

MACOP modular architecture with control primitives
- PMID: 23888140
- PMCID: PMC3719035
- DOI: 10.3389/fncom.2013.00099
MACOP modular architecture with control primitives
Abstract
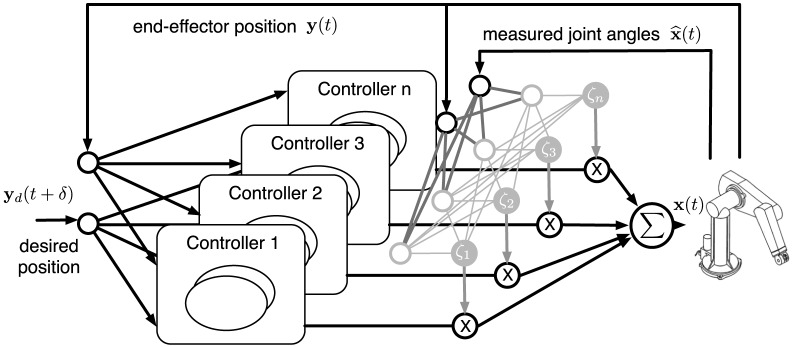
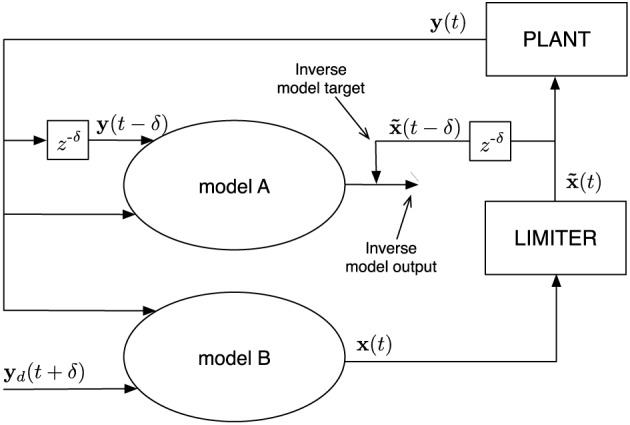
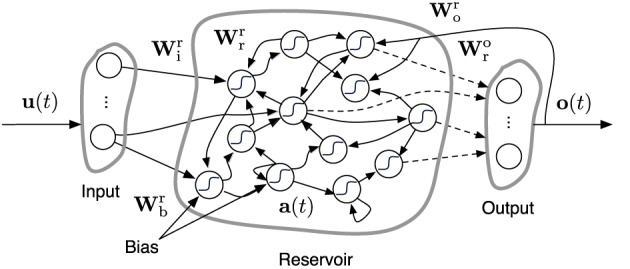
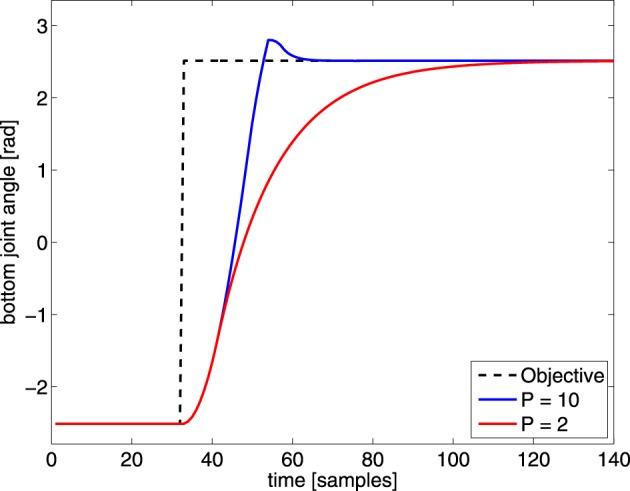
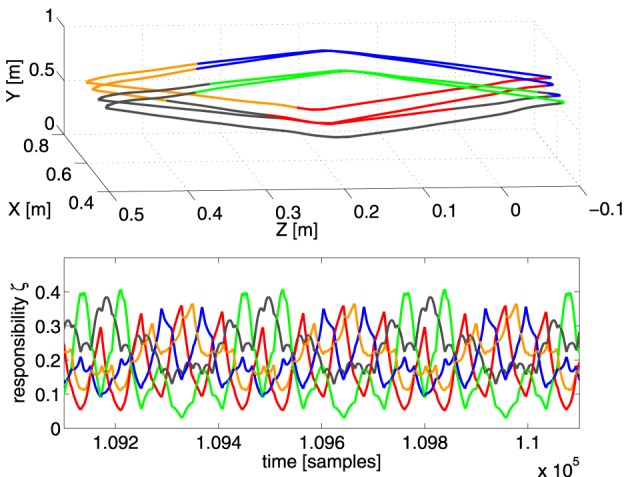
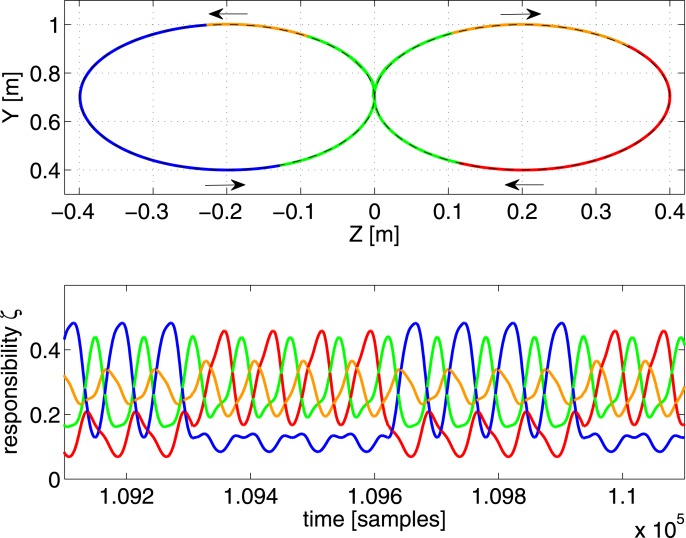
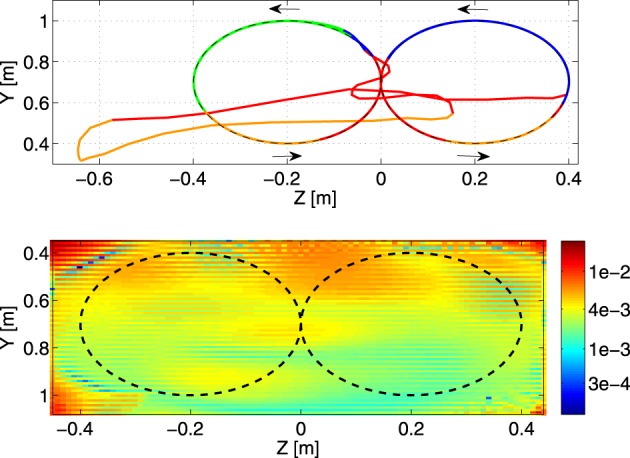
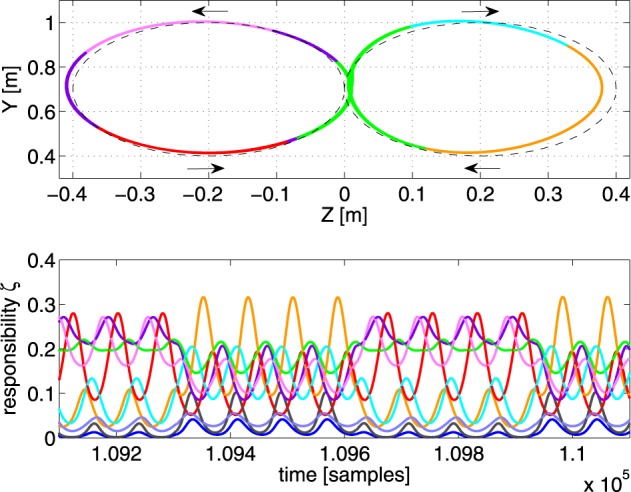
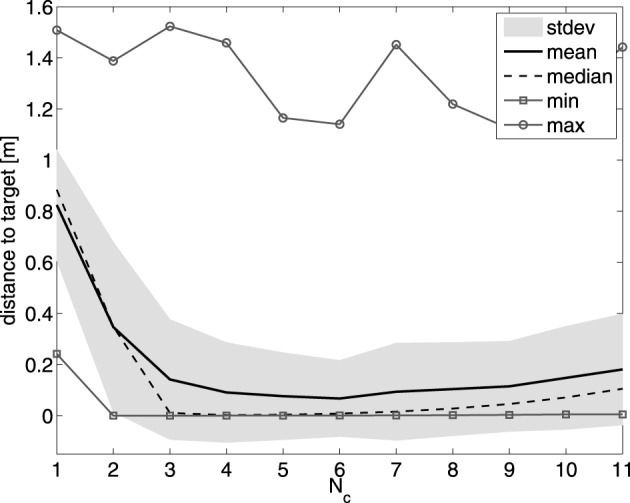
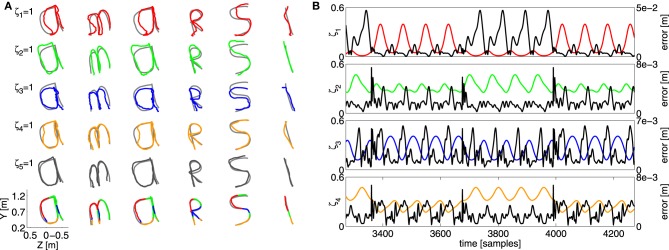
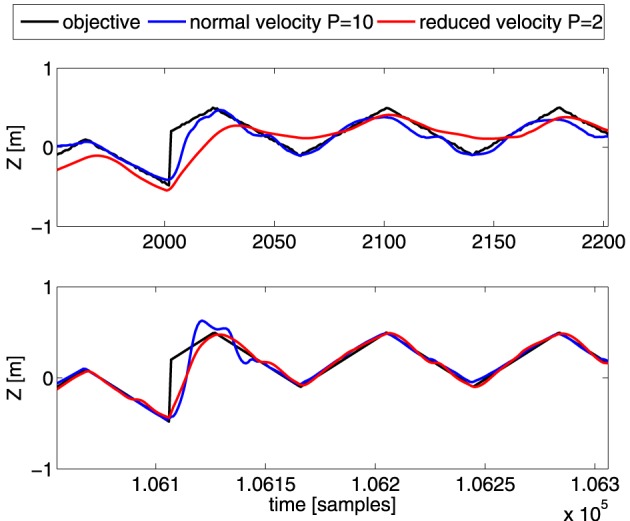
Walking, catching a ball and reaching are all tasks in which humans and animals exhibit advanced motor skills. Findings in biological research concerning motor control suggest a modular control hierarchy which combines movement/motor