

Scaling-laws of human broadcast communication enable distinction between human, corporate and robot Twitter users
- PMID: 23843945
- PMCID: PMC3701018
- DOI: 10.1371/journal.pone.0065774
Scaling-laws of human broadcast communication enable distinction between human, corporate and robot Twitter users
Abstract
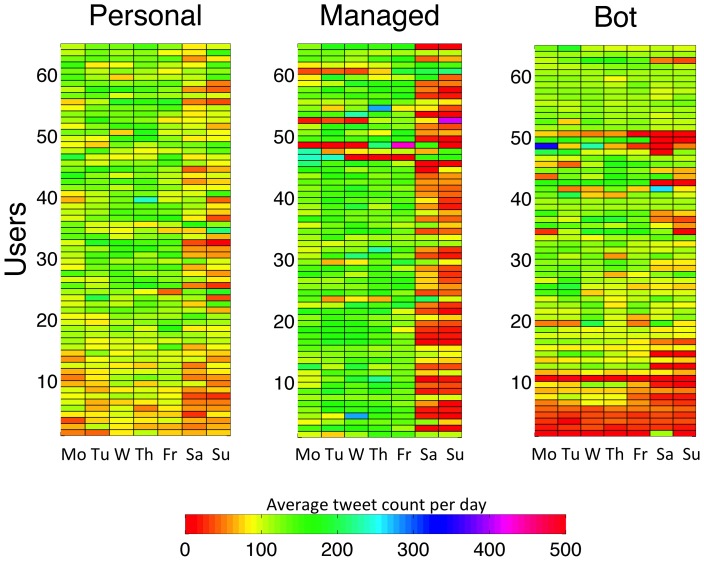
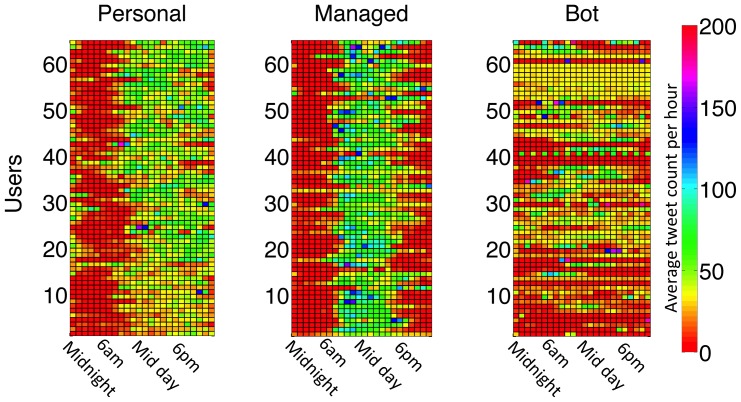
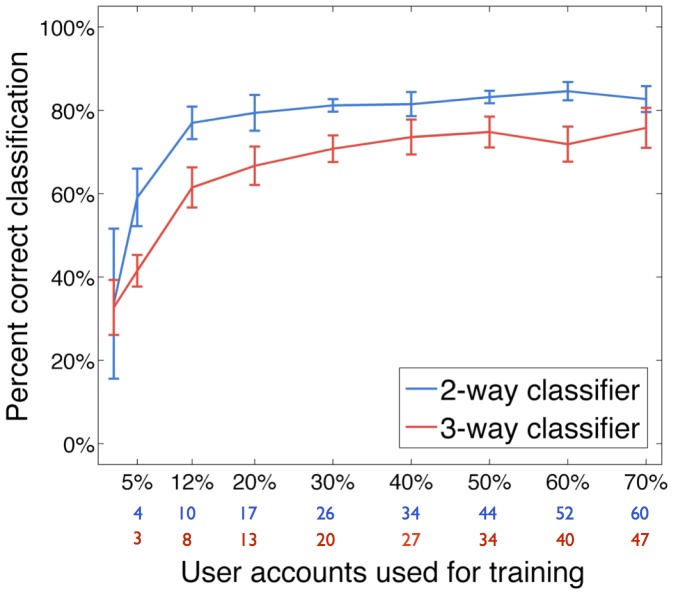
Human behaviour is highly individual by nature, yet statistical structures are emerging which seem to govern the actions of human beings collectively. Here we search for universal statistical laws dictating the timing of human actions in communication decisions. We focus on the distribution of the time interval between messages in human broadcast communication, as documented in Twitter, and study a collection of over 160,000 tweets for three user categories: personal (controlled by one person), managed (typically PR agency controlled) and bot-controlled (automated system). To test our hypothesis, we investigate whether it is possible to differentiate between user types based on tweet timing behaviour, independently of the content in messages. For this purpose, we developed a system to process a large amount of tweets for reality mining and implemented two simple probabilistic inference algorithms: 1. a naive Bayes classifier, which distinguishes between two and three account categories with classification performance of 84.6% and 75.8%, respectively and 2. a prediction algorithm to estimate the time of a user's next tweet with an R(2) ≈ 0.7. Our results show that we can reliably distinguish between the three user categories as well as predict the distribution of a user's inter-message time with reasonable accuracy. More importantly, we identify a characteristic power-law decrease in the tail of inter-message time distribution by human users which is different from that obtained for managed and automated accounts. This result is evidence of a universal law that permeates the timing of human decisions in broadcast communication and extends the findings of several previous studies of peer-to-peer communication.
