

Identifying influential nodes in large-scale directed networks: the role of clustering
- PMID: 24204833
- PMCID: PMC3814409
- DOI: 10.1371/journal.pone.0077455
Identifying influential nodes in large-scale directed networks: the role of clustering
Abstract
Identifying influential nodes in very large-scale directed networks is a big challenge relevant to disparate applications, such as accelerating information propagation, controlling rumors and diseases, designing search engines, and understanding hierarchical organization of social and biological networks. Known methods range from node centralities, such as degree, closeness and betweenness, to diffusion-based processes, like PageRank and LeaderRank. Some of these methods already take into account the influences of a node's neighbors but do not directly make use of the interactions among it's neighbors. Local clustering is known to have negative impacts on the information spreading. We further show empirically that it also plays a negative role in generating local connections. Inspired by these facts, we propose a local ranking algorithm named ClusterRank, which takes into account not only the number of neighbors and the neighbors' influences, but also the clustering coefficient. Subject to the susceptible-infected-recovered (SIR) spreading model with constant infectivity, experimental results on two directed networks, a social network extracted from delicious.com and a large-scale short-message communication network, demonstrate that the ClusterRank outperforms some benchmark algorithms such as PageRank and LeaderRank. Furthermore, ClusterRank can also be applied to undirected networks where the superiority of ClusterRank is significant compared with degree centrality and k-core decomposition. In addition, ClusterRank, only making use of local information, is much more efficient than global methods: It takes only 191 seconds for a network with about [Formula: see text] nodes, more than 15 times faster than PageRank.
Conflict of interest statement
Figures
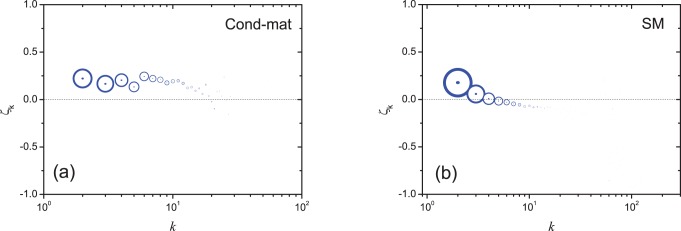
 is the average value of a bin (size = 0.1) on clustering coefficient. For example, the value of
is the average value of a bin (size = 0.1) on clustering coefficient. For example, the value of  corresponding to
corresponding to  is the average value of
is the average value of  of the nodes with clustering coefficient in
of the nodes with clustering coefficient in  . The error bars stand for standard errors.
. The error bars stand for standard errors.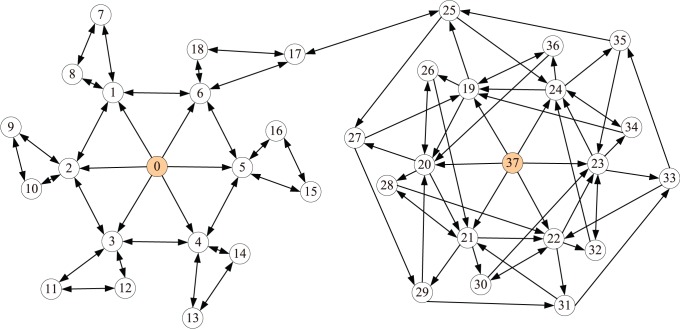
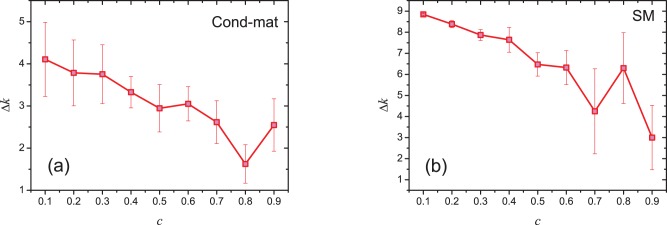
 and
and  .
.
 and
and  . Each data point is obtained by averaging over 100 independent runs.
. Each data point is obtained by averaging over 100 independent runs.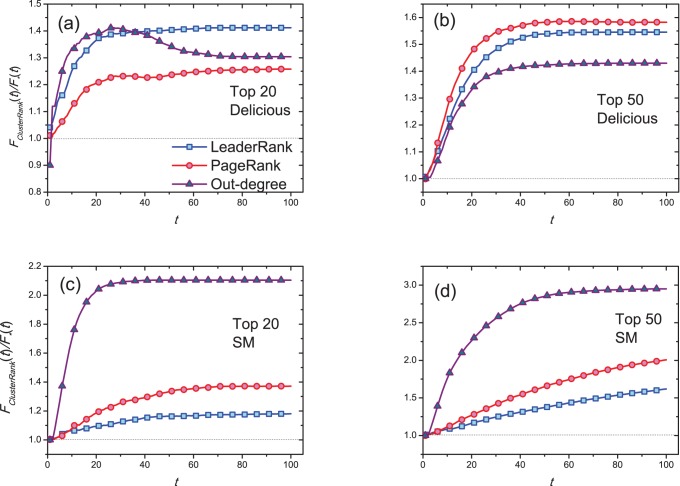
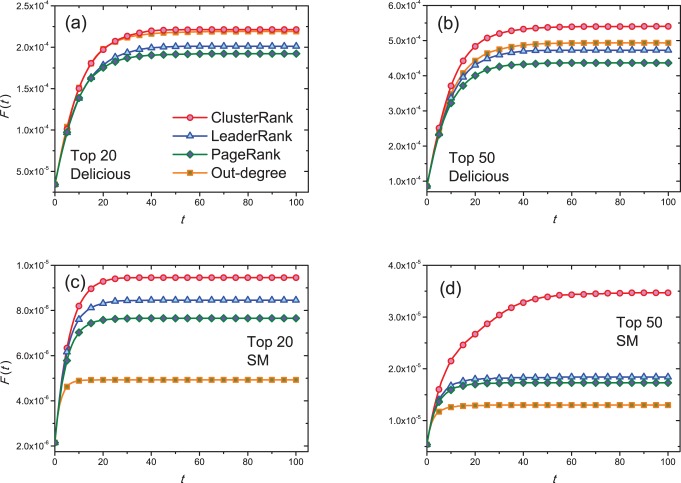
 lists obtained by ClusterRank and other ranking algorithms are set to be infected. We set
lists obtained by ClusterRank and other ranking algorithms are set to be infected. We set  and
and  . Each data point is obtained by averaging over 100 independent runs.
. Each data point is obtained by averaging over 100 independent runs.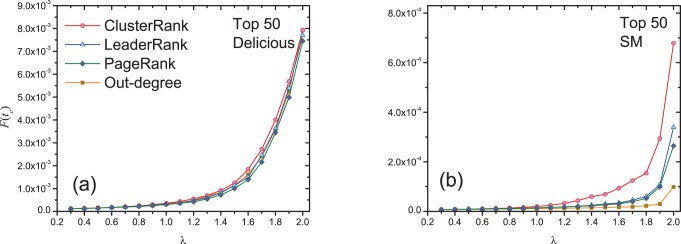
 . Each data point is obtained by averaging over 100 independent runs.
. Each data point is obtained by averaging over 100 independent runs.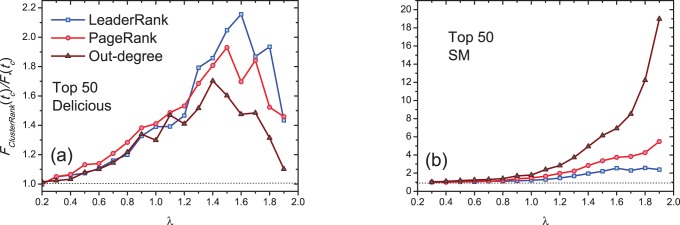
 . Each data point is obtained by averaging over 100 independent runs.
. Each data point is obtained by averaging over 100 independent runs.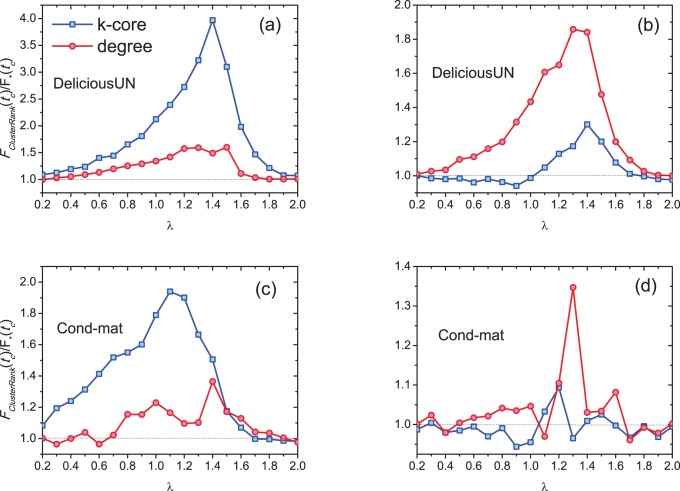
References
-
- Pastor-Satorras R, Vespiggnani A (2001) Epidemic spreading in scale-free networks. Phys Rev Lett 86: 3200–3203. - PubMed
-
- Zhou T, Fu ZQ, Wang BH (2006) Epidemic dynamics on complex networks. Prog Nat Sci 16: 452–457.
-
- Vespiggnani A (2012) Modelling dynamical processes in complex socio-technical systems. Nat Phys 8: 32–39.
-
- Barrat A, Barthlemy M, Vespignani A (2008) Dynamical processes on complex networks. Cambridge University Press.
-
- Yang HX, Wang WX, Lai YC, Xie YB, Wang BH (2011) Control of epidemic spreading on complex networks by local traffic dynamics. Phys Rev E 84: 045101. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
