

Human Object-Similarity Judgments Reflect and Transcend the Primate-IT Object Representation
- PMID: 23525516
- PMCID: PMC3605517
- DOI: 10.3389/fpsyg.2013.00128
Human Object-Similarity Judgments Reflect and Transcend the Primate-IT Object Representation
Abstract
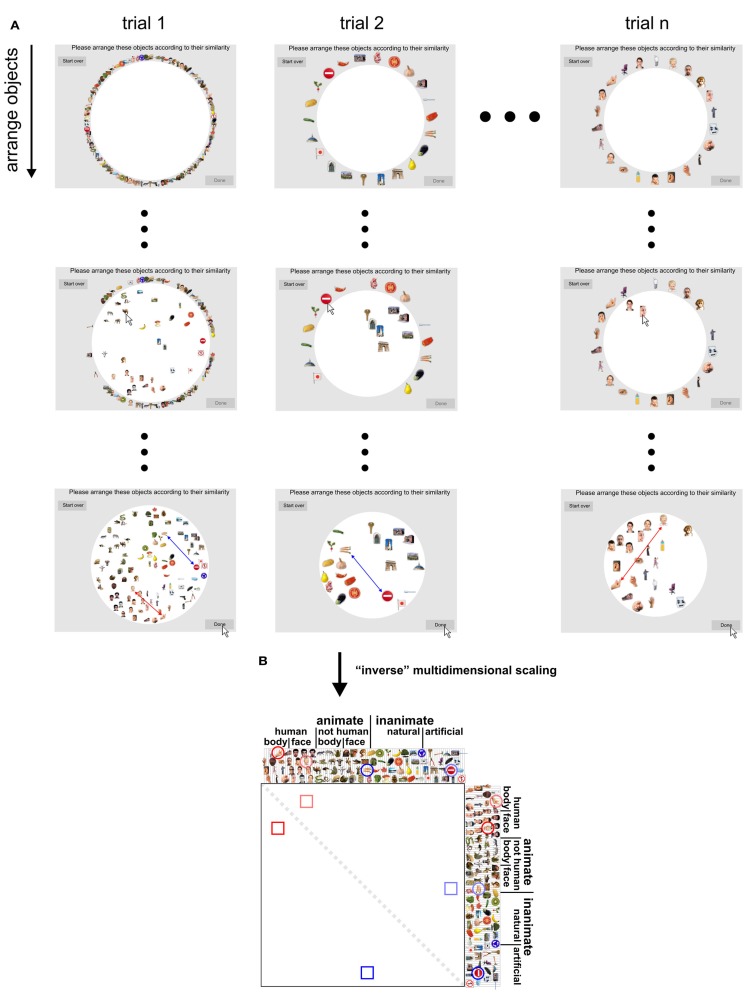
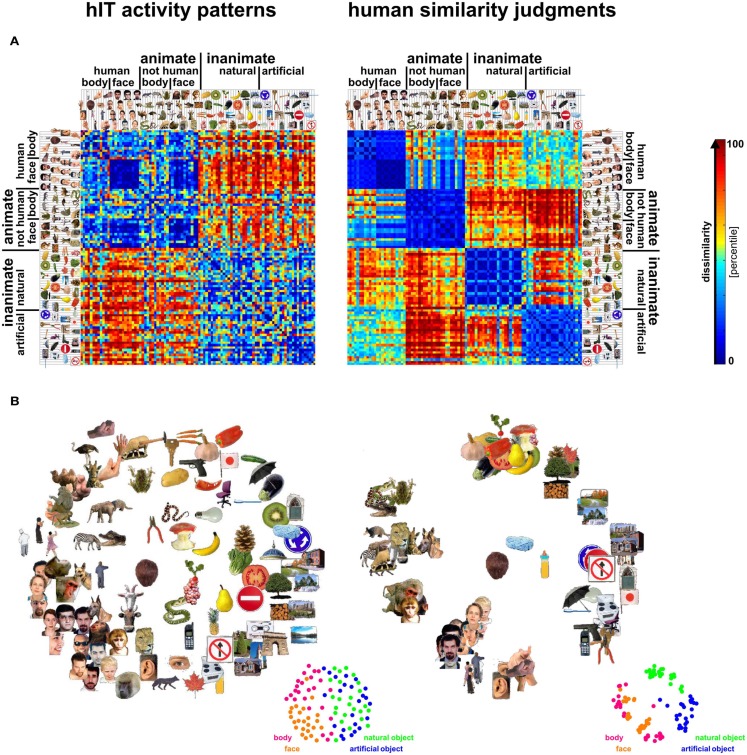
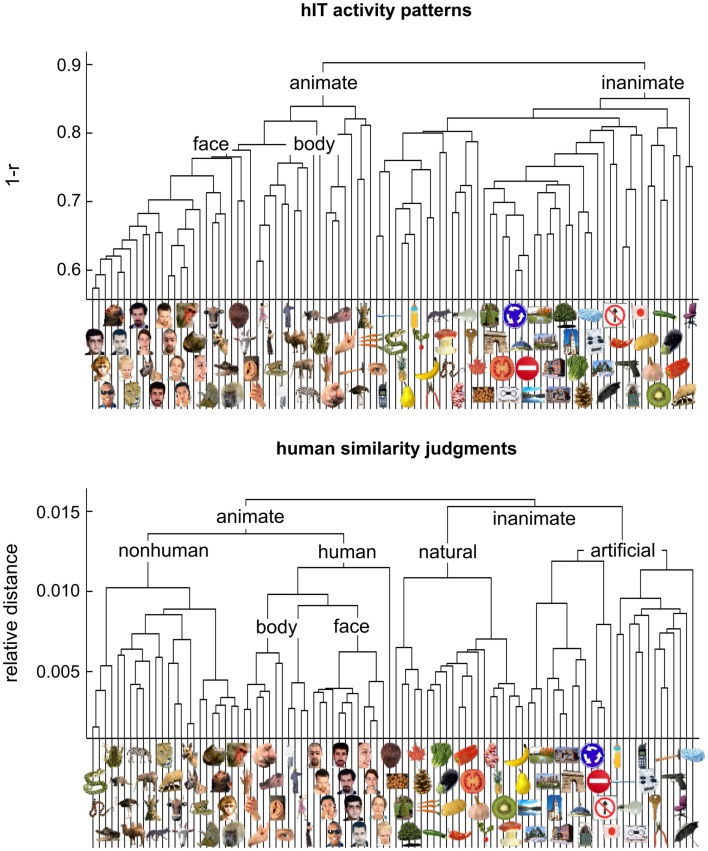
