

Multifeatural shape processing in rats engaged in invariant visual object recognition
- PMID: 23554476
- PMCID: PMC6618908
- DOI: 10.1523/JNEUROSCI.3629-12.2013
Multifeatural shape processing in rats engaged in invariant visual object recognition
Abstract
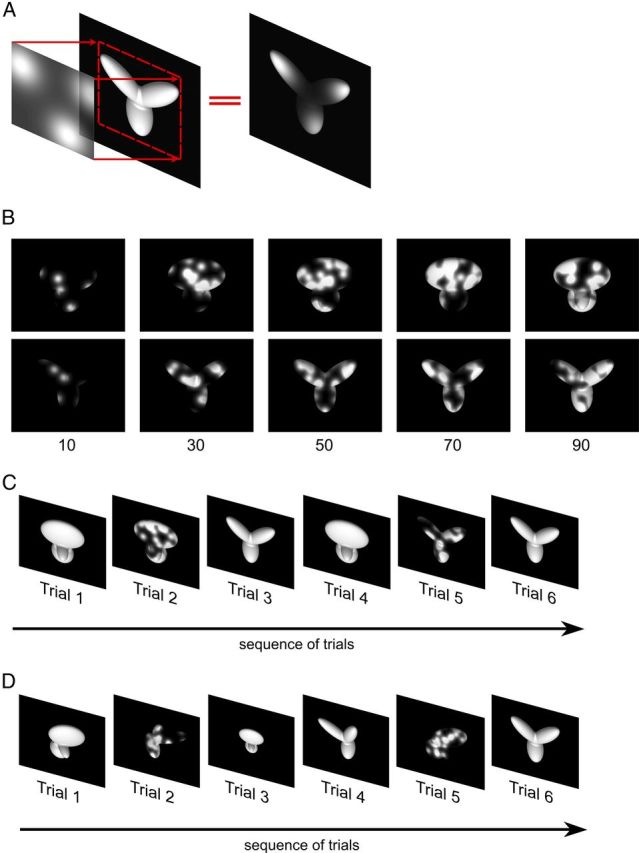
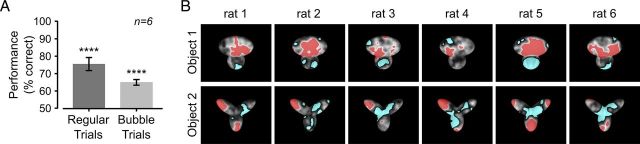
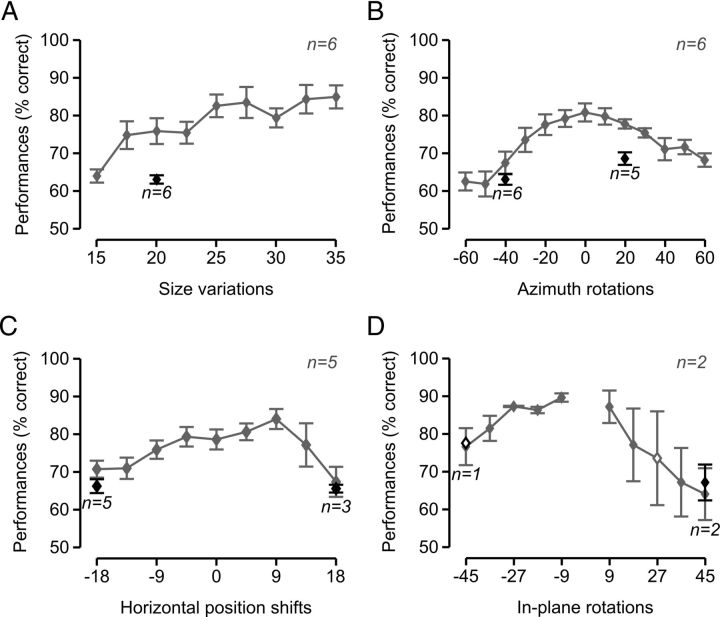
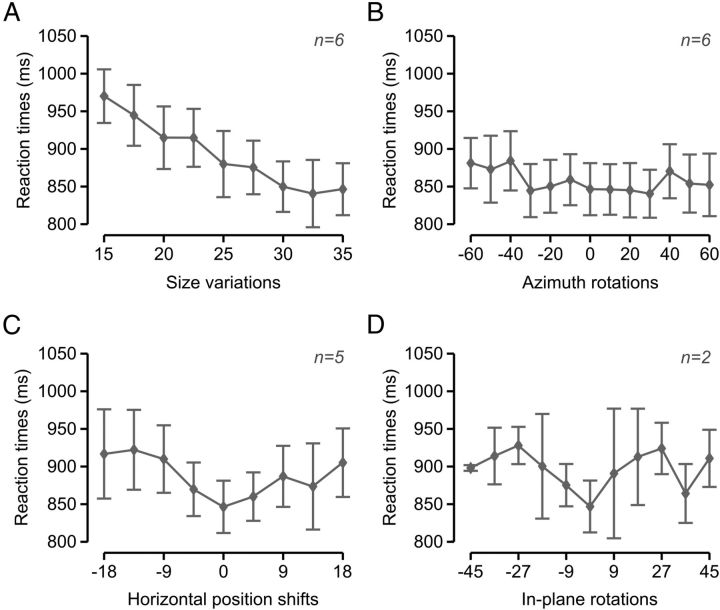
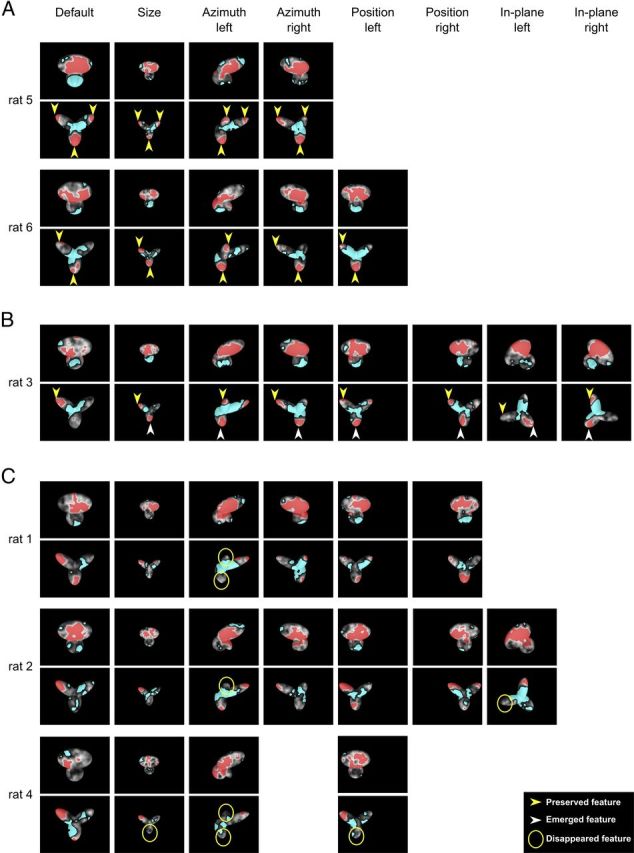
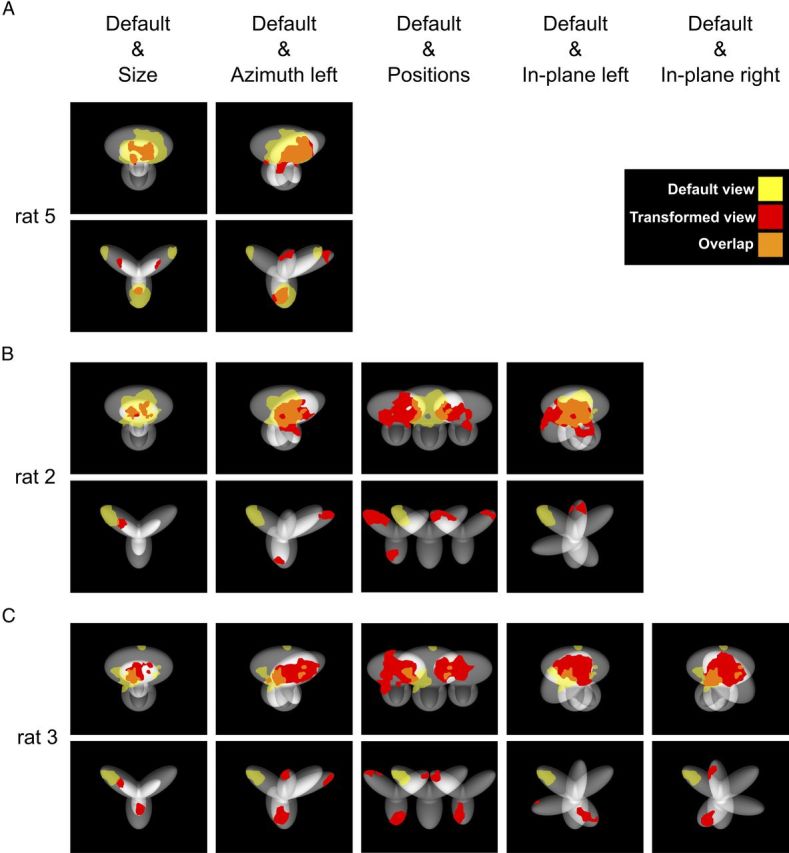
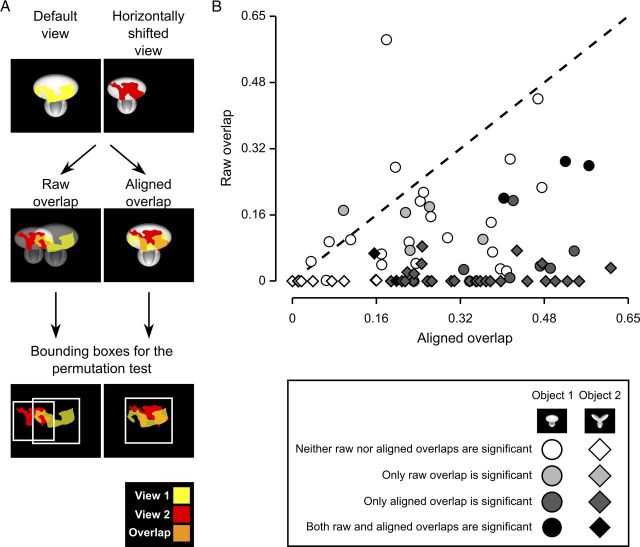
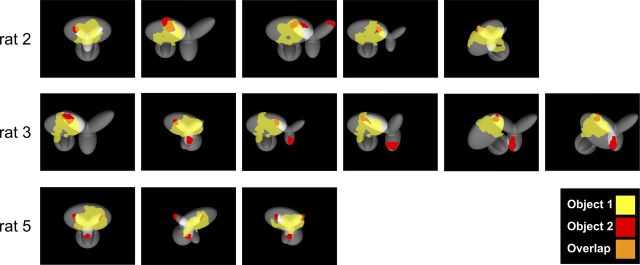
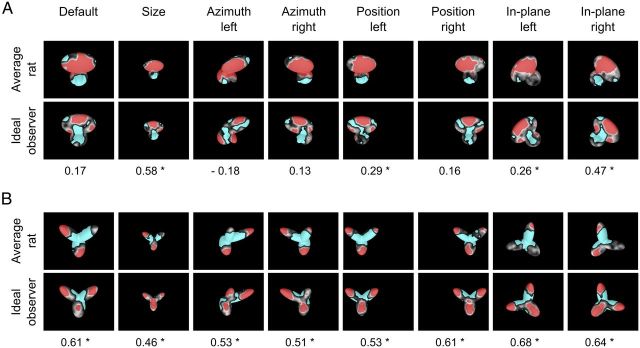
The ability to recognize objects despite substantial variation in their appearance (e.g., because of position or size changes) represents such a formidable computational feat that it is widely assumed to be unique to primates. Such an assumption has restricted the investigation of its neuronal underpinnings to primate studies, which allow only a limited range of experimental approaches. In recent years, the increasingly powerful array of optical and molecular tools that has become available in rodents has spurred a renewed interest for rodent models of visual functions. However, evidence of primate-like visual object processing in rodents is still very limited and controversial. Here we show that rats are capable of an advanced recognition strategy, which relies on extracting the most informative object features across the variety of viewing conditions the animals may face. Rat visual strategy was uncovered by applying an image masking method that revealed the features used by the animals to discriminate two objects across a range of sizes, positions, in-depth, and in-plane rotations. Noticeably, rat recognition relied on a combination of multiple features that were mostly preserved across the transformations the objects underwent, and largely overlapped with the features that a simulated ideal observer deemed optimal to accomplish the discrimination task. These results indicate that rats are able to process and efficiently use shape information, in a way that is largely tolerant to variation in object appearance. This suggests that their visual system may serve as a powerful model to study the neuronal substrates of object recognition.
Figures

References
-
- Chelazzi L, Rossi F, Tempia F, Ghirardi M, Strata P. Saccadic eye movements and gaze holding in the head-restrained pigmented rat. Eur J Neurosci. 1989;1:639–646. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources