

New York State TrueAllele ® casework validation study
- PMID: 23865896
- PMCID: PMC4283980
- DOI: 10.1111/1556-4029.12223
New York State TrueAllele ® casework validation study
Abstract
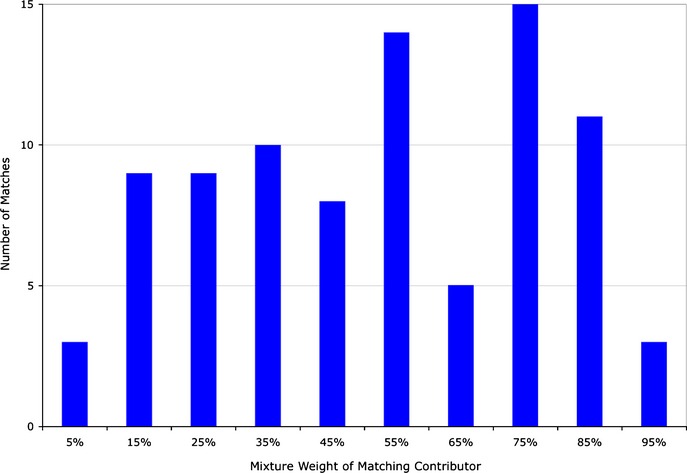
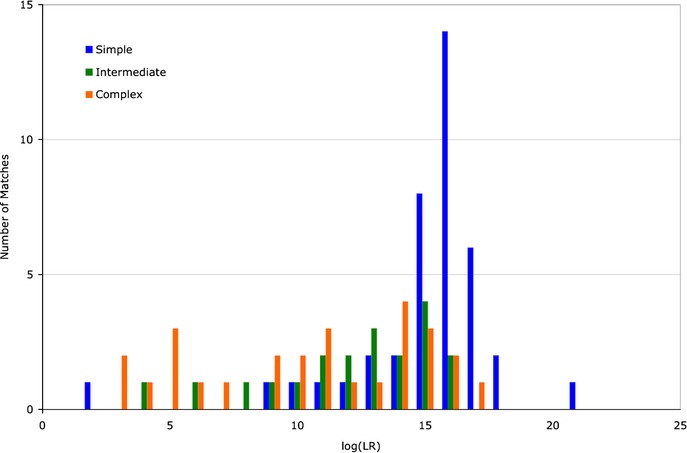
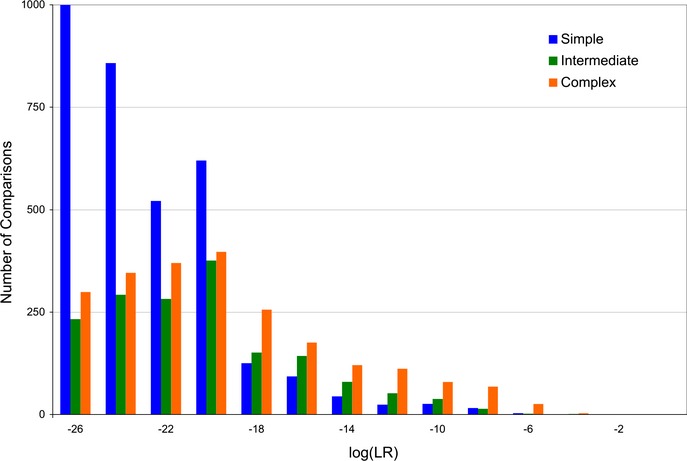
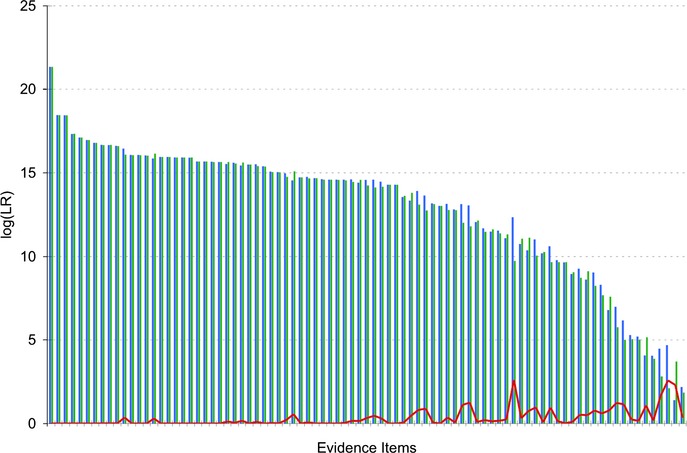
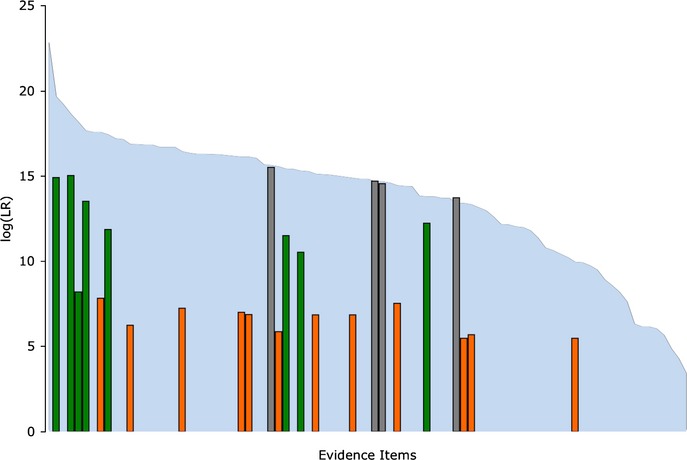
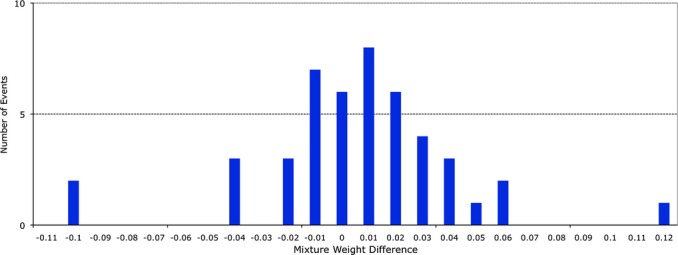
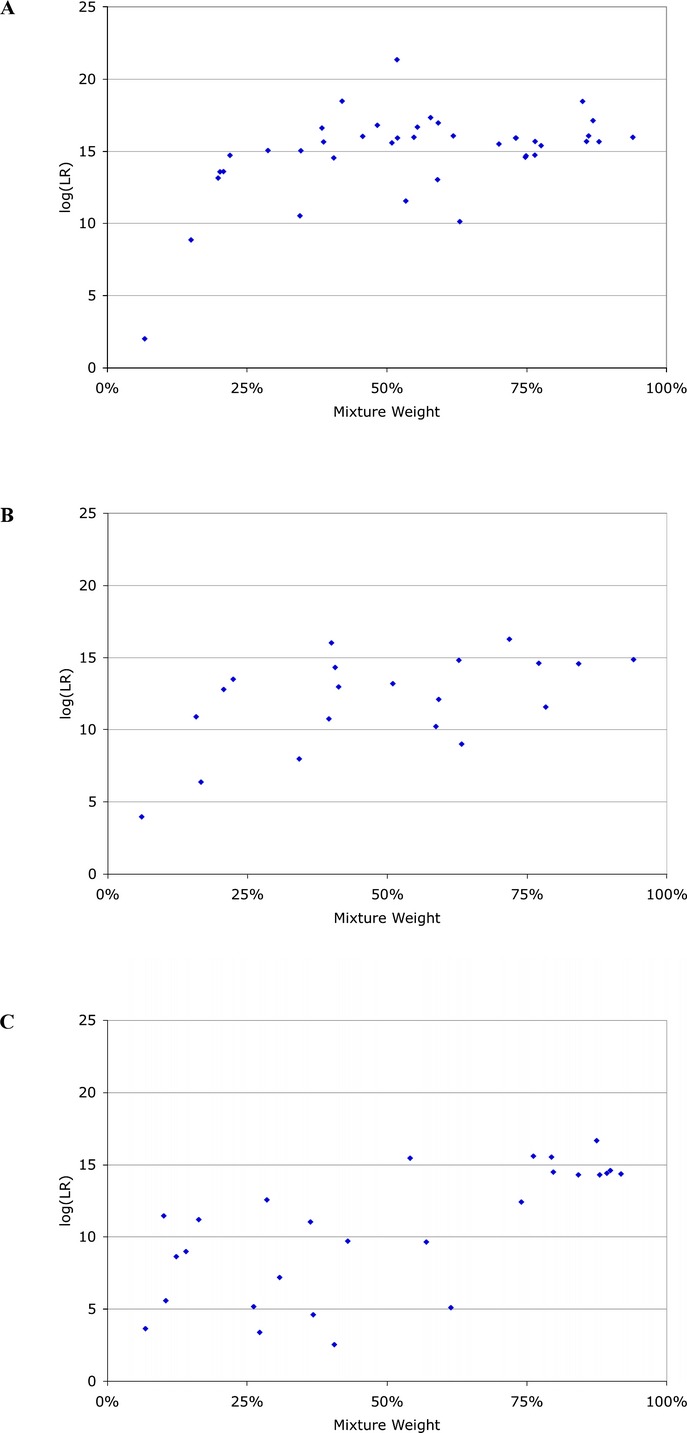
DNA evidence can pose interpretation challenges, particularly with low-level or mixed samples. It would be desirable to make full use of the quantitative data, consider every genotype possibility, and objectively produce accurate and reproducible DNA match results. Probabilistic genotype computing is designed to achieve these goals. This validation study assessed TrueAllele(®) probabilistic computer interpretation on 368 evidence items in 41 test cases and compared the results with human review of the same data. Whenever there was a human result, the computer's genotype was concordant. Further, the computer produced a match statistic on 81 mixture items (for 87 inferred matching genotypes) in the test cases, while human review reported a statistic on 25 of these items (30.9%). Using match statistics to