Conflict of interest statement
Figures
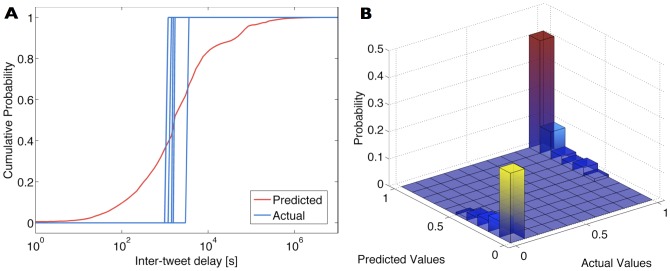
 accounts is shown in red, while the step functions computed for 5 tweets of the left-out account are shown in blue. The CDF corresponds to the probability that a tweet will be posted
accounts is shown in red, while the step functions computed for 5 tweets of the left-out account are shown in blue. The CDF corresponds to the probability that a tweet will be posted  seconds after the previous tweet (predicted probability), while the step functions correspond to the observed probability for the occurrence of tweets (observed or actual probability). A perfect prediction for a specific tweet would mean that the CDF coincides exactly with the step function for that tweet. (b) In this histogram, the axis on the left of the plane corresponds to the value of the CDF obtained for the inter-tweet delay (predicted value), while the axis on the right corresponds to the value of the step function obtained for the same delay (actual value, which is either 0 or 1). A perfect predictive model would have all data points grouped in bins
seconds after the previous tweet (predicted probability), while the step functions correspond to the observed probability for the occurrence of tweets (observed or actual probability). A perfect prediction for a specific tweet would mean that the CDF coincides exactly with the step function for that tweet. (b) In this histogram, the axis on the left of the plane corresponds to the value of the CDF obtained for the inter-tweet delay (predicted value), while the axis on the right corresponds to the value of the step function obtained for the same delay (actual value, which is either 0 or 1). A perfect predictive model would have all data points grouped in bins  and
and  , indicating that the CDF models the step functions exactly and thus all predicted and actual values coincide. The fact that these two bins have much higher probabilities than all others in the histogram illustrates the model's accuracy.
, indicating that the CDF models the step functions exactly and thus all predicted and actual values coincide. The fact that these two bins have much higher probabilities than all others in the histogram illustrates the model's accuracy.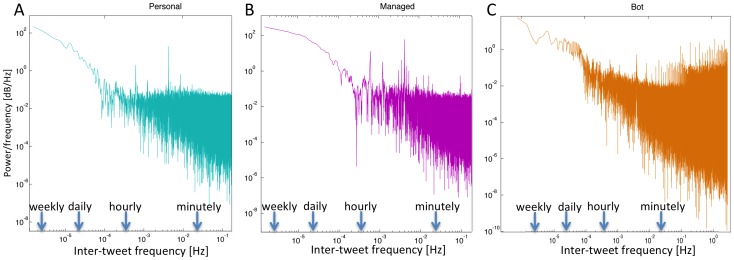
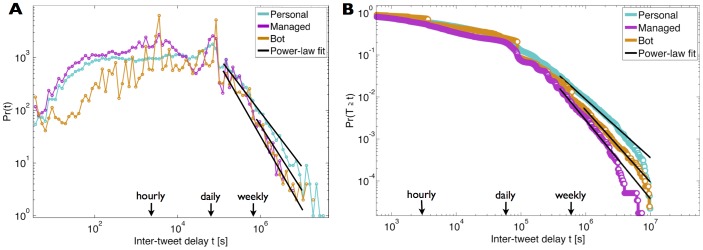
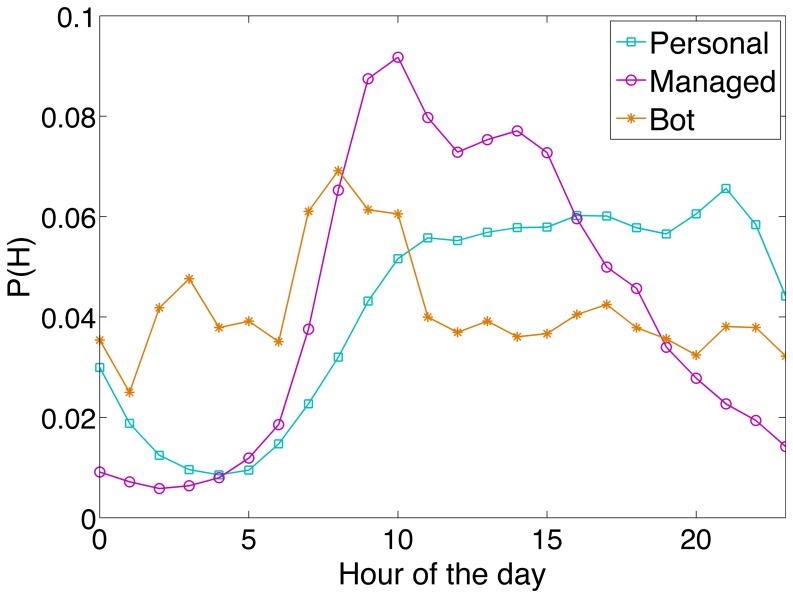
 and
and  . The power-laws fitted to the tails of the distributions have an exponent
. The power-laws fitted to the tails of the distributions have an exponent  for personal accounts,
for personal accounts,  for managed accounts, and
for managed accounts, and  for bot-controlled accounts. (b) The complementary cumulative distribution function (CCDF) for the inter-tweet delay in each class is shown along with the power-law distribution fitted to the tail. The full statistics of the power-law fits are presented in Table 2.
