

Vicarious neural processing of outcomes during observational learning
- PMID: 24040104
- PMCID: PMC3764021
- DOI: 10.1371/journal.pone.0073879
Vicarious neural processing of outcomes during observational learning
Abstract
Learning what behaviour is appropriate in a specific context by observing the actions of others and their outcomes is a key constituent of human cognition, because it saves time and energy and reduces exposure to potentially dangerous situations. Observational learning of associative rules relies on the ability to map the actions of others onto our own, process outcomes, and combine these sources of information. Here, we combined newly developed experimental tasks and functional magnetic resonance imaging (fMRI) to investigate the neural mechanisms that govern such observational learning. Results show that the neural systems involved in individual trial-and-error learning and in action observation and execution both participate in observational learning. In addition, we identified brain areas that specifically activate for others' incorrect outcomes during learning in the posterior medial frontal cortex (pMFC), the anterior insula and the posterior superior temporal sulcus (pSTS).
Conflict of interest statement
Figures
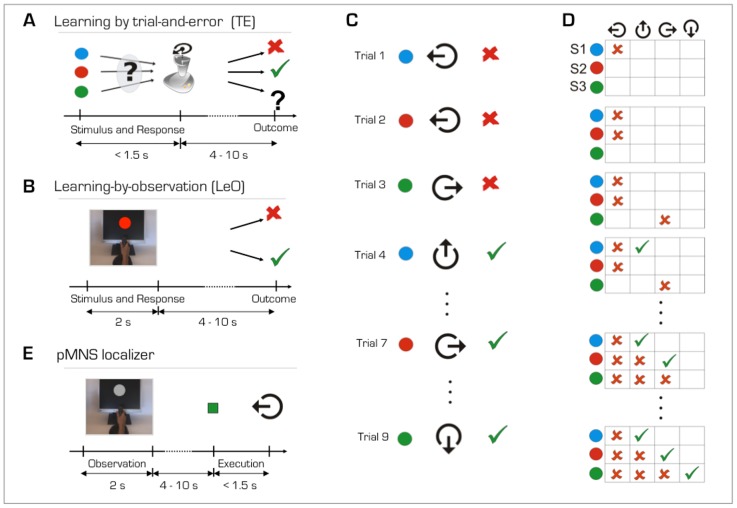
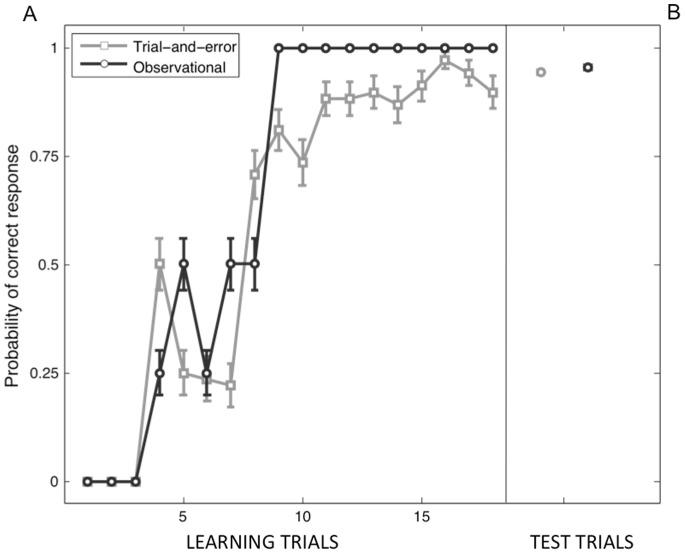
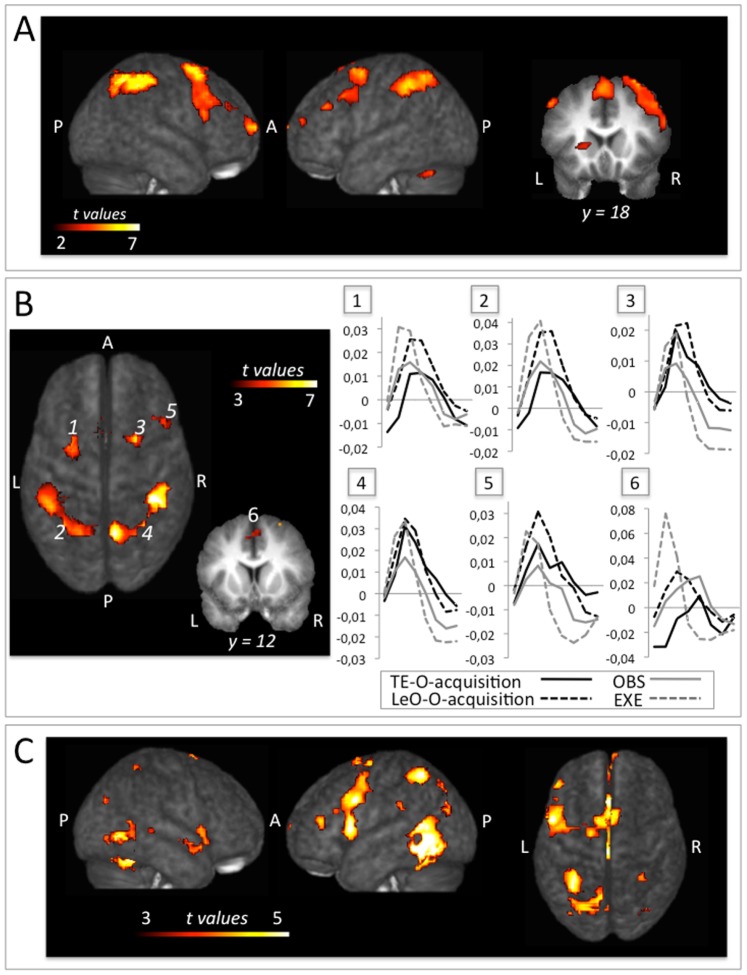
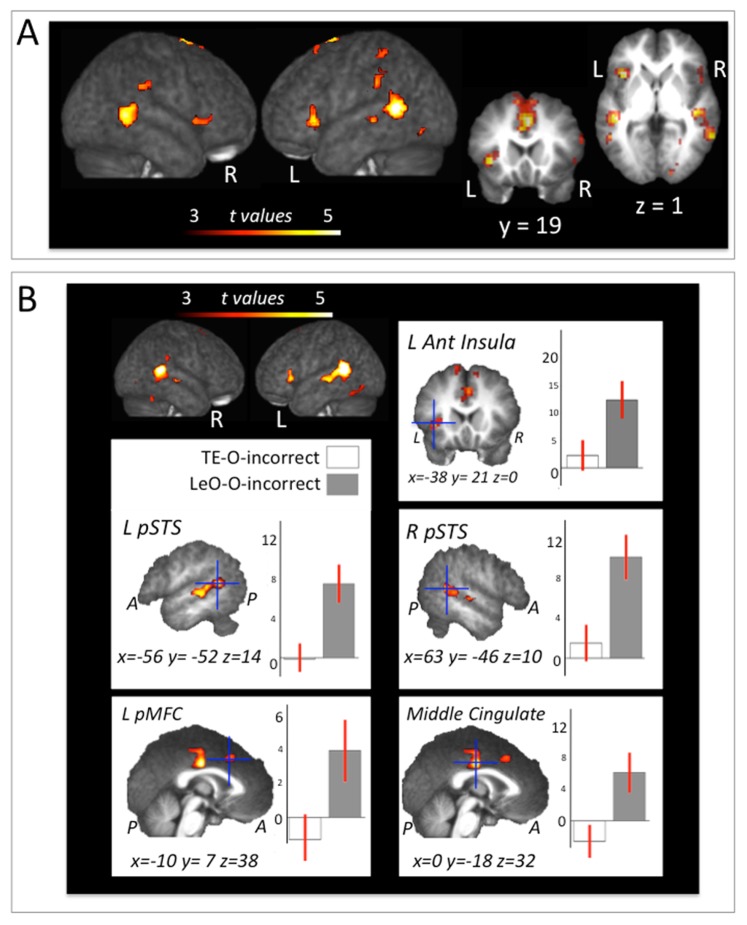
References
-
- Bandura A (1977) Social learning theory. Englewood Cliffs (NJ): Prentice-Hall.
-
- Frith CD, Frith U (2010) Mechanisms of Social Cognition. Annu Rev Psychol 63: 287–313. - PubMed
-
- Galef BG, Laland KN (2005) Social learning in animals: empirical studies and theoretical models. Bio Sci 55: 489–499.
-
- Heyes CM, Dawson GR (1990) A demonstration of observational learning in rats using a bidirectional control. Q J Exp Psychol B 42: 59–71. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
