

Dopamine restores reward prediction errors in old age
- PMID: 23525044
- PMCID: PMC3672991
- DOI: 10.1038/nn.3364
Dopamine restores reward prediction errors in old age
Erratum in
- Nat Neurosci. 2014 Dec;17(12):1840
Abstract
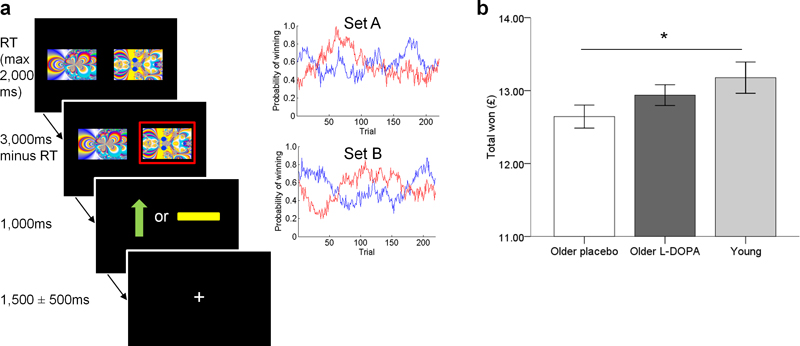
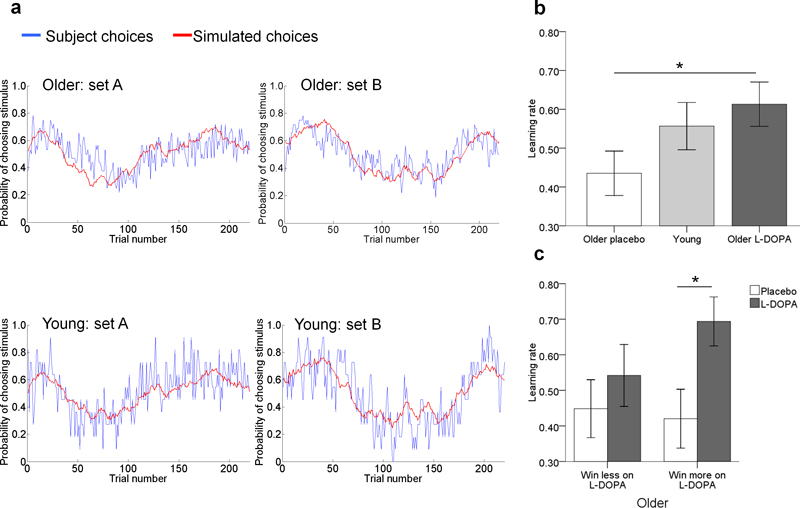
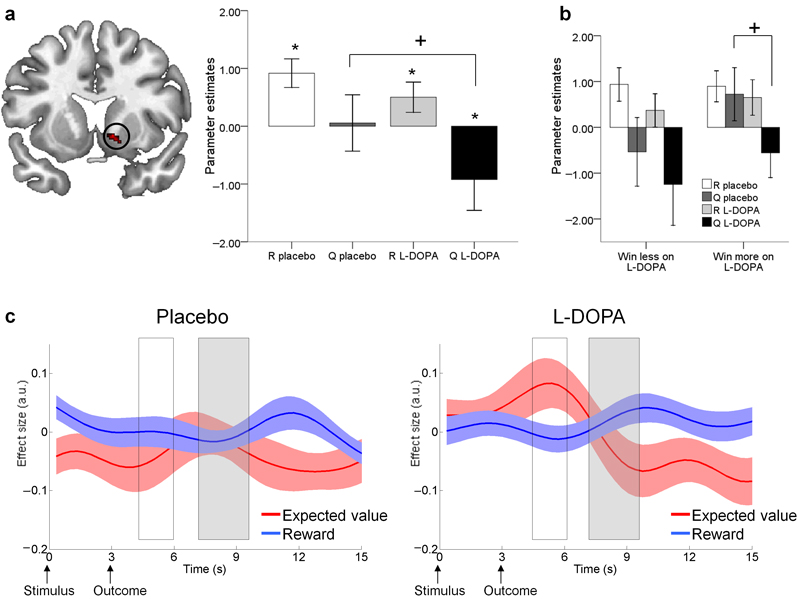
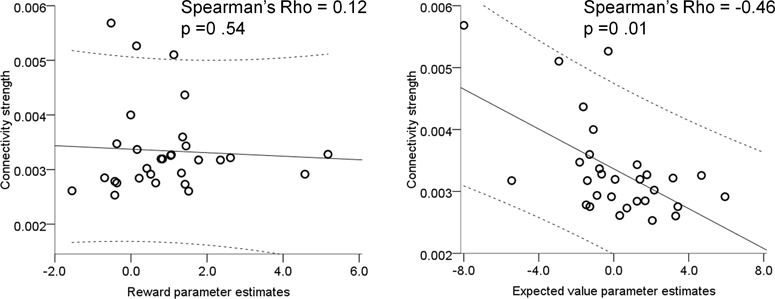
Senescence affects the ability to utilize information about the likelihood of rewards for optimal decision-making. Using functional magnetic resonance imaging in humans, we found that healthy older adults had an abnormal signature of expected value, resulting in an incomplete reward prediction error (RPE) signal in the nucleus accumbens, a brain region that receives rich input projections from substantia nigra/ventral tegmental area (SN/VTA) dopaminergic neurons. Structural connectivity between SN/VTA and striatum, measured by diffusion tensor imaging, was tightly coupled to inter-individual differences in the expression of this expected reward value signal. The dopamine precursor levodopa (L-DOPA) increased the task-based learning rate and task performance in some older adults to the level of young adults. This drug effect was linked to restoration of a canonical neural RPE. Our results identify a neurochemical signature underlying abnormal reward processing in older adults and indicate that this can be modulated by L-DOPA.
Figures
Comment in
-
Dopamine and the cost of aging.Nat Neurosci. 2013 May;16(5):519-21. doi: 10.1038/nn.3385. Nat Neurosci. 2013. PMID: 23619753 No abstract available.
-
Dopamine as the fountain of youth? Restoring decision making ability in older adults.Neurosurgery. 2013 Oct;73(4):N19-20. doi: 10.1227/01.neu.0000435119.56571.18. Neurosurgery. 2013. PMID: 24051717 No abstract available.
References
-
- Mell T, et al. Effect of aging on stimulus-reward association learning. Neuropsychologia. 2005;43:554–563. - PubMed
-
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. - PubMed
-
- Salamone JD, Correa M, Mingote SM, Weber SM. Beyond the reward hypothesis: alternative functions of nucleus accumbens dopamine. Current Opinion in Pharmacology. 2005;5:34–41. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