for bot-controlled accounts. (b) The complementary cumulative distribution function (CCDF) for the inter-tweet delay in each class is shown along with the power-law distribution fitted to the tail. The full statistics of the power-law fits are presented in Table 2.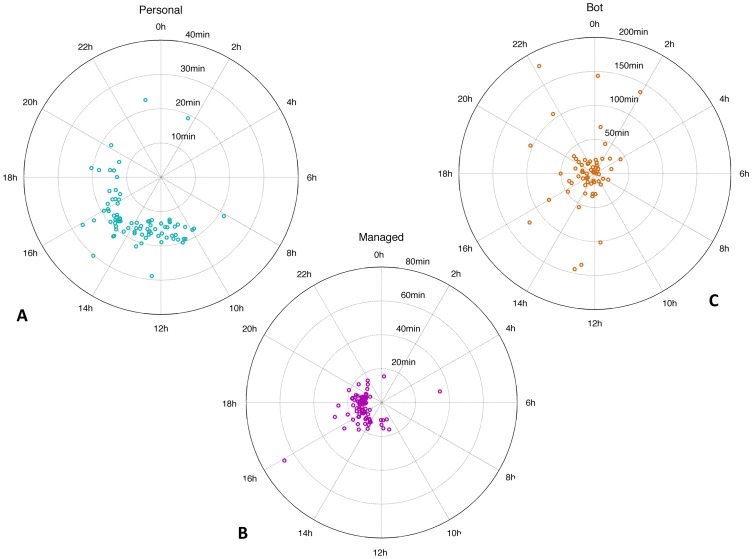
Similar articles
-
Examining Tweet Content and Engagement of Canadian Public Health Agencies and Decision Makers During COVID-19: Mixed Methods Analysis.J Med Internet Res. 2021 Mar 11;23(3):e24883. doi: 10.2196/24883. J Med Internet Res. 2021. PMID: 33651705 Free PMC article.
-
Applying Multiple Data Collection Tools to Quantify Human Papillomavirus Vaccine Communication on Twitter.J Med Internet Res. 2016 Dec 5;18(12):e318. doi: 10.2196/jmir.6670. J Med Internet Res. 2016. PMID: 27919863 Free PMC article.
-
Classification of Twitter Users Who Tweet About E-Cigarettes.JMIR Public Health Surveill. 2017 Sep 26;3(3):e63. doi: 10.2196/publichealth.8060. JMIR Public Health Surveill. 2017. PMID: 28951381 Free PMC article.
-
Decoding twitter: Surveillance and trends for cardiac arrest and resuscitation communication.Resuscitation. 2013 Feb;84(2):206-12. doi: 10.1016/j.resuscitation.2012.10.017. Epub 2012 Oct 27. Resuscitation. 2013. PMID: 23108239 Free PMC article.
-
What are health-related users tweeting? A qualitative content analysis of health-related users and their messages on twitter.J Med Internet Res. 2014 Oct 15;16(10):e237. doi: 10.2196/jmir.3765. J Med Internet Res. 2014. PMID: 25591063 Free PMC article.
Cited by
-
Public Response to a Social Media Tobacco Prevention Campaign: Content Analysis.JMIR Public Health Surveill. 2020 Dec 7;6(4):e20649. doi: 10.2196/20649. JMIR Public Health Surveill. 2020. PMID: 33284120 Free PMC article.
-
Diffusion Dynamics of Energy Saving Practices in Large Heterogeneous Online Networks.PLoS One. 2016 Oct 13;11(10):e0164476. doi: 10.1371/journal.pone.0164476. eCollection 2016. PLoS One. 2016. PMID: 27736912 Free PMC article.
-
Towards Automatic Bot Detection in Twitter for Health-related Tasks.AMIA Jt Summits Transl Sci Proc. 2020 May 30;2020:136-141. eCollection 2020. AMIA Jt Summits Transl Sci Proc. 2020. PMID: 32477632 Free PMC article.
-
A Software Tool Aimed at Automating the Generation, Distribution, and Assessment of Social Media Messages for Health Promotion and Education Research.JMIR Public Health Surveill. 2019 May 7;5(2):e11263. doi: 10.2196/11263. JMIR Public Health Surveill. 2019. PMID: 31066708 Free PMC article.
-
Trial Promoter: A Web-Based Tool for Boosting the Promotion of Clinical Research Through Social Media.J Med Internet Res. 2016 Jun 29;18(6):e144. doi: 10.2196/jmir.4726. J Med Internet Res. 2016. PMID: 27357424 Free PMC article.
References
-
- Paul MJ, Dredze M (2011) You are what you tweet: Analyzing Twitter for public health. In: Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media (ICWSM). pp. 265–272.
-
- Bollen J, Pepe A, Mao H (2009). Modeling public mood and emotion: Twitter sentiment and socio-economic phenomena.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
