

Synergies between intrinsic and synaptic plasticity based on information theoretic learning
- PMID: 23671642
- PMCID: PMC3650036
- DOI: 10.1371/journal.pone.0062894
Synergies between intrinsic and synaptic plasticity based on information theoretic learning
Abstract
In experimental and theoretical neuroscience, synaptic plasticity has dominated the area of neural plasticity for a very long time. Recently, neuronal intrinsic plasticity (IP) has become a hot topic in this area. IP is sometimes thought to be an information-maximization mechanism. However, it is still unclear how IP affects the performance of artificial neural networks in supervised learning applications. From an information-theoretical perspective, the error-entropy minimization (MEE) algorithm has newly been proposed as an efficient training method. In this study, we propose a synergistic learning algorithm combining the MEE algorithm as the synaptic plasticity rule and an information-maximization algorithm as the intrinsic plasticity rule. We consider both feedforward and recurrent neural networks and study the interactions between intrinsic and synaptic plasticity. Simulations indicate that the intrinsic plasticity rule can improve the performance of artificial neural networks trained by the MEE algorithm.
Conflict of interest statement
Figures







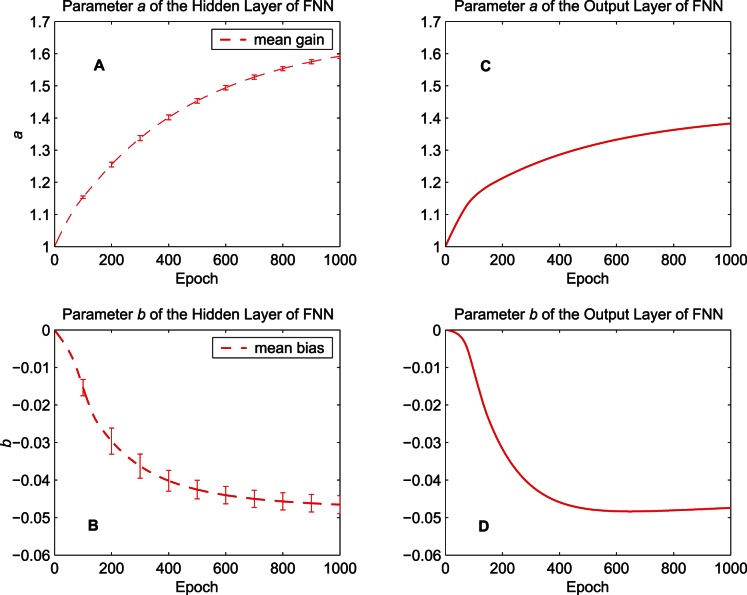
 of the five hidden neurons. (B) Mean of the bias parameter
of the five hidden neurons. (B) Mean of the bias parameter  of the five hidden neurons. (C) The gain parameter
of the five hidden neurons. (C) The gain parameter  of the output neuron. (D) The bias parameter
of the output neuron. (D) The bias parameter  of the output neuron.
of the output neuron.
 ,
,  ,
,  , and
, and  (no IP) are used for comparison. Learning curves of the quadratic information potential: (A) 300 epochs. (B) 1000 epochs. Learning curves of the mean square error: (C) 300 epochs. (D) 1000 epochs.
(no IP) are used for comparison. Learning curves of the quadratic information potential: (A) 300 epochs. (B) 1000 epochs. Learning curves of the mean square error: (C) 300 epochs. (D) 1000 epochs.




 . (B) The bias parameter
. (B) The bias parameter  .
.
 ,
,  ,
,  , and
, and  (no IP) are used for comparison. Learning curves of the quadratic information potential: (A) 300 epochs. (B) 1000 epochs. Learning curves of the mean square error: (C) 300 epochs. (D) 1000 epochs.
(no IP) are used for comparison. Learning curves of the quadratic information potential: (A) 300 epochs. (B) 1000 epochs. Learning curves of the mean square error: (C) 300 epochs. (D) 1000 epochs.
References
-
- Principe JC (2010) Information theoretic learning: Renyi’s entropy and kernel perspectives. New York, Dordrecht, Heidelberg, London: Springer.
-
- Desai NS, Rutherford LC, Turrigiano GG (1999) Plasticity in the intrinsic excitability of cortical pyramidal neurons. Nat Neurosci 2: 515–520. - PubMed
-
- Zhang W, Linden DJ (2003) The other side of the engram: Experience-driven changes in neuronal intrinsic excitability. Nat Rev Neurosci 4: 885–900. - PubMed
-
- Daoudal G, Debanne D (2003) Long-term plasticity of intrinsic excitability: Learning rules and mechanisms. Learn Mem 10: 456–465. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
