

Evaluating Amazon's Mechanical Turk as a tool for experimental behavioral research
- PMID: 23516406
- PMCID: PMC3596391
- DOI: 10.1371/journal.pone.0057410
Evaluating Amazon's Mechanical Turk as a tool for experimental behavioral research
Abstract
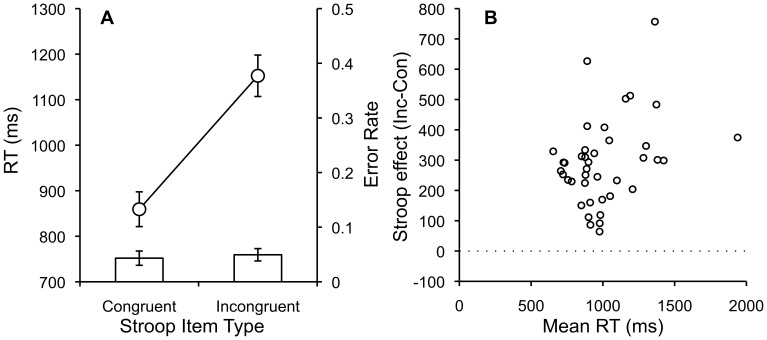
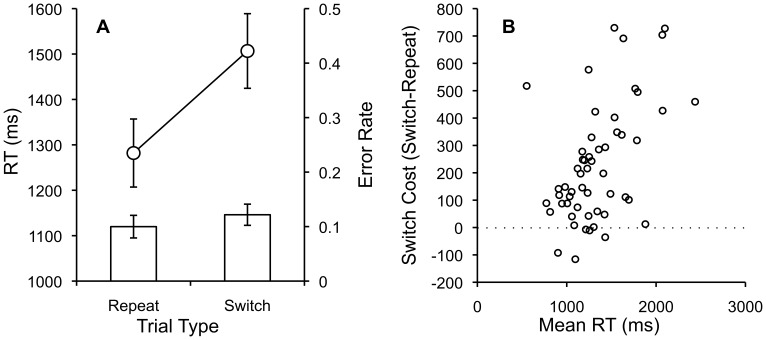
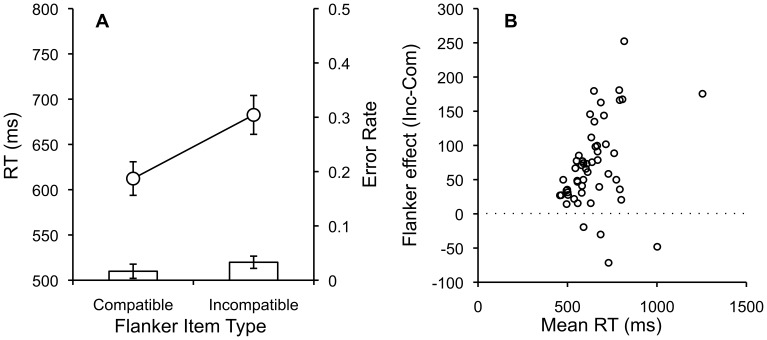
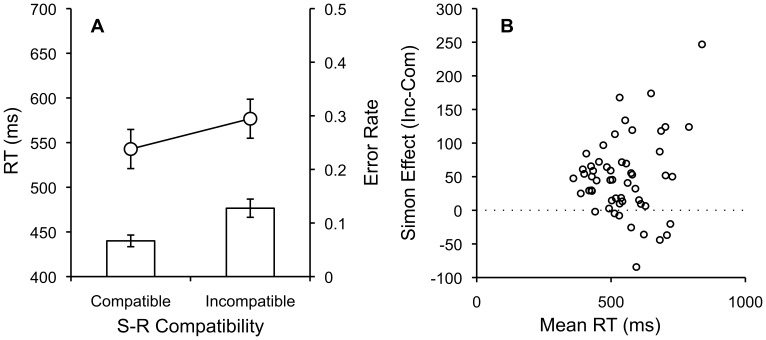
Amazon Mechanical Turk (AMT) is an online crowdsourcing service where anonymous online workers complete web-based tasks for small sums of money. The service has attracted attention from experimental psychologists interested in gathering human subject data more efficiently. However, relative to traditional laboratory studies, many aspects of the testing environment are not under the experimenter's control. In this paper, we attempt to empirically evaluate the fidelity of the AMT system for use in cognitive behavioral experiments. These types of experiment differ from simple surveys in that they require multiple trials, sustained attention from participants, comprehension of complex instructions, and millisecond accuracy for response recording and stimulus presentation. We replicate a diverse body of tasks from experimental psychology including the Stroop, Switching, Flanker, Simon, Posner Cuing, attentional blink, subliminal priming, and category learning tasks using participants recruited using AMT. While most of replications were qualitatively successful and validated the approach of collecting data anonymously online using a web-browser, others revealed disparity between laboratory results and online results. A number of important lessons were encountered in the process of conducting these replications that should be of value to other researchers.
Conflict of interest statement
Figures
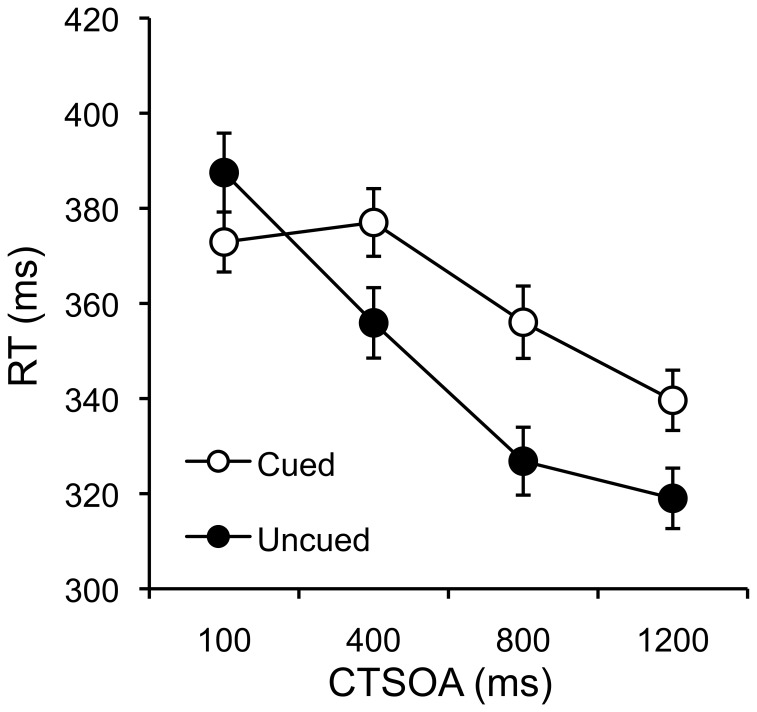
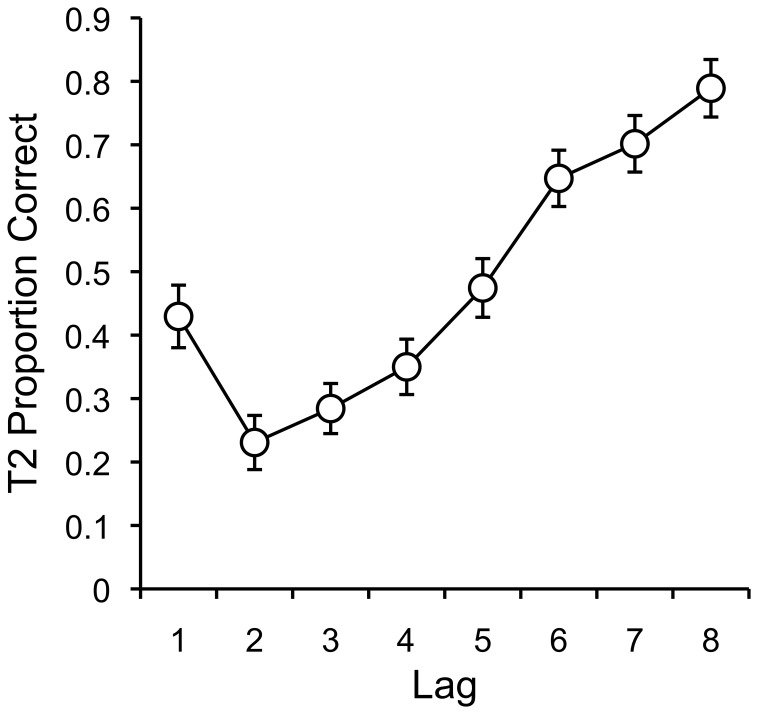
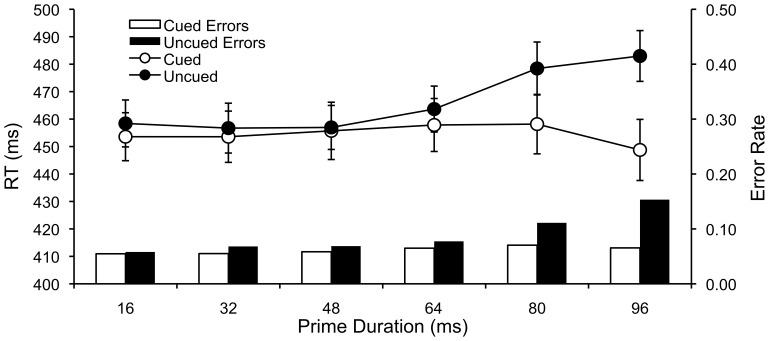
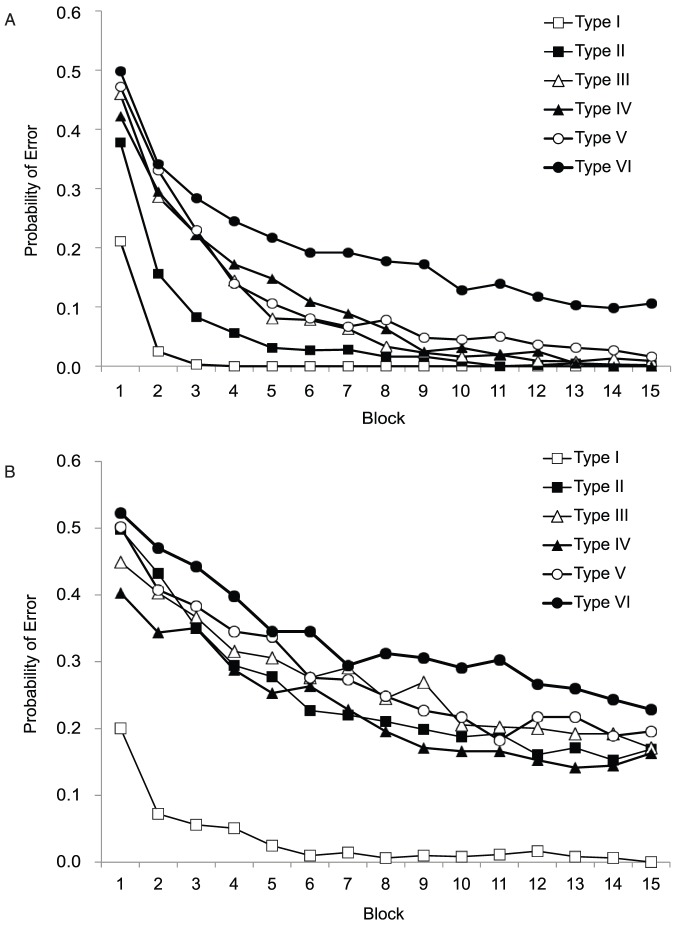
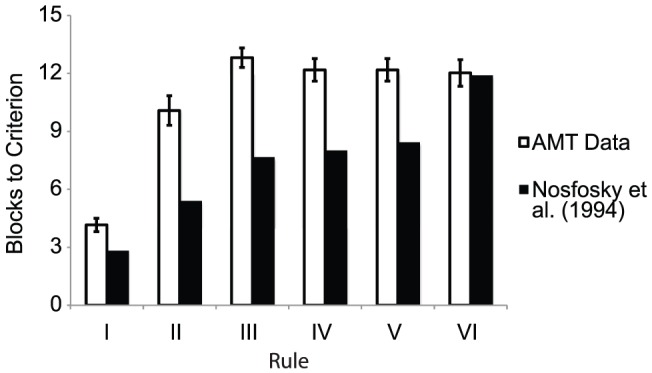
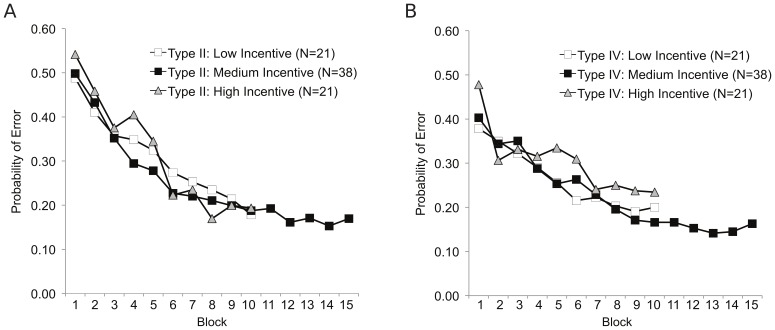
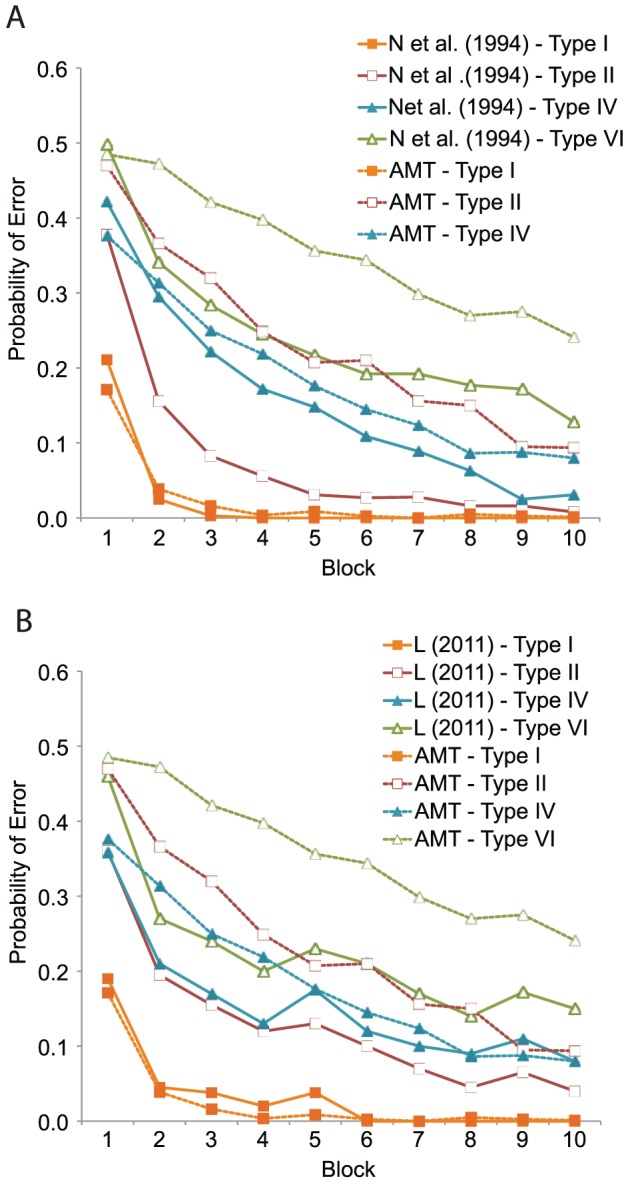
References
-
- Pontin J (2007) Artificial Intelligence, With Help From the Humans. The New York Times. Available: http://www.nytimes.com/2007/03/25/business/yourmoney/25Stream.html?_r=0. Accessed 2012 Nov 6.
-
- Mason W, Suri S (2012) Conducting behavioral research on Amazon's Mechanical Turk. Behav Res Methods 44: 1–23. - PubMed
-
- Gosling SD, Vazire S, Srivastava S, John OP (2004) Should we trust web-based studies? A comparative analysis of six preconceptions about Internet questionnaires. Am Psychol 59: 93–104. - PubMed
-
- Buhrmester M, Kwang T, Gosling SD (2011) Amazon's Mechanical Turk: A new source of inexpensive, yet high-quality, data? Perspect Psychol Sci 6: 3–5. - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
