

Drug repositioning by kernel-based integration of molecular structure, molecular activity, and phenotype data
- PMID: 24244318
- PMCID: PMC3823875
- DOI: 10.1371/journal.pone.0078518
Drug repositioning by kernel-based integration of molecular structure, molecular activity, and phenotype data
Erratum in
- PLoS One. 2013;8(12). doi:10.1371/annotation/fe02e998-6a38-4fd7-9df6-241bc4d0f267
Abstract
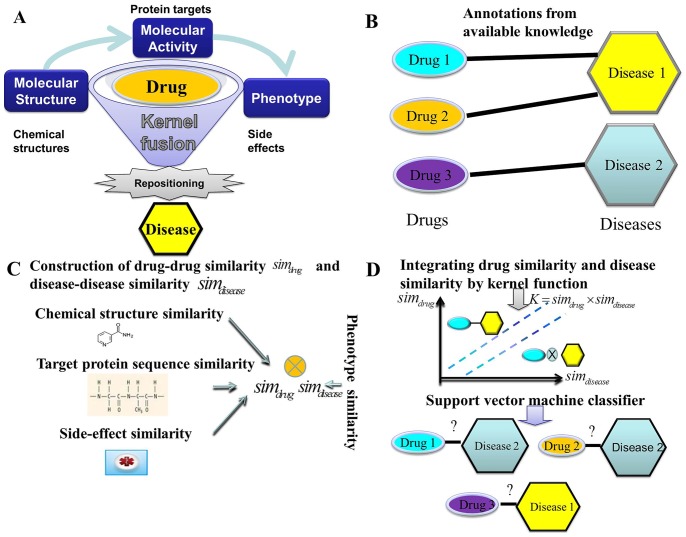
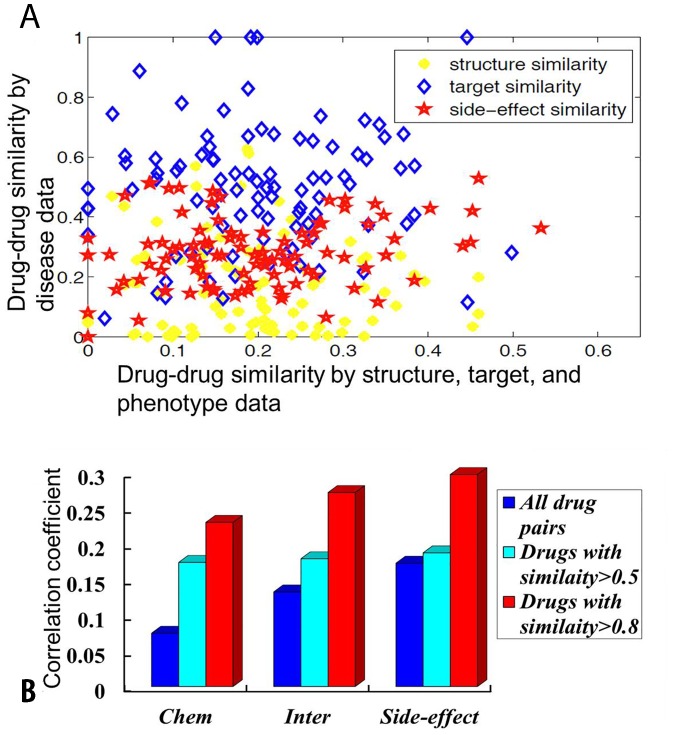
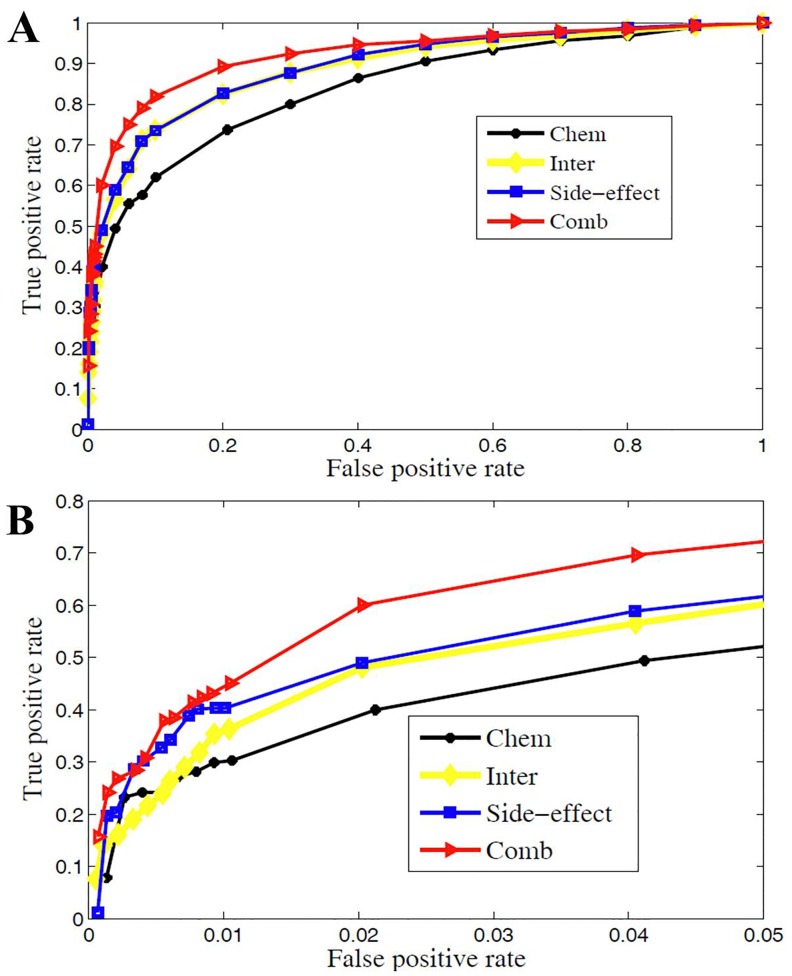
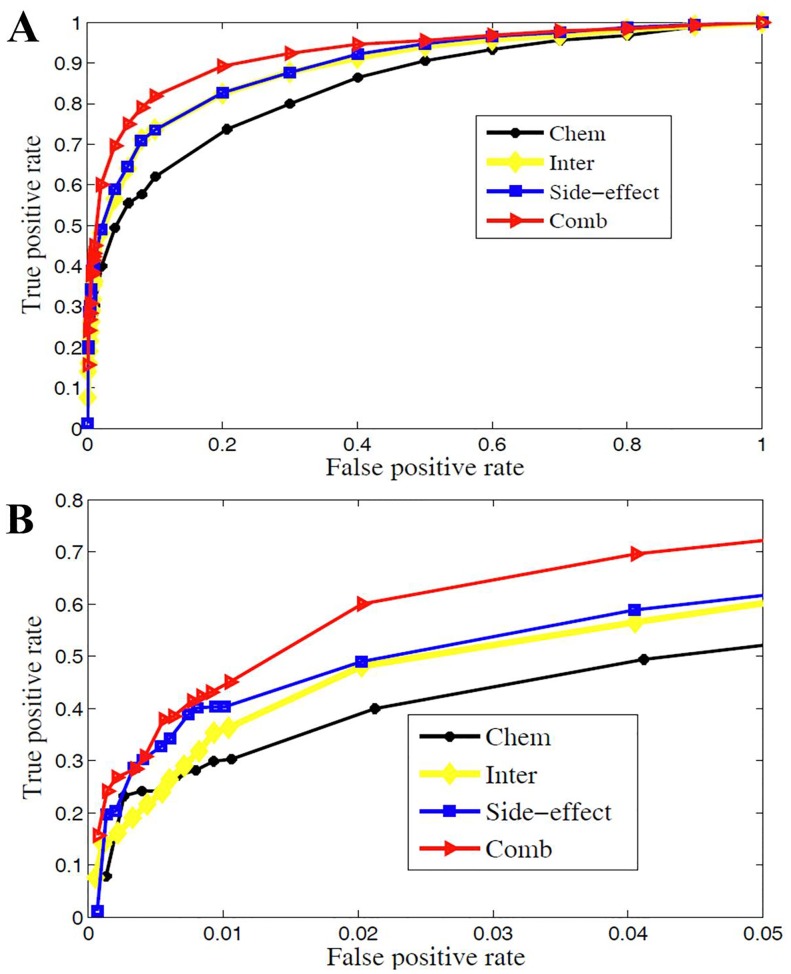
Computational inference of novel therapeutic values for existing drugs, i.e., drug repositioning, offers the great prospect for faster and low-risk drug development. Previous researches have indicated that chemical structures, target proteins, and side-effects could provide rich information in drug similarity assessment and further disease similarity. However, each single data source is important in its own way and data integration holds the great promise to reposition drug more accurately. Here, we propose a new method for drug repositioning, PreDR (Predict Drug Repositioning), to integrate molecular structure, molecular activity, and phenotype data. Specifically, we characterize drug by profiling in chemical structure, target protein, and side-effects space, and define a kernel function to correlate drugs with diseases. Then we train a support vector machine (SVM) to computationally predict novel drug-disease interactions. PreDR is validated on a well-established drug-disease network with 1,933 interactions among 593 drugs and 313 diseases. By cross-validation, we find that chemical structure, drug target, and side-effects information are all predictive for drug-disease relationships. More experimentally observed drug-disease interactions can be revealed by integrating these three data sources. Comparison with existing methods demonstrates that PreDR is competitive both in accuracy and coverage. Follow-up database search and pathway analysis indicate that our new predictions are worthy of further experimental validation. Particularly several novel predictions are supported by clinical trials databases and this shows the significant prospects of PreDR in future drug treatment. In conclusion, our new method, PreDR, can serve as a useful tool in drug discovery to efficiently identify novel drug-disease interactions. In addition, our heterogeneous data integration framework can be applied to other problems.
Conflict of interest statement
Figures
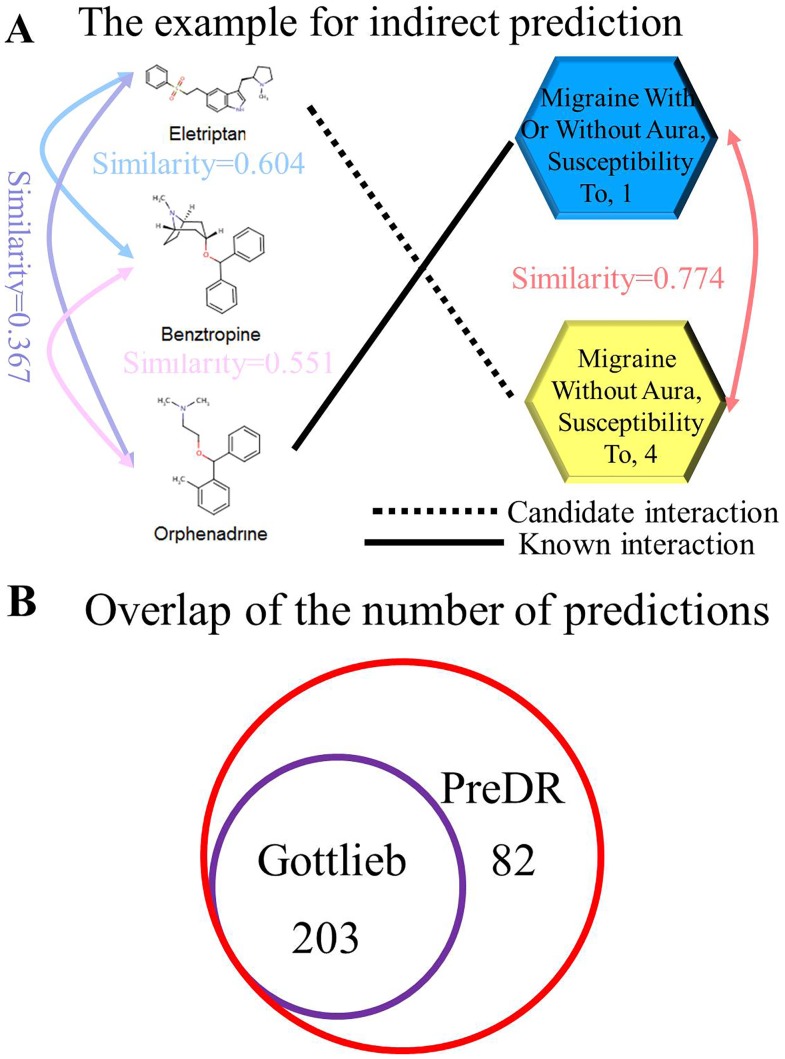
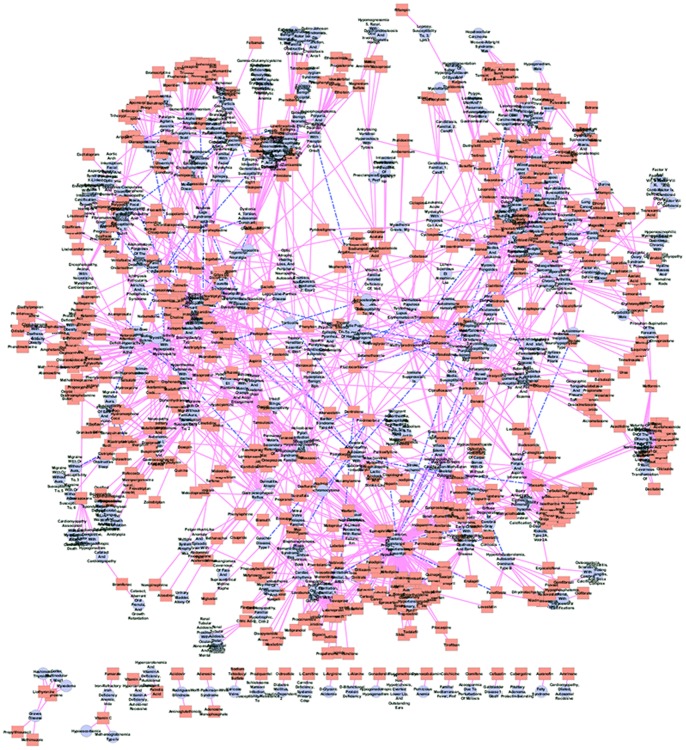
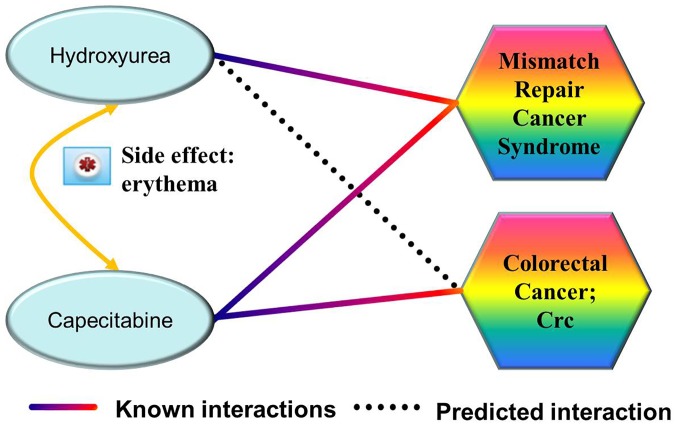
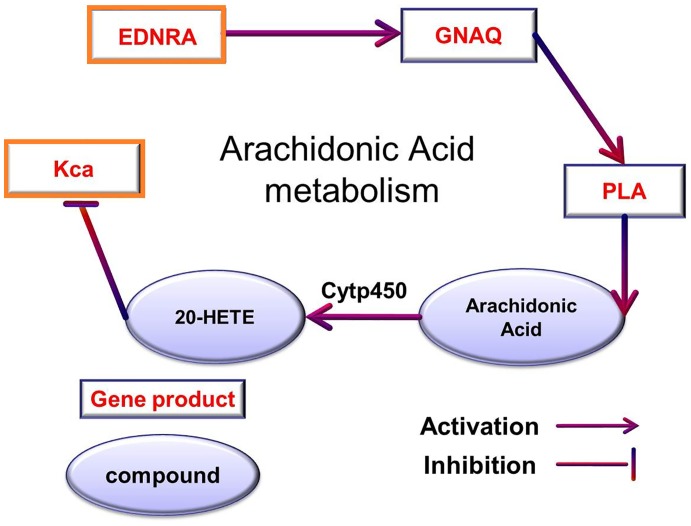
References
-
- DiMasi JA, Hansen RW, Grabowski HG (2003) The price of innovation: new estimates of drug development costs. J Health Econ 22: 151–185. - PubMed
-
- Kotelnikova E, Yuryev A, Mazo I, Daraselia N (2010) Computational approaches for drug repositioning and combination therapy design. J Bioinform Comput Biol 8: 593–606. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