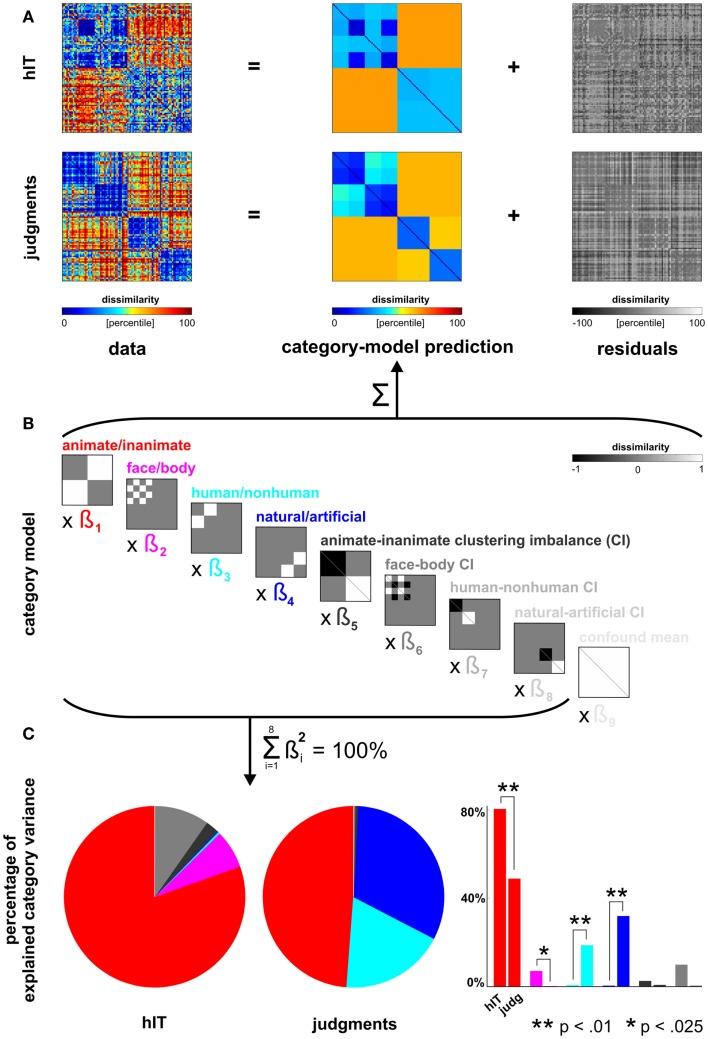
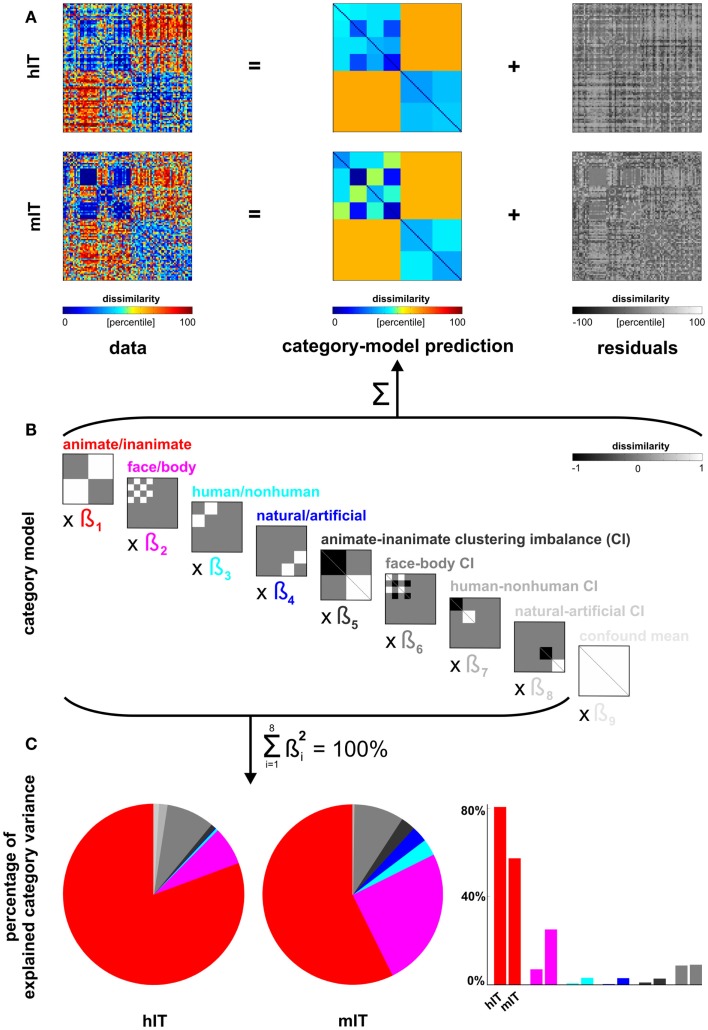
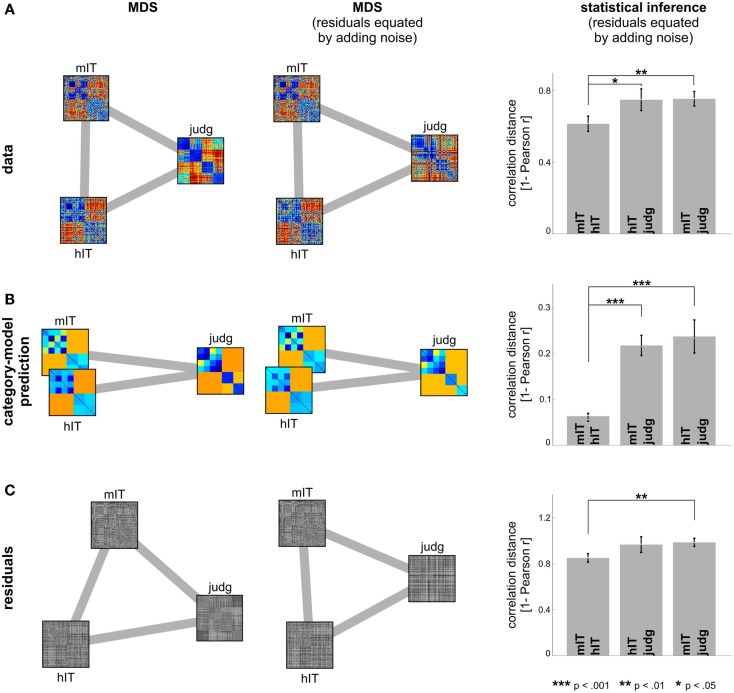
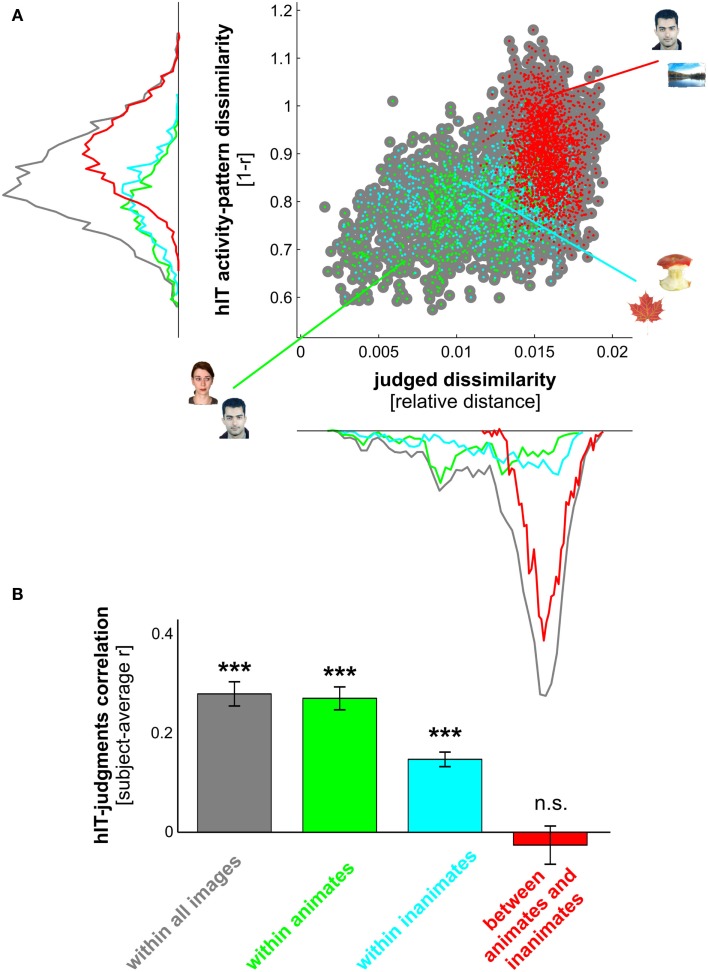
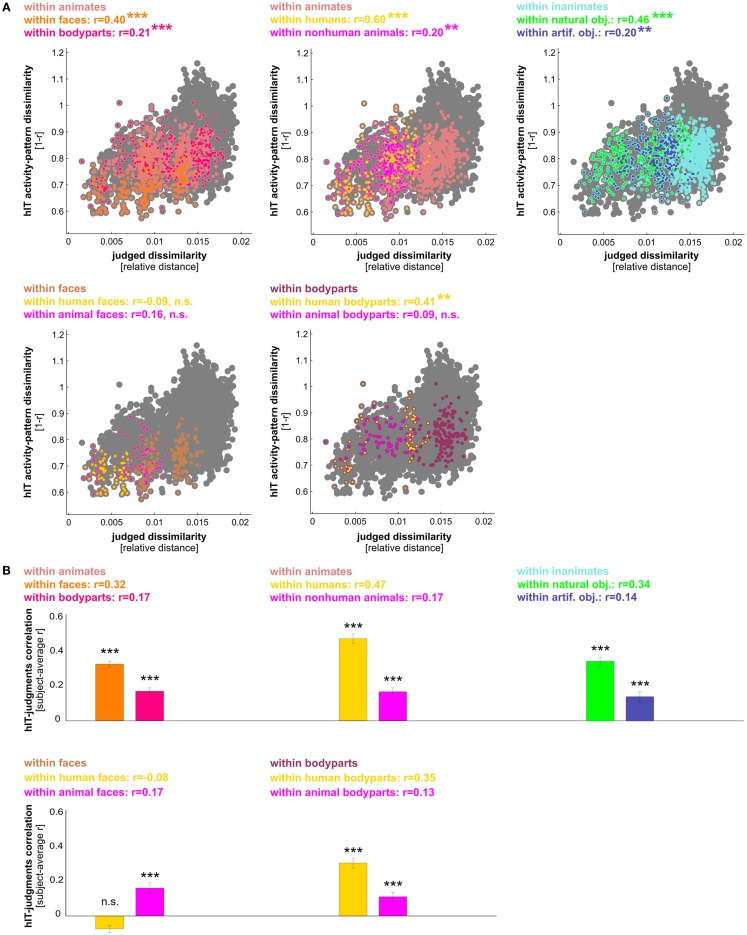
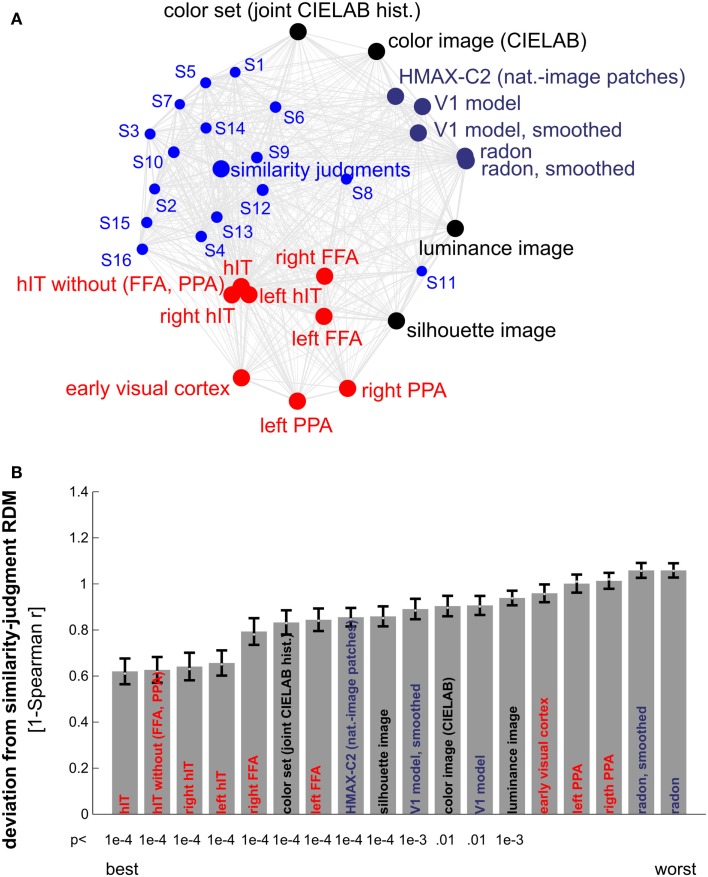
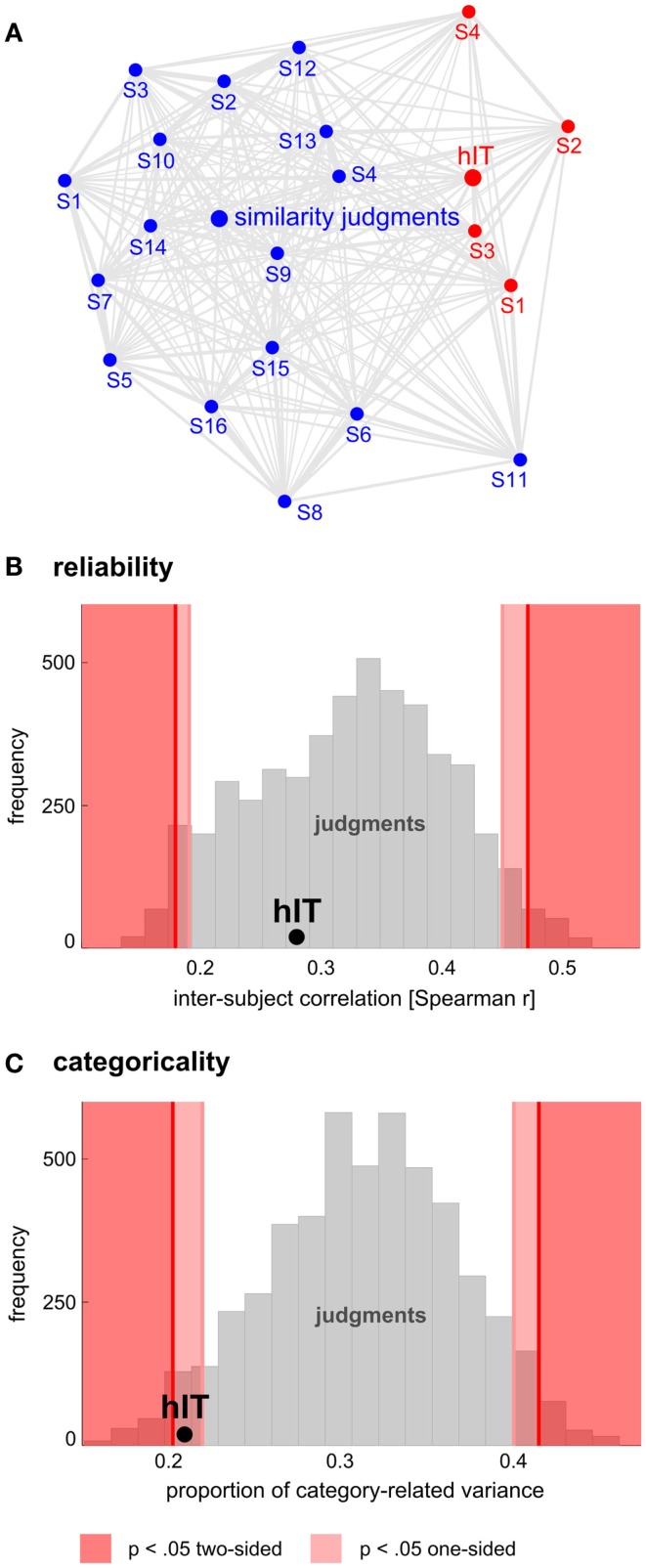
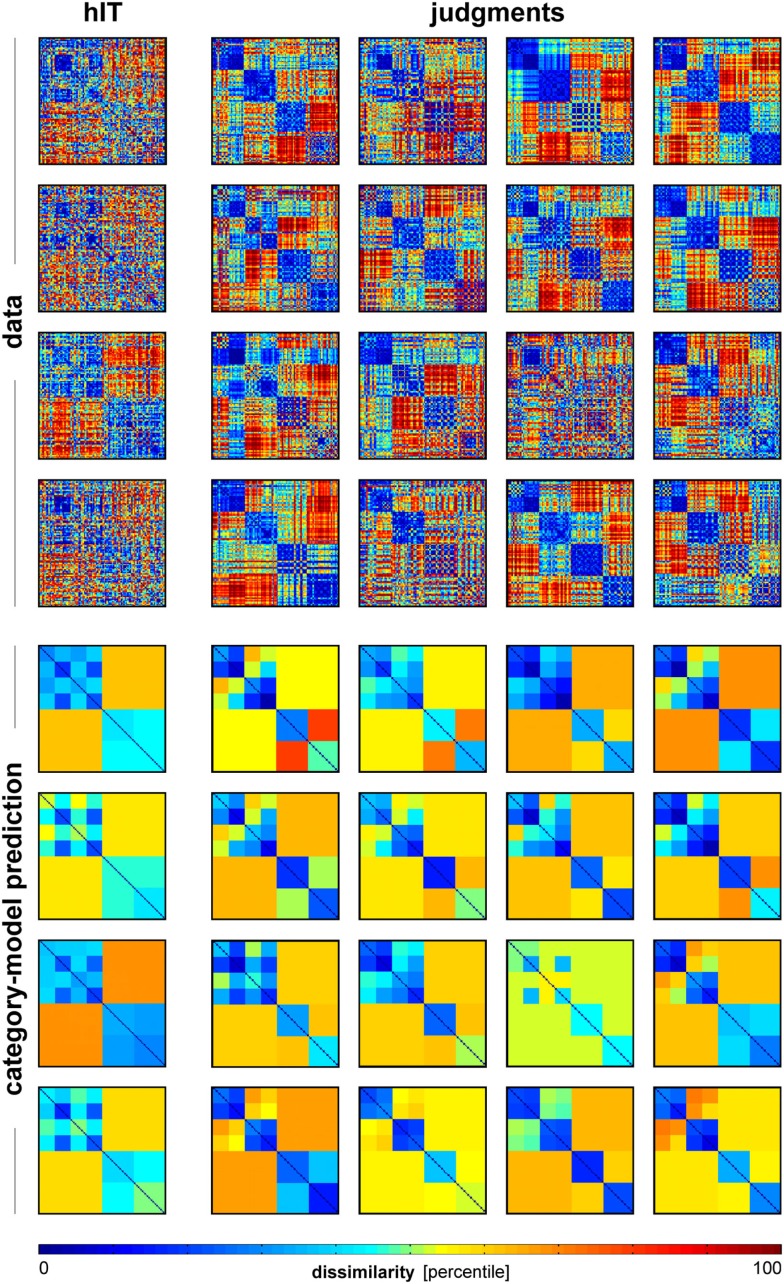
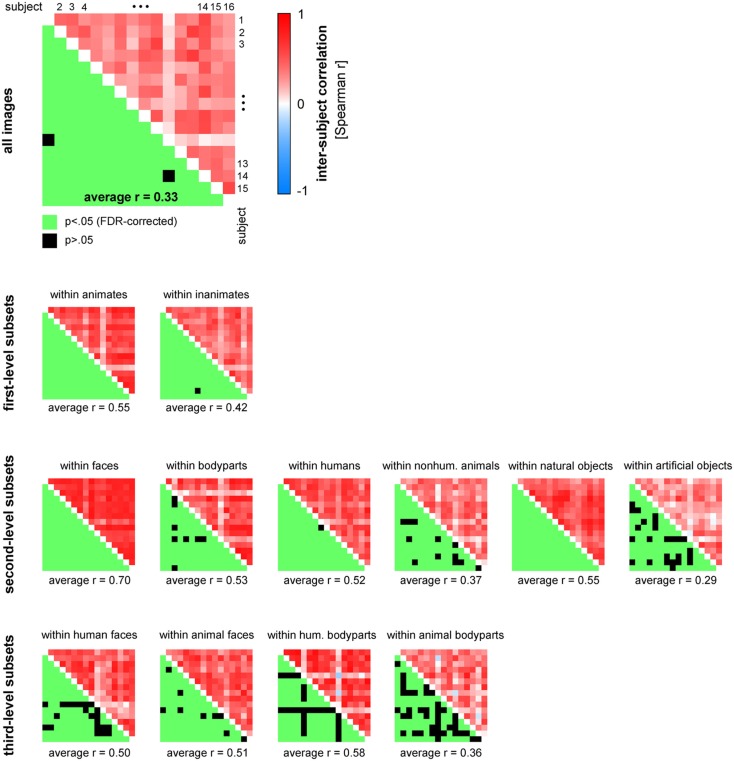