primitives into complex and natural movements. Engineers inspire their research on these findings in the quest for adaptive and skillful control for robots. In this work we propose a modular architecture with control primitives (MACOP) which uses a set of controllers, where each controller becomes specialized in a subregion of its joint and task-space. Instead of having a single controller being used in this subregion [such as MOSAIC (modular selection and identification for control) on which MACOP is inspired], MACOP relates more to the idea of continuously mixing a limited set of primitive controllers. By enforcing a set of desired properties on the mixing mechanism, a mixture of primitives emerges unsupervised which successfully solves the control task. We evaluate MACOP on a numerical model of a robot arm by training it to generate desired trajectories. We investigate how the tracking performance is affected by the number of controllers in MACOP and examine how the individual controllers and their generated control primitives contribute to solving the task. Furthermore, we show how MACOP compensates for the dynamic effects caused by a fixed control rate and the inertia of the robot.
Keywords: MOSAIC; echo state networks; motor control; motor primitives; movement primitives; reservoir computing; robot control.
Figures
References
-
- Bernstein N. A. (1967). The problem of interrelation of co-ordination and localization, in The Co-ordination and Regulation of Movements (New York, NY: Pergamon Press; ), 15–59
-
- Bishop C. M., Nasrabadi N. M. (2006). Pattern Recognition and Machine Learning. Vol. 1 New York, NY: Springer
LinkOut - more resources
Full Text Sources
Other Literature Sources