quantify information, probabilistic genotyping was shown to be sensitive, specific, and reproducible. These results demonstrate that objective probabilistic genotyping of biological evidence can reliably preserve DNA identification information.
Keywords: DNA evidence; developmental validation; forensic science; identification information; likelihood ratio; mixture interpretation; probabilistic genotype.
© 2013 The Authors. Journal of Forensic Sciences published by Wiley Periodicals, Inc. on behalf of American Academy of Forensic Sciences.
Figures
References
-
- Faigman DL, Kaye DH, Saks MJ, Sanders J. Science in the law: forensic science issues. St. Paul, MN: West Group; 2002.
-
- Butler JM. Forensic DNA typing: biology, technology, and genetics of STR markers. 2. New York, NY: Academic Press; 2005.
-
- Kadash K, Kozlowski BE, Biega LA, Duceman BW. Validation study of the TrueAllele® automated data review system. J Forensic Sci. 2004;49(4):1–8. - PubMed
-
- Perlin MW, Legler MM, Spencer CE, Smith JL, Allan WP, Belrose JL, et al. Validating TrueAllele® DNA mixture interpretation. J Forensic Sci. 2011;56(6):1430–47. - PubMed
-
- Curran JM, Buckleton J. Inclusion probabilities and dropout. J Forensic Sci. 2010;55(5):1171–3. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
