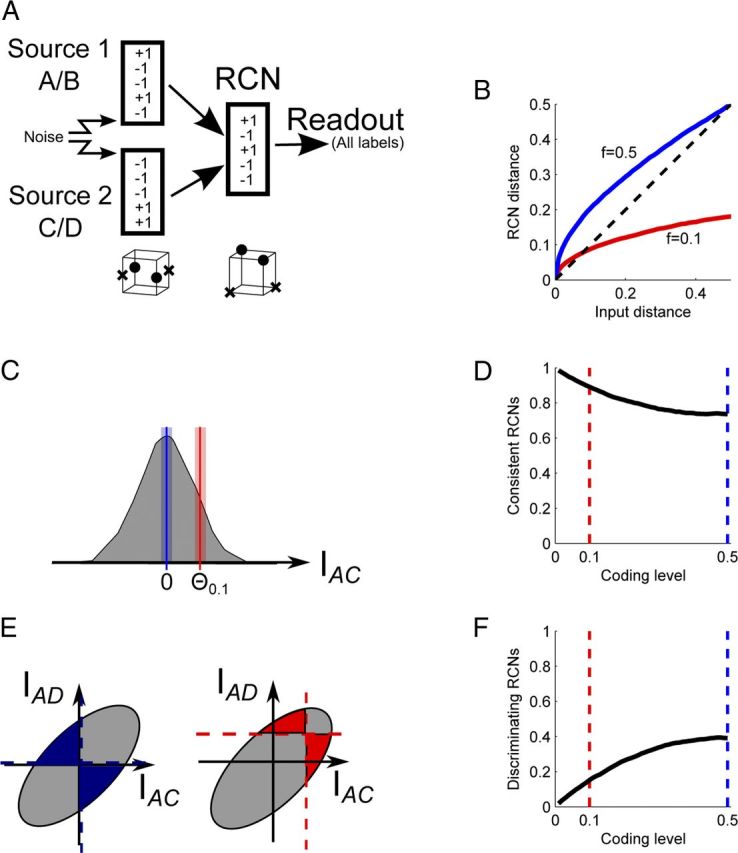
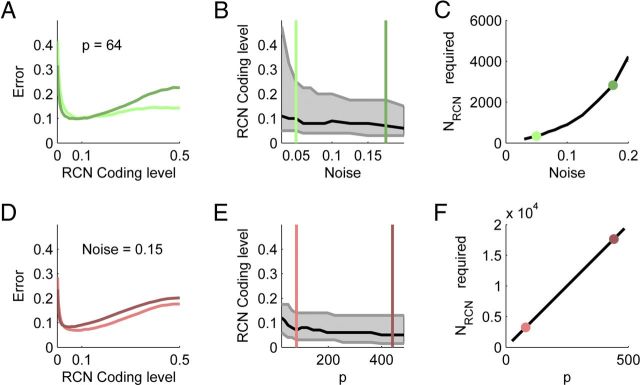
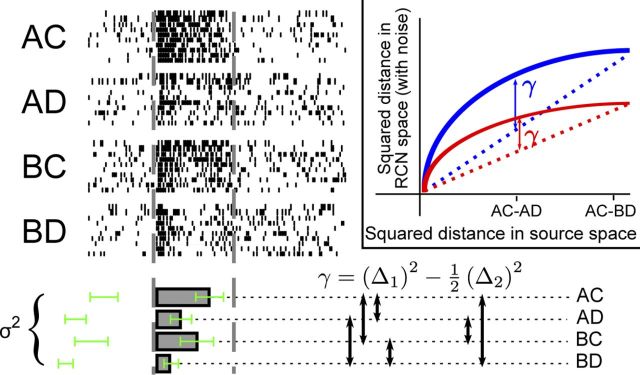
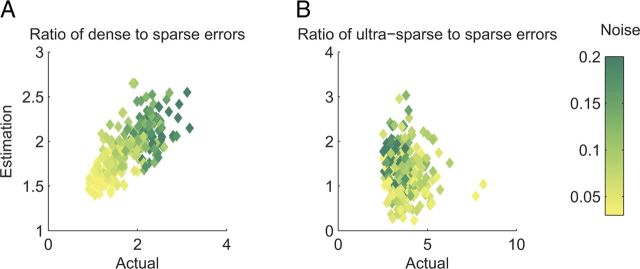
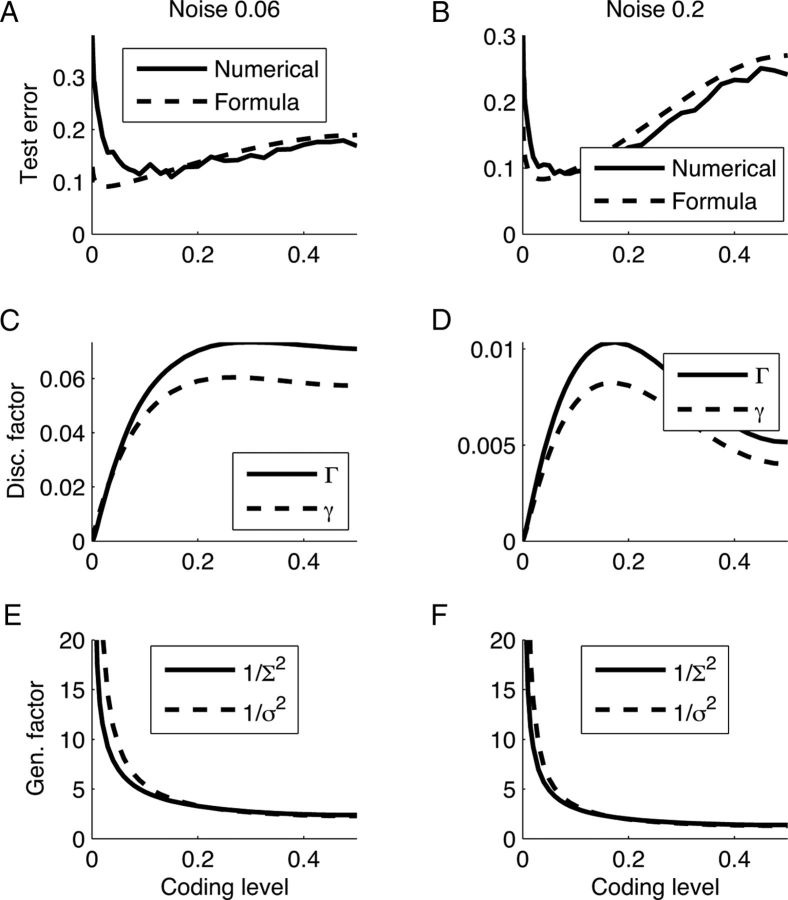
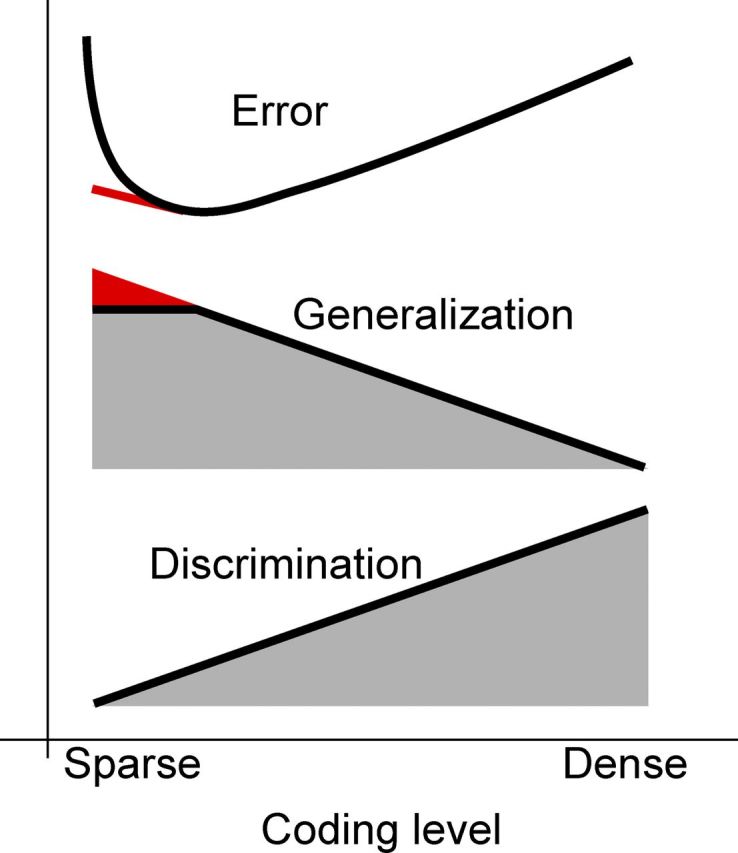
Intelligent behavior requires integrating several sources of information in a meaningful fashion-be it context with stimulus or shape with color and size. This requires the underlying neural mechanism to respond in a different manner to similar inputs (discrimination), while maintaining a consistent response for noisy variations of the same input (generalization). We show that neurons that mix information sources via random connectivity can form an easy to read representation of input combinations. Using analytical and numerical tools, we show that the coding level or sparseness of these neurons' activity controls a trade-off between generalization and discrimination, with the optimal level depending on the task at hand. In all realistic situations that we analyzed, the optimal fraction of inputs to which a neuron responds is close to 0.1. Finally, we predict a relation between a measurable property of the neural representation and task performance.
Figures
References
-
- Amit DJ, Fusi S. Learning in neural networks with material synapses. Neural Comput. 1994;6:957–982.
-
- Asaad WF, Rainer G, Miller EK. Neural activity in the primate prefrontal cortex during associative learning. Neuron. 1998;21:1399–1407. - PubMed
-
- Atick JJ, Redlich AN. What does the retina know about natural scenes? Neural Comput. 1992;4:196–210.
-
- Barak O, Rigotti M. A simple derivation of a bound on the perceptron margin using singular value decomposition. Neural Comput. 2011;23:1935–1943.
-
- Barnes CA, McNaughton BL, Mizumori SJ, Leonard BW, Lin LH. Comparison of spatial and temporal characteristics of neuronal activity in sequential stages of hippocampal processing. Prog Brain Res. 1990;83:287–300. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources