

Statistical design for biospecimen cohort size in proteomics-based biomarker discovery and verification studies
- PMID: 24063748
- PMCID: PMC4039197
- DOI: 10.1021/pr400132j
Statistical design for biospecimen cohort size in proteomics-based biomarker discovery and verification studies
Abstract
Protein biomarkers are needed to deepen our understanding of cancer biology and to improve our ability to diagnose, monitor, and treat cancers. Important analytical and clinical hurdles must be overcome to allow the most promising protein biomarker candidates to advance into clinical validation studies. Although contemporary proteomics technologies support the measurement of large numbers of proteins in individual clinical specimens, sample throughput remains comparatively low. This problem is amplified in typical clinical proteomics research studies, which routinely suffer from a lack of proper experimental design, resulting in analysis of too few biospecimens to achieve adequate statistical power at each stage of a biomarker pipeline. To address this critical shortcoming, a joint workshop was held by the National Cancer Institute (NCI), National Heart, Lung, and Blood Institute (NHLBI), and American Association for Clinical Chemistry (AACC) with participation from the U.S. Food and Drug Administration (FDA). An important output from the workshop was a statistical framework for the design of biomarker discovery and verification studies. Herein, we describe the use of quantitative clinical judgments to set statistical criteria for clinical relevance and the development of an approach to calculate biospecimen sample size for proteomic studies in discovery and verification stages prior to clinical validation stage. This represents a first step toward building a consensus on quantitative criteria for statistical design of proteomics biomarker discovery and verification research.
Figures
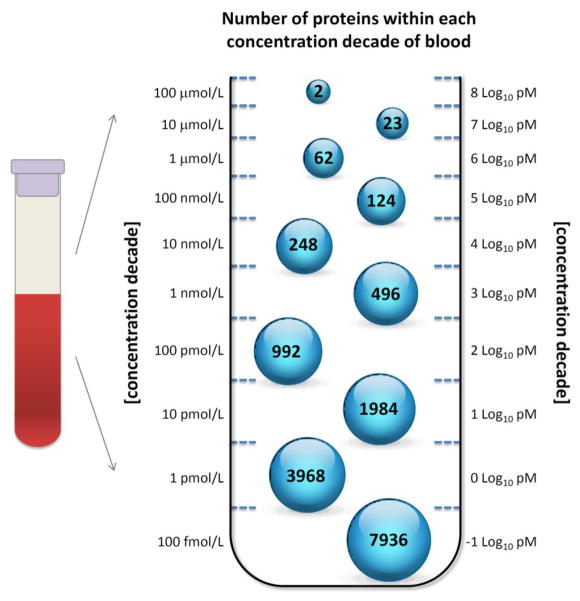
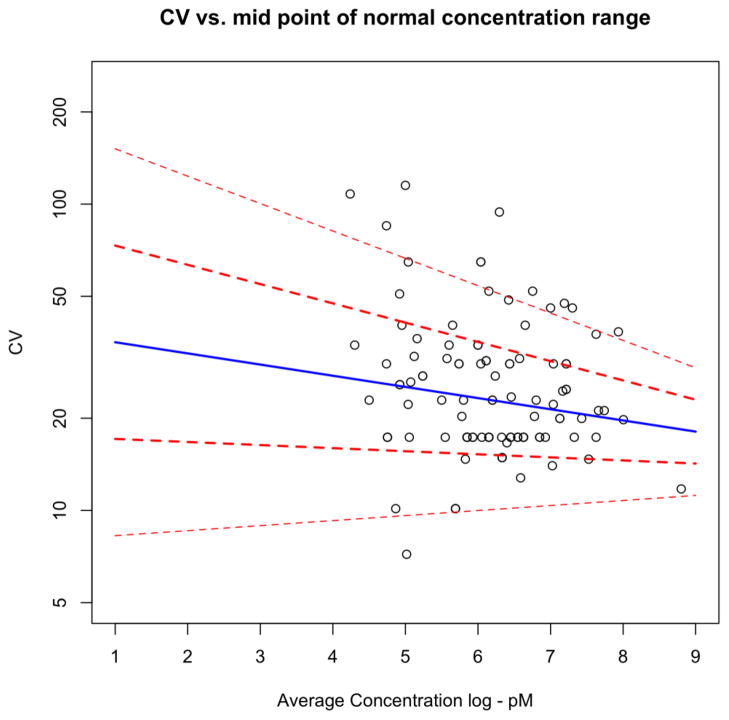
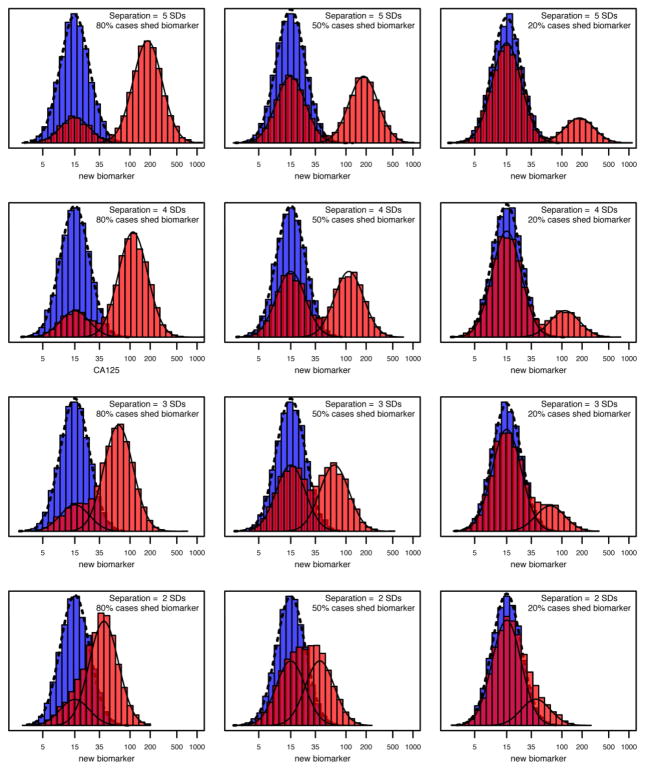
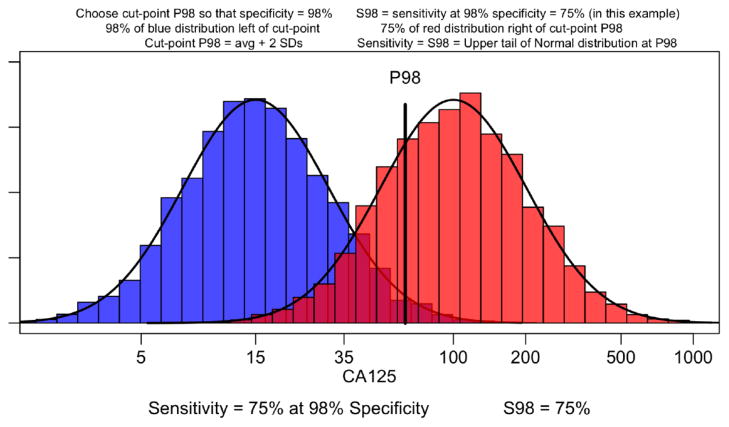
References
-
- Rifai N, Gillette MA, Carr SA. Protein biomarker discovery and validation: the long and uncertain path to clinical utility. Nat Biotechnol. 2006;24(8):971–983. - PubMed
-
- Regnier FE, Skates SJ, Mesri M, Rodriguez H, Tezak Z, Kondratovich MV, Alterman MA, Levin JD, Roscoe D, Reilly E, Callaghan J, Kelm K, Brown D, Philip R, Carr SA, Liebler DC, Fisher SJ, Tempst P, Hiltke T, Kessler LG, Kinsinger CR, Ransohoff DF, Mansfield E, Anderson NL. Protein-Based Multiplex Assays: Mock Presubmissions to the US Food and Drug Administration. Clin Chem. 2010;56(2):165–171. - PubMed
-
- Rodriguez H, Tezak Z, Mesri M, Carr SA, Liebler DC, Fisher SJ, Tempst P, Hiltke T, Kessler LG, Kinsinger CR, Philip R, Ransohoff DF, Skates SJ, Regnier FE, Anderson NL, Mansfield E. Workshop Participants. Analytical Validation of Protein-Based Multiplex Assays: A Workshop Report by the NCI-FDA Interagency Oncology Task Force on Molecular Diagnostics. Clin Chem. 2010;56(2):237–243. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
