

Navigating complex decision spaces: Problems and paradigms in sequential choice
- PMID: 23834192
- PMCID: PMC4309984
- DOI: 10.1037/a0033455
Navigating complex decision spaces: Problems and paradigms in sequential choice
Abstract
To behave adaptively, we must learn from the consequences of our actions. Doing so is difficult when the consequences of an action follow a delay. This introduces the problem of temporal credit assignment. When feedback follows a sequence of decisions, how should the individual assign credit to the intermediate actions that comprise the sequence? Research in reinforcement learning provides 2 general solutions to this problem: model-free reinforcement learning and model-based reinforcement learning. In this review, we examine connections between stimulus-response and cognitive learning theories, habitual and goal-directed control, and model-free and model-based reinforcement learning. We then consider a range of problems related to temporal credit assignment. These include second-order conditioning and secondary reinforcers, latent learning and detour behavior, partially observable Markov decision processes, actions with distributed outcomes, and hierarchical learning. We ask whether humans and animals, when faced with these problems, behave in a manner consistent with reinforcement learning techniques. Throughout, we seek to identify neural substrates of model-free and model-based reinforcement learning. The former class of techniques is understood in terms of the neurotransmitter dopamine and its effects in the basal ganglia. The latter is understood in terms of a distributed network of regions including the prefrontal cortex, medial temporal lobes, cerebellum, and basal ganglia. Not only do reinforcement learning techniques have a natural interpretation in terms of human and animal behavior but they also provide a useful framework for understanding neural reward valuation and action selection.
Figures
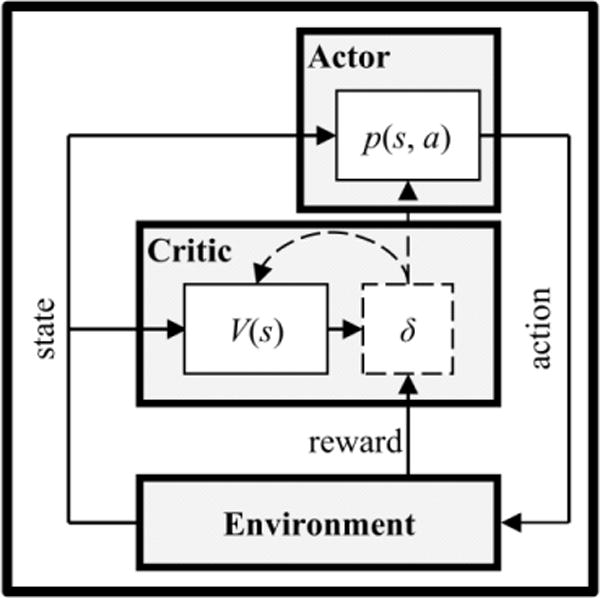





References
-
- Abler B, Walter H, Erk S, Kammerer H, Spitzer M. Prediction error as a linear function of reward probability is coded in human nucleus accumbens. Neuroimage. 2006;31:790–795. - PubMed
-
- Adams CD, Dickinson A. Instrumental responding following reinforcer devaluation. Quarterly Journal of Experimental Psychology. 1981;33B:109–121.
-
- Anderson JR. How can the human mind occur in the physical universe? New York, NY: Oxford University Press; 2007.
-
- Anderson JR, Albert MV, Fincham JM. Tracing problem solving in real time: fMRI analysis of the subject-paced tower of Hanoi. Journal of Cognitive Neuroscience. 2005;17:1261–1274. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