Primate inferior temporal (IT) cortex is thought to contain a high-level representation of objects at the interface between vision and semantics. This suggests that the perceived similarity of real-world objects might be predicted from the IT representation. Here we show that objects that elicit similar activity patterns in human IT (hIT) tend to be judged as similar by humans. The IT representation explained the human judgments better than early visual cortex, other ventral-stream regions, and a range of computational models. Human similarity judgments exhibited category clusters that reflected several categorical divisions that are prevalent in the IT representation of both human and monkey, including the animate/inanimate and the face/body division. Human judgments also reflected the within-category representation of IT. However, the judgments transcended the IT representation in that they introduced additional categorical divisions. In particular, human judgments emphasized human-related additional divisions between human and non-human animals and between man-made and natural objects. hIT was more similar to monkey IT than to human judgments. One interpretation is that IT has evolved visual-feature detectors that distinguish between animates and inanimates and between faces and bodies because these divisions are fundamental to survival and reproduction for all primate species, and that other brain systems serve to more flexibly introduce species-dependent and evolutionarily more recent divisions.
Keywords: fMRI; human; neuronal representation; object perception; primate; representational similarity analysis; vision.
Figures

References
-
- Carnap R. (1928/1967). The Logical Structure of the World. Berkeley: University of California Press
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources