

Learning where to look for a hidden target
- PMID: 23754404
- PMCID: PMC3690606
- DOI: 10.1073/pnas.1301216110
Learning where to look for a hidden target
Abstract
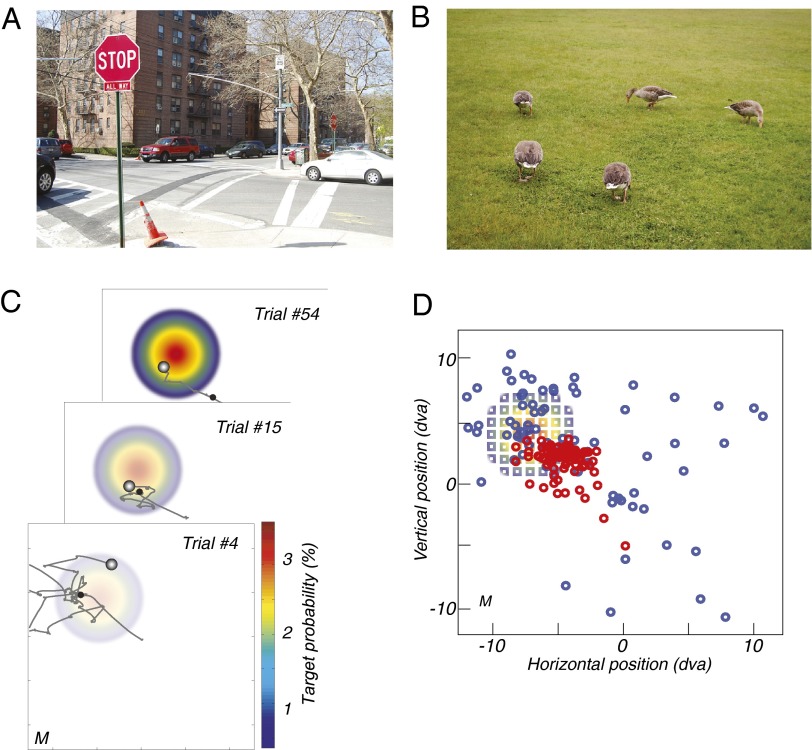
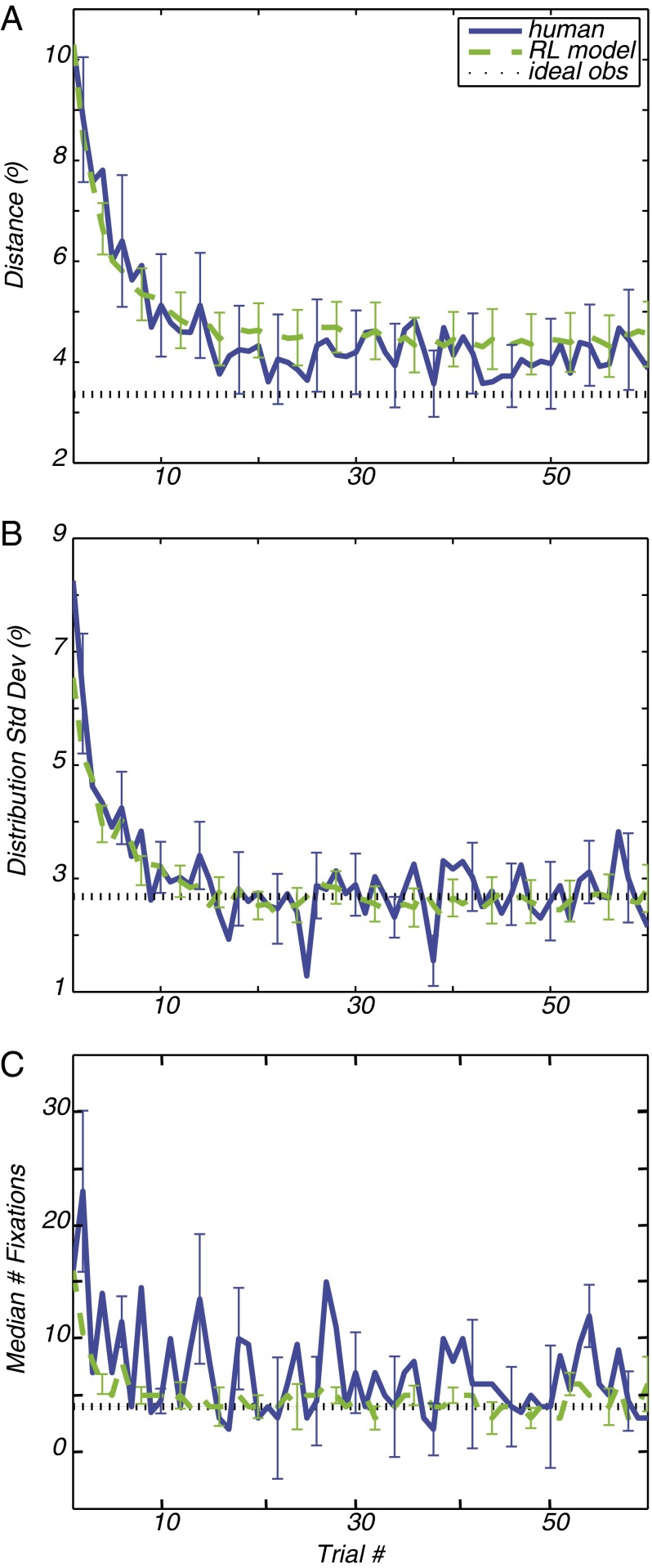
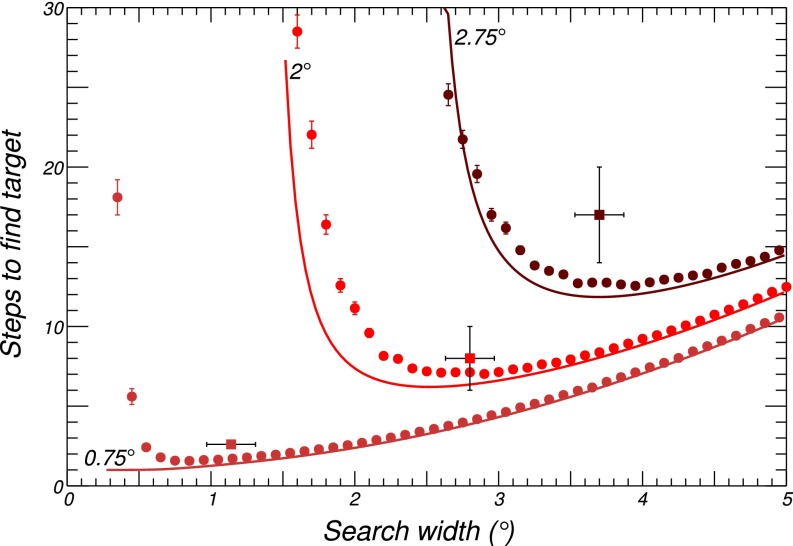
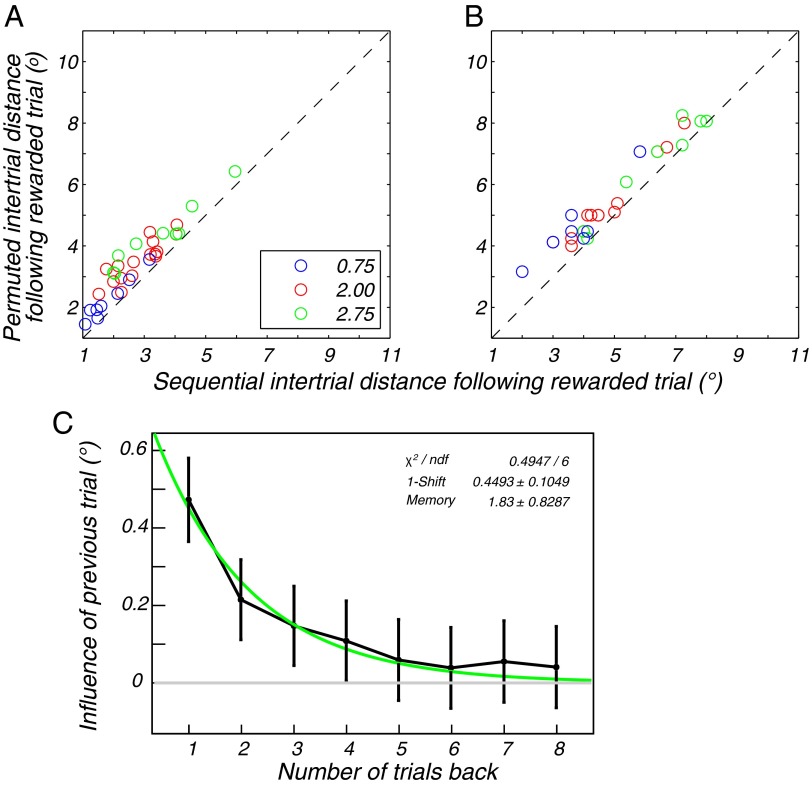
Survival depends on successfully foraging for food, for which evolution has selected diverse behaviors in different species. Humans forage not only for food, but also for information. We decide where to look over 170,000 times per day, approximately three times per wakeful second. The frequency of these saccadic eye movements belies the complexity underlying each individual choice. Experience factors into the choice of where to look and can be invoked to rapidly redirect gaze in a context and task-appropriate manner. However, remarkably little is known about how individuals learn to direct their gaze given the current context and task. We designed a task in which participants search a novel scene for a target whose location was drawn stochastically on each trial from a fixed prior distribution. The target was invisible on a blank screen, and the participants were rewarded when they fixated the hidden target location. In just a few trials, participants rapidly found the hidden targets by looking near previously rewarded locations and avoiding previously unrewarded locations. Learning trajectories were well characterized by a simple reinforcement-learning (RL) model that maintained and continually updated a reward map of locations. The RL model made further predictions concerning sensitivity to recent experience that were confirmed by the data. The asymptotic performance of both the participants and the RL model approached optimal performance characterized by an ideal-observer theory. These two complementary levels of explanation show how experience in a novel environment drives visual search in humans and may extend to other forms of search such as animal foraging.
Keywords: ideal observer; oculomotor; reinforcement learning; saccades.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Potter MC. Meaning in visual search. Science. 1975;187(4180):965–966. - PubMed
-
- Itti L, Koch C. A saliency-based search mechanism for overt and covert shifts of visual attention. Vision Res. 2000;40(10-12):1489–1506. - PubMed
-
- Oliva A, Torralba A. Building the gist of a scene: The role of global image features in recognition. Prog Brain Res. 2006;155:23–36. - PubMed
-
- Torralba A, Oliva A, Castelhano MS, Henderson JM. Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychol Rev. 2006;113(4):766–786. - PubMed
-
- Neider MB, Zelinsky GJ. Scene context guides eye movements during visual search. Vision Res. 2006;46(5):614–621. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
