

Neural model for learning-to-learn of novel task sets in the motor domain
- PMID: 24155736
- PMCID: PMC3804924
- DOI: 10.3389/fpsyg.2013.00771
Neural model for learning-to-learn of novel task sets in the motor domain
Abstract
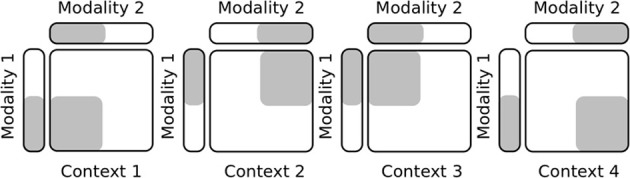
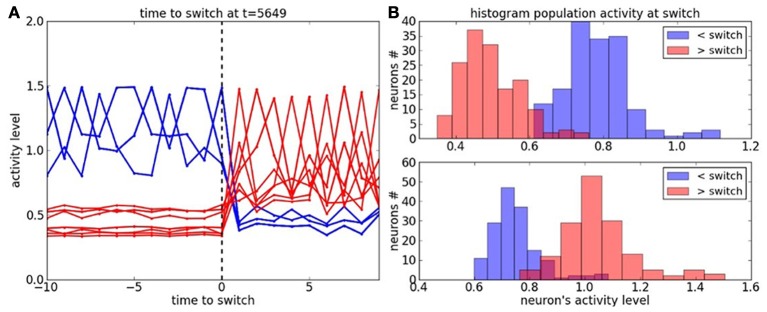
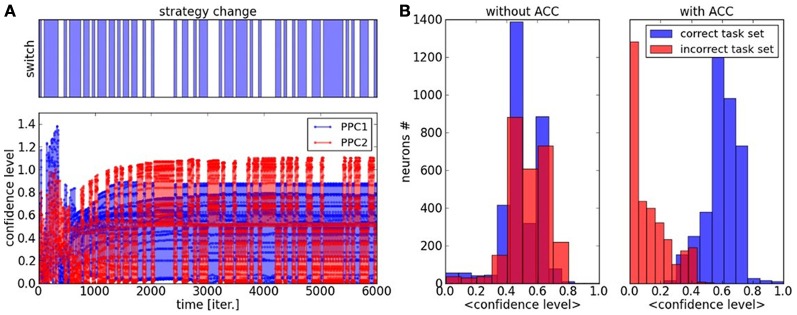
During development, infants learn to differentiate their motor behaviors relative to various contexts by exploring and identifying the correct structures of causes and effects that they can perform; these structures of actions are called task sets or internal models. The ability to detect the structure of new actions, to learn them and to select on the fly the proper one given the current task set is one great leap in infants cognition. This behavior is an important component of the child's ability of learning-to-learn, a mechanism akin to the one of intrinsic motivation that is argued to drive cognitive development. Accordingly, we propose to model a dual system based on (1) the learning of new task sets and on (2) their evaluation relative to their uncertainty and prediction error. The architecture is designed as a two-level-based neural system for context-dependent behavior (the first system) and task exploration and exploitation (the second system). In our model, the task sets are learned separately by reinforcement learning in the first network after their evaluation and selection in the second one. We perform two different experimental setups to show the sensorimotor mapping and switching between tasks, a first one in a neural simulation for modeling cognitive tasks and a second one with an arm-robot for motor task learning and switching. We show that the interplay of several intrinsic mechanisms drive the rapid formation of the neural populations with respect to novel task sets.
Keywords: cortical plasticity; decision making; error-reward processing; fronto-parietal system; gain-field mechanism; incremental learning; task sets; tool-use.
Figures












Similar articles
-
Neural systems underlying the learning of cognitive effort costs.Cogn Affect Behav Neurosci. 2021 Aug;21(4):698-716. doi: 10.3758/s13415-021-00893-x. Epub 2021 May 7. Cogn Affect Behav Neurosci. 2021. PMID: 33959895
-
Reward-dependent learning in neuronal networks for planning and decision making.Prog Brain Res. 2000;126:217-29. doi: 10.1016/S0079-6123(00)26016-0. Prog Brain Res. 2000. PMID: 11105649 Review.
-
How we learn to make decisions: rapid propagation of reinforcement learning prediction errors in humans.J Cogn Neurosci. 2014 Mar;26(3):635-44. doi: 10.1162/jocn_a_00509. Epub 2013 Oct 29. J Cogn Neurosci. 2014. PMID: 24168216
-
Learning a Set of Interrelated Tasks by Using a Succession of Motor Policies for a Socially Guided Intrinsically Motivated Learner.Front Neurorobot. 2019 Jan 8;12:87. doi: 10.3389/fnbot.2018.00087. eCollection 2018. Front Neurorobot. 2019. PMID: 30670961 Free PMC article.
-
The role of prediction and outcomes in adaptive cognitive control.J Physiol Paris. 2015 Feb-Jun;109(1-3):38-52. doi: 10.1016/j.jphysparis.2015.02.001. Epub 2015 Feb 17. J Physiol Paris. 2015. PMID: 25698177 Review.
Cited by
-
Iterative free-energy optimization for recurrent neural networks (INFERNO).PLoS One. 2017 Mar 10;12(3):e0173684. doi: 10.1371/journal.pone.0173684. eCollection 2017. PLoS One. 2017. PMID: 28282439 Free PMC article.
-
Brain-inspired model for early vocal learning and correspondence matching using free-energy optimization.PLoS Comput Biol. 2021 Feb 18;17(2):e1008566. doi: 10.1371/journal.pcbi.1008566. eCollection 2021 Feb. PLoS Comput Biol. 2021. PMID: 33600482 Free PMC article.
-
Intrinsic motivations and open-ended development in animals, humans, and robots: an overview.Front Psychol. 2014 Sep 9;5:985. doi: 10.3389/fpsyg.2014.00985. eCollection 2014. Front Psychol. 2014. PMID: 25249998 Free PMC article. No abstract available.
References
-
- Adolph K., Joh A. (2005). Multiple learning mechanisms in the development of action, in Paper presented to the Conference on Motor Development and Learning. Vol. 33, eds Lockman J., Reiser J., Nelson C. A. (Murcia: ).
-
- Adolph K., Joh A. (2009). Multiple Learning Mechanisms in the Development of Action. New York, NY: Oxford University Press
LinkOut - more resources
Full Text Sources
Other Literature Sources